Decoupling Task-Solving and Output Formatting in LLM Generation
作者: Haikang Deng, Po-Nien Kung, Nanyun Peng
分类: cs.CL
发布日期: 2025-10-04
💡 一句话要点
提出Deco-G框架,解耦LLM生成中的任务求解与格式化输出,提升复杂任务性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 格式化输出 任务解耦 概率模型 指令感知蒸馏
📋 核心要点
- 现有方法在复杂任务中,LLM难以同时满足任务求解和格式化输出的要求,两者相互干扰。
- Deco-G框架通过可处理概率模型(TPM)显式解耦格式遵循和任务求解,提升模型性能。
- 实验表明,Deco-G在数学推理、LLM-as-a-Judge等任务上,相比常规方法提升1.0%-6.0%。
📝 摘要(中文)
大型语言模型(LLM)在遵循指令解决复杂问题(如数学推理和自动评估)方面越来越出色。然而,随着提示变得更加复杂,模型常常难以遵守所有指令。当指令性提示将推理指令(指定模型应该解决什么)与严格的格式要求(规定解决方案的呈现方式)交织在一起时,这种困难尤其常见。这种纠缠为模型创造了相互竞争的目标,表明更明确地分离这两个方面可以提高性能。为此,我们引入了Deco-G,一个显式地将格式遵循与任务求解分离的解码框架。Deco-G使用单独的可处理概率模型(TPM)处理格式合规性,同时仅使用任务指令提示LLM。在每个解码步骤中,Deco-G将来自LLM的下一个token概率与TPM计算的格式合规性似然相结合,以形成输出概率。为了使这种方法对现代指令调整的LLM既实用又可扩展,我们引入了三个关键创新:指令感知蒸馏、灵活的trie构建算法和用于计算效率的HMM状态剪枝。我们证明了Deco-G在具有不同格式要求的各种任务中的有效性,包括数学推理、LLM-as-a-Judge和事件论元提取。总的来说,我们的方法比常规提示实践产生了1.0%到6.0%的相对增益,并保证了格式合规性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在复杂任务中,难以同时满足任务求解和严格格式化输出要求的问题。现有的prompting方法将任务描述和格式要求混合在一起,导致模型在两者之间难以权衡,影响性能。
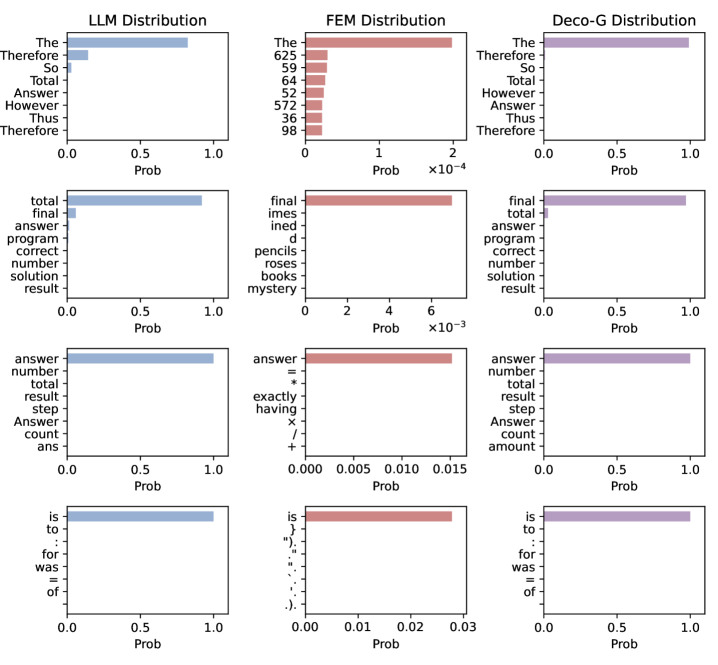
核心思路:论文的核心思路是将任务求解和格式化输出解耦。具体来说,使用LLM专注于任务求解,而使用一个单独的可处理概率模型(TPM)来保证输出的格式合规性。通过在解码过程中融合LLM的输出概率和TPM的格式合规性似然,实现两者的协同。
技术框架:Deco-G框架包含以下主要模块:1) LLM:负责根据任务指令生成文本。2) 可处理概率模型(TPM):负责建模输出格式的概率分布。3) 解码器:在每个解码步骤中,将LLM的输出概率和TPM的格式合规性似然相结合,生成最终的输出概率分布。框架通过指令感知蒸馏来训练TPM,使其能够理解任务指令并生成符合格式要求的文本。
关键创新:论文的关键创新在于:1) 显式解耦任务求解和格式化输出。2) 提出指令感知蒸馏方法,训练TPM。3) 提出灵活的trie构建算法和HMM状态剪枝方法,提高计算效率。与现有方法相比,Deco-G能够更有效地利用LLM的推理能力,同时保证输出的格式合规性。
关键设计:1) 指令感知蒸馏:使用LLM生成带有格式要求的文本,然后使用这些文本来训练TPM。2) 灵活的trie构建算法:根据任务的格式要求,动态构建trie树,用于计算格式合规性似然。3) HMM状态剪枝:在解码过程中,剪枝掉概率较低的HMM状态,提高计算效率。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Deco-G在数学推理、LLM-as-a-Judge和事件论元提取等任务上,相比常规prompting方法,取得了显著的性能提升。具体来说,Deco-G在这些任务上分别获得了1.0%到6.0%的相对增益,同时保证了输出的格式合规性。这些结果验证了Deco-G框架的有效性和优越性。
🎯 应用场景
Deco-G框架可应用于各种需要LLM生成结构化输出的任务,例如:自动代码生成、知识图谱构建、报告生成、对话系统等。该方法能够提高LLM在这些任务中的性能和可靠性,并降低人工干预的成本。未来,该方法可以进一步扩展到更复杂的任务和更广泛的应用领域。
📄 摘要(原文)
Large language models (LLMs) are increasingly adept at following instructions containing task descriptions to solve complex problems, such as mathematical reasoning and automatic evaluation (LLM-as-a-Judge). However, as prompts grow more complex, models often struggle to adhere to all instructions. This difficulty is especially common when instructive prompts intertwine reasoning directives -- specifying what the model should solve -- with rigid formatting requirements that dictate how the solution must be presented. The entanglement creates competing goals for the model, suggesting that more explicit separation of these two aspects could lead to improved performance. To this front, we introduce Deco-G, a decoding framework that explicitly decouples format adherence from task solving. Deco-G handles format compliance with a separate tractable probabilistic model (TPM), while prompts LLMs with only task instructions. At each decoding step, Deco-G combines next token probabilities from the LLM with the TPM calculated format compliance likelihood to form the output probability. To make this approach both practical and scalable for modern instruction-tuned LLMs, we introduce three key innovations: instruction-aware distillation, a flexible trie-building algorithm, and HMM state pruning for computational efficiency. We demonstrate the effectiveness of Deco-G across a wide range of tasks with diverse format requirements, including mathematical reasoning, LLM-as-a-judge, and event argument extraction. Overall, our approach yields 1.0% to 6.0% relative gain over regular prompting practice with guaranteed format compliance.