Can an LLM Induce a Graph? Investigating Memory Drift and Context Length
作者: Raquib Bin Yousuf, Aadyant Khatri, Shengzhe Xu, Mandar Sharma, Naren Ramakrishnan
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-10-04
备注: 2025 IEEE International Conference on Knowledge Graph (ICKG)
💡 一句话要点
提出基于图诱导的LLM评估方法,揭示其在关系推理中更早出现的记忆漂移问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 上下文长度 记忆漂移 关系推理 图诱导
📋 核心要点
- 现有LLM评估基准依赖简单检索任务,无法准确反映模型在信息密集场景下的性能。
- 论文提出通过图诱导任务评估LLM,考察其从长文本中提取关系结构的能力。
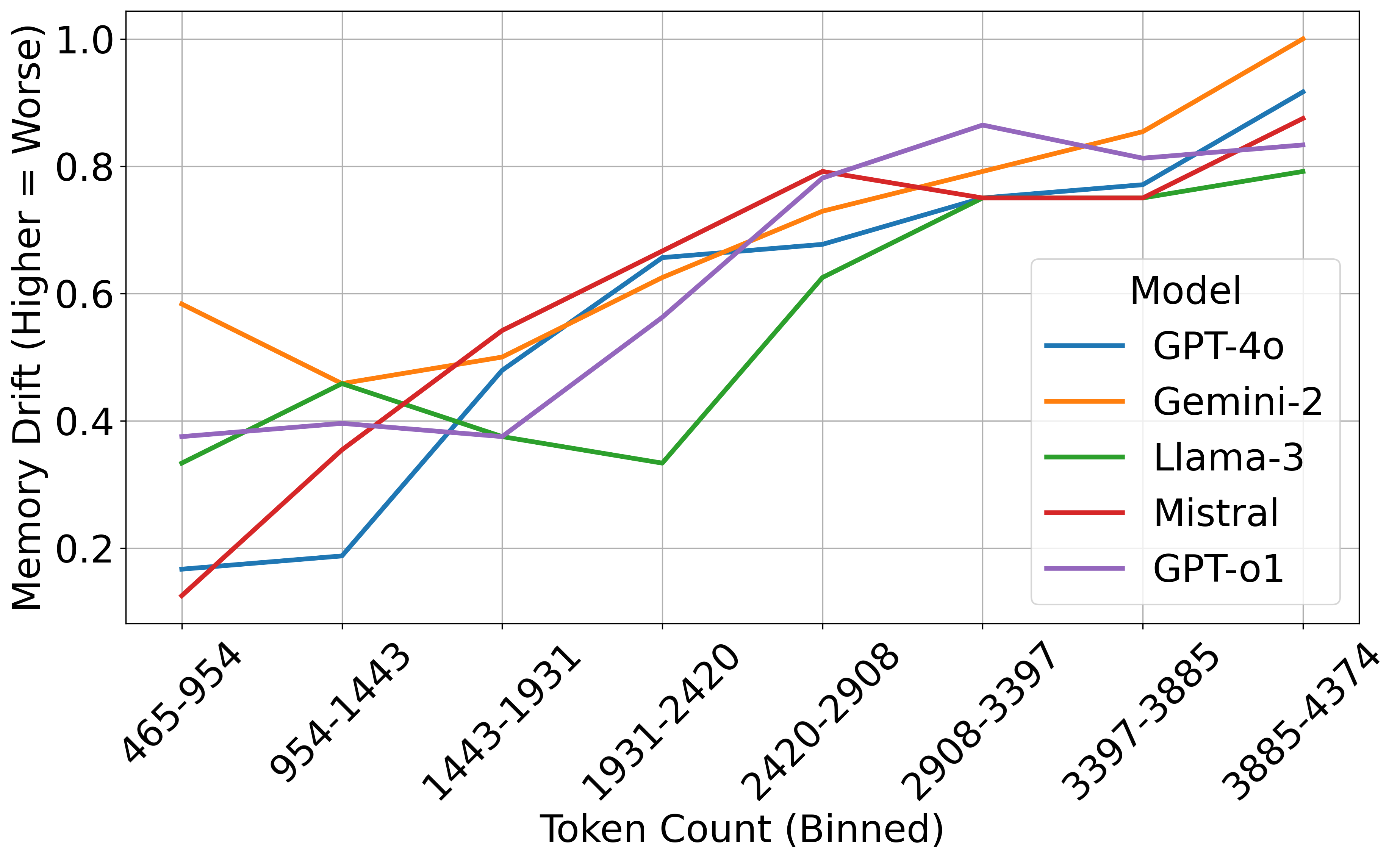
- 实验表明,在关系推理任务中,LLM的记忆漂移现象比现有基准显示的更早出现。
📝 摘要(中文)
本文提出了一种新的评估基准,旨在更准确地评估大型语言模型(LLM)的有效上下文长度和遗忘倾向。与依赖于简单“大海捞针”式检索或续写任务的现有基准不同,本文主张在更复杂的推理任务上评估LLM,这些任务要求模型从文本中诱导结构化的关系知识,例如从潜在嘈杂的自然语言内容中提取图结构。研究结果表明,与现有基准测试相比,当LLM执行这种关系推理任务时,它们在更短的有效长度上就开始表现出记忆漂移和上下文遗忘。基于这些发现,本文为在复杂推理任务中优化使用流行的LLM提供了建议。进一步表明,即使是专门用于推理的模型,如OpenAI o1,在这种设置下仍然容易受到早期记忆漂移的影响。这些结果表明,模型从非结构化输入中提取结构化知识的能力存在重大局限性,并强调需要进行架构调整以改善长程推理。
🔬 方法详解
问题定义:现有评估LLM上下文长度和遗忘倾向的基准,如“大海捞针”,过于简单,无法真实反映LLM在复杂信息环境下的推理能力。这些基准通常侧重于检索或续写,忽略了LLM从长文本中提取和利用关系信息的能力。因此,需要一种更具挑战性的评估方法,能够考察LLM在处理复杂、非结构化信息时的推理能力。
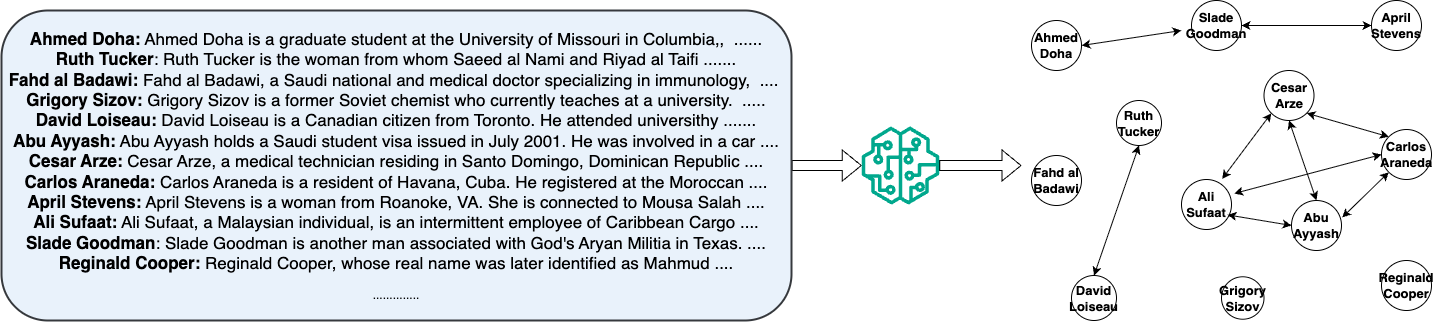
核心思路:论文的核心思路是通过图诱导任务来评估LLM。具体来说,给定一段包含实体和关系的文本,要求LLM从中提取实体和关系,并构建相应的图结构。这种任务需要LLM具备长程依赖建模能力,能够从分散在长文本中的线索中推断出实体之间的关系,从而更真实地反映LLM的推理能力和记忆保持能力。
技术框架:该评估框架包含以下几个关键步骤:1) 构建包含实体和关系的文本数据集,文本长度可变,并包含干扰信息;2) 使用LLM处理文本,并要求其输出图结构,例如实体列表和关系列表;3) 将LLM输出的图结构与真实图结构进行比较,使用诸如精确率、召回率和F1值等指标来评估LLM的性能。框架的关键在于设计合适的文本数据集,使其既能反映真实场景的复杂性,又能方便地评估LLM的推理结果。
关键创新:该论文的关键创新在于提出了一种基于图诱导的LLM评估方法。与传统的评估方法相比,该方法更侧重于考察LLM从非结构化文本中提取结构化知识的能力,更贴近LLM在实际应用中的需求。此外,该方法能够更敏感地检测LLM的记忆漂移现象,揭示了LLM在处理长文本时的局限性。
关键设计:在实验中,论文使用了不同大小和架构的LLM,包括通用LLM和专门用于推理的LLM。文本数据集包含不同长度的文本,并控制了实体和关系的数量以及干扰信息的比例。评估指标包括精确率、召回率和F1值,用于全面评估LLM在图诱导任务中的性能。此外,论文还分析了LLM在不同文本长度下的性能变化,以研究记忆漂移现象。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在图诱导任务中,LLM的记忆漂移现象比现有基准显示的更早出现。即使是专门用于推理的LLM,如OpenAI o1,也容易受到早期记忆漂移的影响。这表明LLM在从非结构化文本中提取结构化知识方面存在局限性,需要进一步改进。
