Reactive Transformer (RxT) -- Stateful Real-Time Processing for Event-Driven Reactive Language Models
作者: Adam Filipek
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-10-03
备注: 25 pages, 13 figures
💡 一句话要点
提出Reactive Transformer (RxT),用于事件驱动的实时状态语言建模,解决长对话中的计算瓶颈。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Reactive Transformer 事件驱动 实时对话 状态语言模型 短期记忆 低延迟 长对话
📋 核心要点
- 现有Transformer模型在长对话中面临计算复杂度高、延迟大的问题,难以实现实时交互。
- RxT采用事件驱动范式,将对话轮次视为离散事件,通过短期记忆(STM)维护上下文。
- 实验表明,RxT在合成数据上表现出优于基线的性能,并实现了恒定时间的推理延迟。
📝 摘要(中文)
Transformer架构已成为大型语言模型(LLM)的事实标准,在语言理解和生成方面表现出卓越的能力。然而,其在对话AI中的应用受到其无状态特性以及计算复杂度随序列长度L呈平方增长(O(L^2))的根本限制。目前的模型通过在每一轮对话中重新处理不断扩展的对话历史来模拟记忆,导致长对话中成本高昂和延迟。本文介绍了Reactive Transformer(RxT),一种旨在通过从数据驱动范式转变为事件驱动范式来克服这些限制的新型架构。RxT将每个对话轮次作为离散事件实时处理,并在集成的固定大小的短期记忆(STM)系统中维护上下文。该架构具有独特的操作周期,其中生成器-解码器基于当前查询和先前的记忆状态生成响应,之后记忆编码器和专用记忆注意力网络异步地使用完整交互的表示来更新STM。这种设计从根本上改变了缩放动态,将对话的总用户成本从关于交互次数N的平方(O(N^2 * T))降低到线性(O(N * T))。通过将响应生成与记忆更新分离,RxT实现了低延迟,从而实现了真正的实时、有状态且经济上可行的长篇对话。我们通过一系列在合成数据上进行的初步实验验证了我们的架构,证明了与大小相当的基线无状态模型相比,RxT具有卓越的性能和恒定时间的推理延迟。
🔬 方法详解
问题定义:现有基于Transformer的对话系统在处理长对话时,需要重复处理整个对话历史,导致计算复杂度呈平方级增长,推理延迟高,难以满足实时交互的需求。无状态的特性也使得模型难以维持长期一致性。
