TRepLiNa: Layer-wise CKA+REPINA Alignment Improves Low-Resource Machine Translation in Aya-23 8B
作者: Toshiki Nakai, Ravi Kiran Chikkala, Lena Sophie Oberkircher, Nicholas Jennings, Natalia Skachkova, Tatiana Anikina, Jesujoba Oluwadara Alabi
分类: cs.CL, cs.AI
发布日期: 2025-10-03 (更新: 2025-12-10)
备注: It is work in progress
💡 一句话要点
TRepLiNa通过层间CKA+REPINA对齐提升Aya-23 8B在低资源机器翻译中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低资源机器翻译 跨语言对齐 Centered Kernel Alignment REPINA正则化 多语言模型 Aya-23 8B QLoRA
📋 核心要点
- 低资源语言机器翻译面临数据匮乏的挑战,现有方法难以有效利用预训练模型的知识。
- TRepLiNa通过CKA对齐不同语言的表示,并使用REPINA正则化参数更新,防止模型偏离预训练状态。
- 实验表明,TRepLiNa在低资源语言翻译任务中,尤其是在数据稀缺场景下,能够有效提升翻译质量。
📝 摘要(中文)
2025年低资源环境和社会影响多模态模型(MMLoSo)语言挑战旨在解决印度最紧迫的语言差距之一:缺乏针对其多样化低资源语言(LRL)的资源。本研究探讨了在decoder-only多语言大型语言模型(LLM)的特定内部层中强制执行跨语言相似性是否可以提高从LRL到高资源语言(HRL)的翻译质量。具体而言,我们将鼓励不同语言表示对齐的相似性度量Centered Kernel Alignment (CKA)与限制参数更新以保持接近预训练模型的正则化方法REPINA相结合,形成一种名为TRepLiNa的联合方法。我们使用Aya-23 8B和QLoRA,在MMLoSo共享任务语言对(蒙达里语、桑塔利语、比里语)与印地语/英语枢轴上,进行了零样本、少样本和微调设置的实验。结果表明,使用TRepLiNa (CKA+REPINA)对齐中间层是一种低成本、实用的方法,可以提高LRL翻译质量,尤其是在数据稀缺的情况下。
🔬 方法详解
问题定义:论文旨在解决低资源语言到高资源语言的机器翻译问题。现有方法在低资源场景下,难以充分利用预训练模型中蕴含的知识,容易出现过拟合或泛化能力不足的问题。因此,如何在数据稀缺的情况下,有效利用预训练模型,提升低资源语言的翻译质量,是本研究要解决的核心问题。
核心思路:论文的核心思路是通过在多语言大型语言模型的中间层强制执行跨语言相似性来提升翻译质量。具体而言,通过Centered Kernel Alignment (CKA) 鼓励不同语言的表示对齐,使得模型能够更好地理解和转换不同语言之间的语义信息。同时,使用REPINA正则化方法,限制参数更新,防止模型过度偏离预训练状态,从而保留预训练模型的知识。
技术框架:整体框架包括以下步骤:首先,使用预训练的多语言大型语言模型(如Aya-23 8B)作为基础模型。然后,在模型的中间层,计算不同语言表示之间的CKA相似度,并将其作为损失函数的一部分,用于指导模型的训练。同时,使用REPINA正则化方法,限制参数更新的幅度。最后,使用QLoRA进行参数高效的微调。
关键创新:论文的关键创新在于将CKA和REPINA两种方法结合起来,形成一种新的训练方法TRepLiNa。CKA用于对齐不同语言的表示,REPINA用于防止模型过度偏离预训练状态。这种结合能够有效地利用预训练模型的知识,并在低资源场景下提升翻译质量。