🎯 应用场景
该研究成果可应用于评估和改进LLM在知识图谱构建、信息抽取、智能问答等领域的性能。通过图诱导任务,可以更有效地发现LLM在处理长文本和复杂关系时的不足,从而指导LLM的架构设计和训练策略,提升其在实际应用中的效果。此外,该评估方法也可以用于比较不同LLM的性能,为用户选择合适的LLM提供参考。
📄 摘要(原文)
Recently proposed evaluation benchmarks aim to characterize the effective context length and the forgetting tendencies of large language models (LLMs). However, these benchmarks often rely on simplistic 'needle in a haystack' retrieval or continuation tasks that may not accurately reflect the performance of these models in information-dense scenarios. Thus, rather than simple next token prediction, we argue for evaluating these models on more complex reasoning tasks that requires them to induce structured relational knowledge from the text - such as graphs from potentially noisy natural language content. While the input text can be viewed as generated in terms of a graph, its structure is not made explicit and connections must be induced from distributed textual cues, separated by long contexts and interspersed with irrelevant information. Our findings reveal that LLMs begin to exhibit memory drift and contextual forgetting at much shorter effective lengths when tasked with this form of relational reasoning, compared to what existing benchmarks suggest. With these findings, we offer recommendations for the optimal use of popular LLMs for complex reasoning tasks. We further show that even models specialized for reasoning, such as OpenAI o1, remain vulnerable to early memory drift in these settings. These results point to significant limitations in the models' ability to abstract structured knowledge from unstructured input and highlight the need for architectural adaptations to improve long-range reasoning.