关键设计:在实验中,作者使用了Aya-23 8B模型,并使用QLoRA进行微调。CKA损失函数用于对齐模型的中间层表示。REPINA正则化方法通过限制参数更新的L2范数来实现。具体的参数设置包括学习率、batch size、训练epochs等。作者在MMLoSo共享任务的语言对(蒙达里语、桑塔利语、比里语)与印地语/英语枢轴上进行了实验。
🖼️ 关键图片

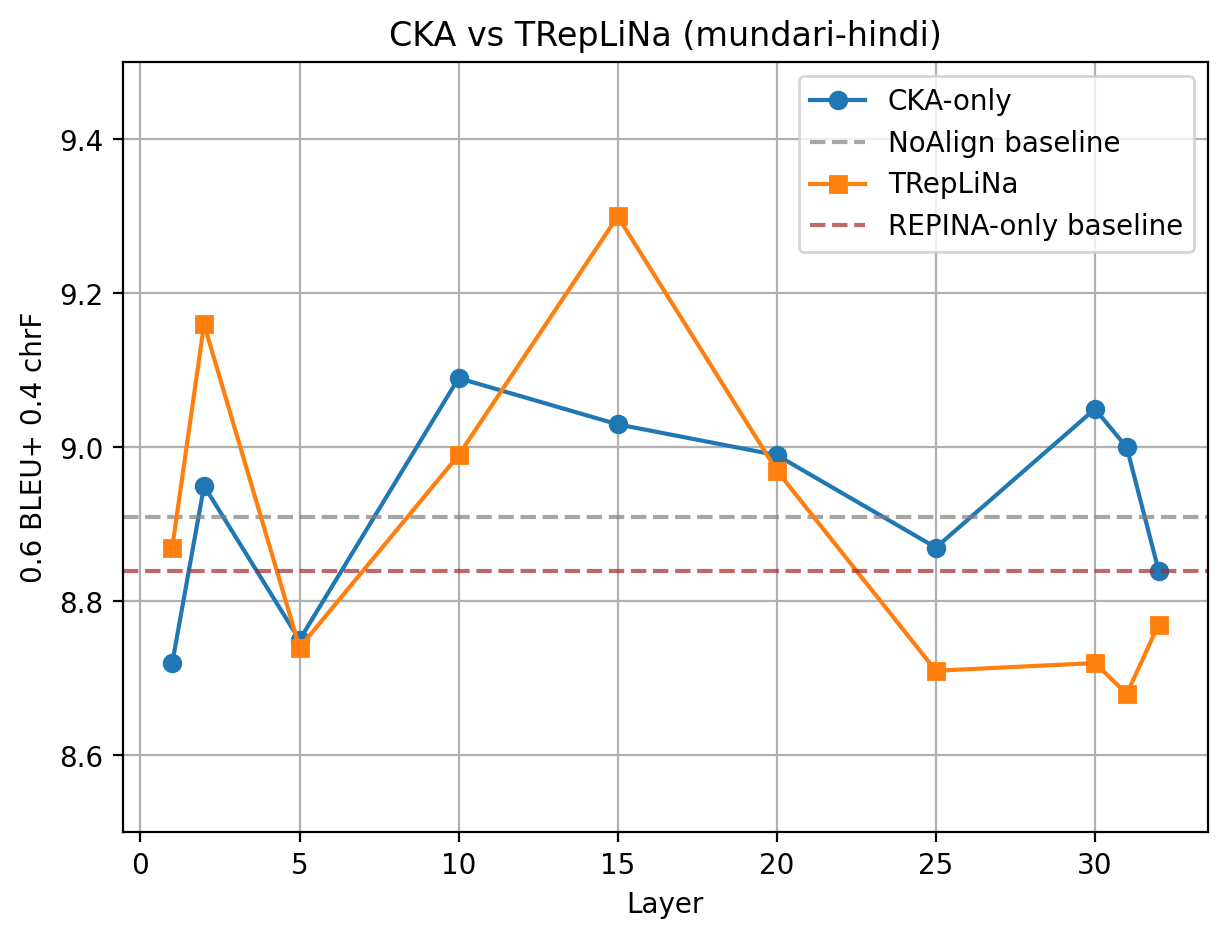

📊 实验亮点
实验结果表明,使用TRepLiNa (CKA+REPINA)对齐中间层是一种低成本、实用的方法,可以提高LRL翻译质量,尤其是在数据稀缺的情况下。具体性能数据未知,但论文强调了该方法在数据稀缺场景下的有效性,并与其他基线方法进行了对比(具体对比信息未知)。
🎯 应用场景
该研究成果可应用于低资源语言的机器翻译、跨语言信息检索、多语言对话系统等领域。通过提升低资源语言的机器翻译质量,可以促进不同语言之间的交流和理解,有助于保护和传承濒危语言,并为全球化背景下的文化交流提供技术支持。
📄 摘要(原文)
The 2025 Multimodal Models for Low-Resource Contexts and Social Impact (MMLoSo) Language Challenge addresses one of India's most pressing linguistic gaps: the lack of resources for its diverse low-resource languages (LRLs). In this study, we investigate whether enforcing cross-lingual similarity in specific internal layers of a decoder-only multilingual large language model (LLM) can improve translation quality from LRL to high-resource language (HRL). Specifically, we combine Centered Kernel Alignment (CKA), a similarity metric that encourages representations of different languages to align, with REPINA, a regularization method that constrains parameter updates to remain close to the pretrained model, into a joint method we call TRepLiNa. In this research project, we experiment with zero-shot, few-shot, and fine-tuning settings using Aya-23 8B with QLoRA across MMLoSo shared task language pairs (Mundari, Santali, Bhili) with Hindi/English pivots. Our results show that aligning mid-level layers using TRepLiNa (CKA+REPINA) is a low-cost, practical approach to improving LRL translation, especially in data-scarce settings.