核心思路:RxT的核心思路是将对话过程视为一系列离散的事件,每个事件对应一个对话轮次。通过维护一个固定大小的短期记忆(STM),模型可以逐步更新对话状态,避免重复处理历史信息,从而降低计算复杂度,提高推理速度。
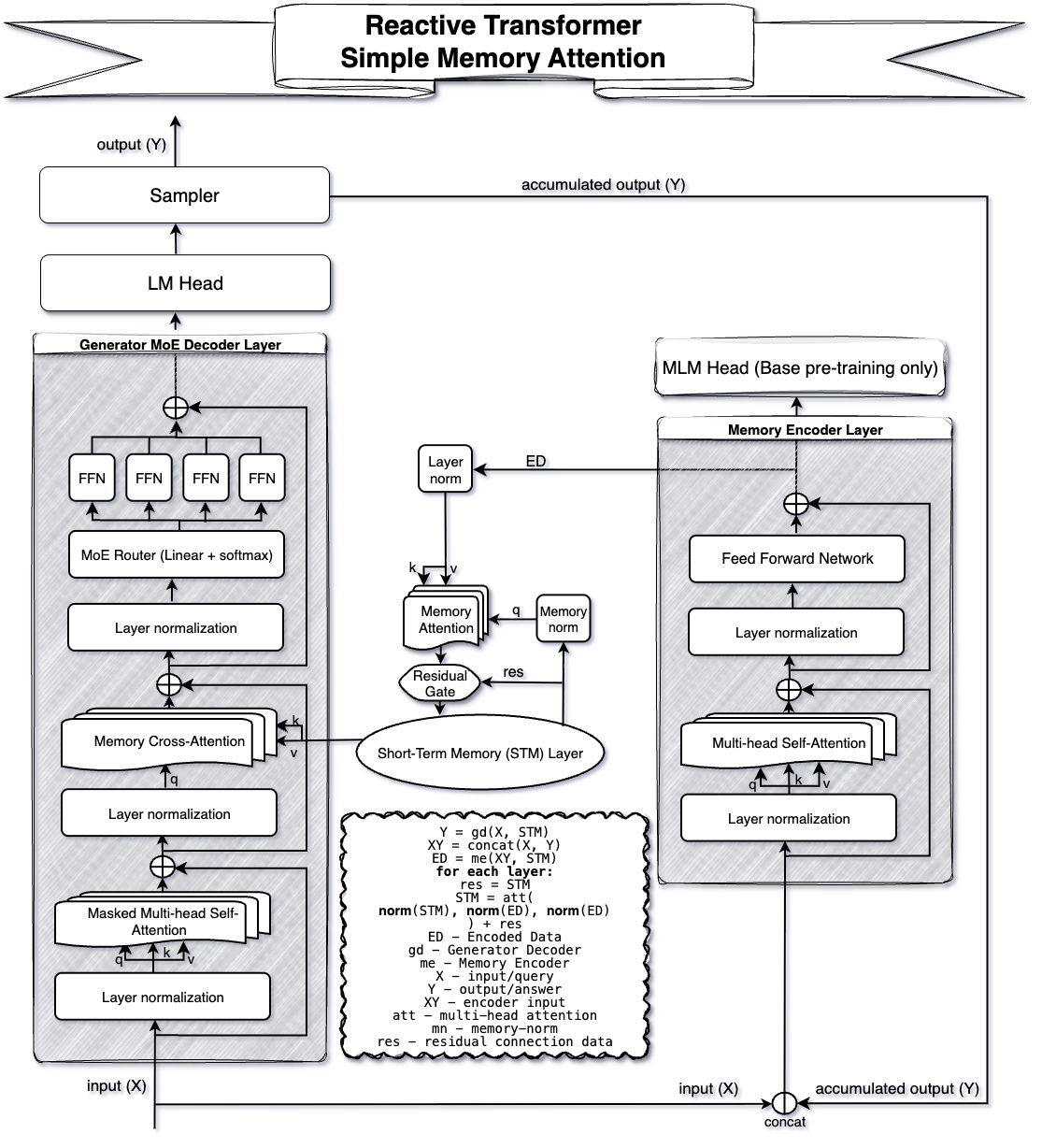
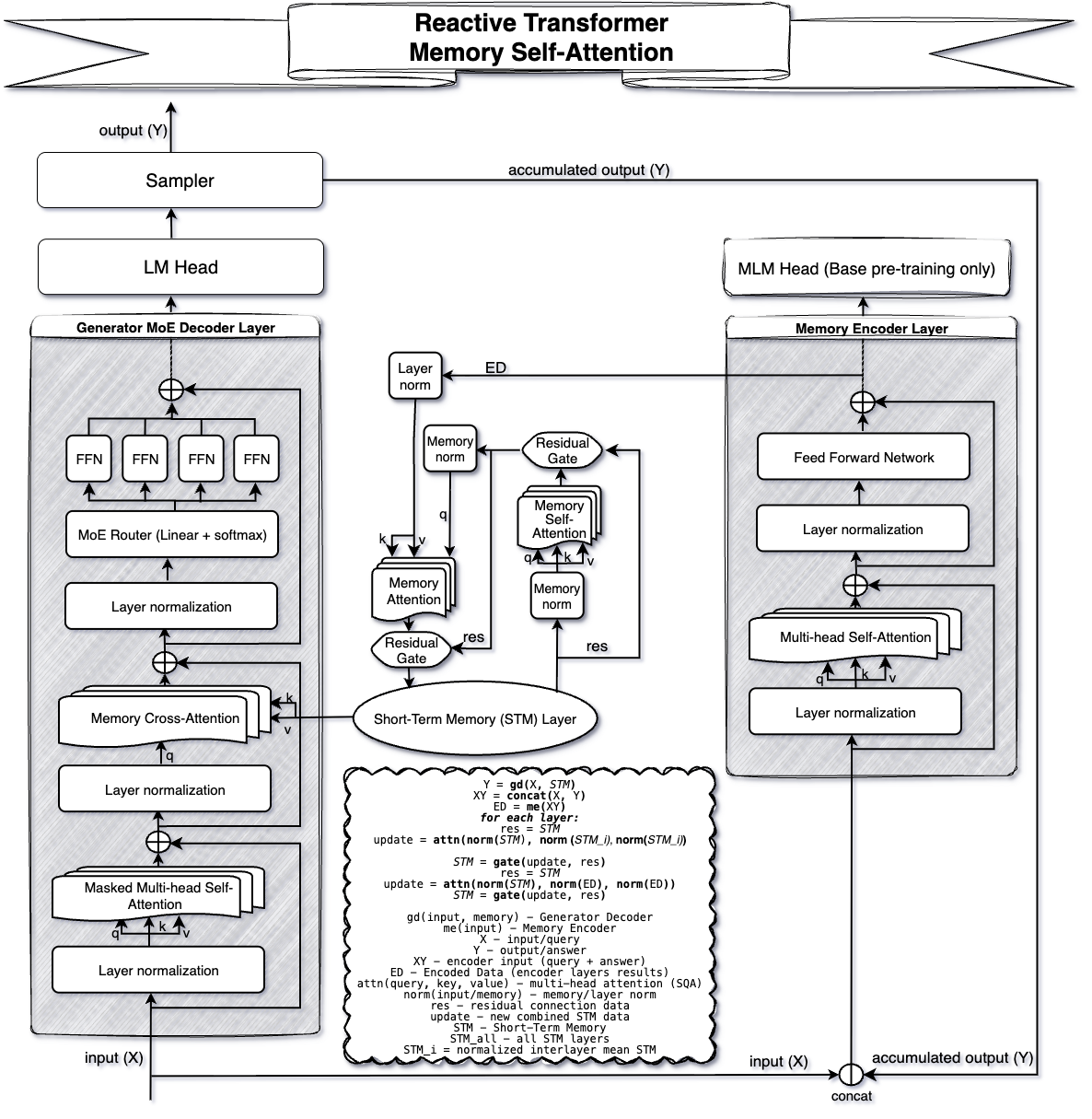
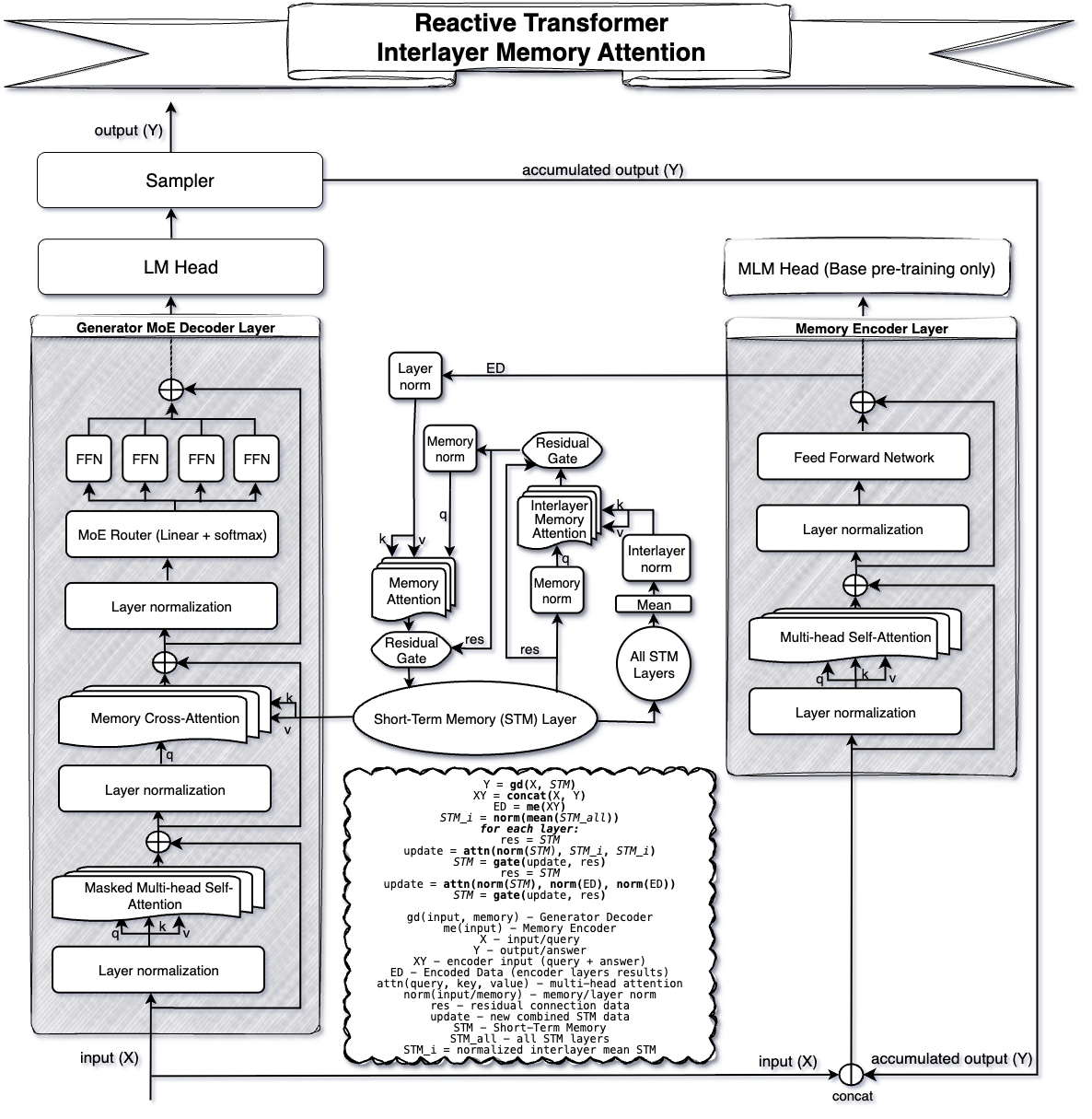
技术框架:RxT的整体架构包含以下几个主要模块: 1. Generator-Decoder: 基于当前查询和STM生成响应。 2. Memory-Encoder: 将当前轮次的交互信息编码成记忆表示。 3. Memory Attention Network: 用于更新STM,融合新的记忆表示和之前的记忆状态。 RxT的操作流程是:首先,Generator-Decoder基于当前查询和STM生成响应;然后,Memory-Encoder将当前轮次的交互信息编码;最后,Memory Attention Network使用编码后的信息更新STM。响应生成和记忆更新是解耦的,可以异步进行。
关键创新:RxT最重要的创新点在于其事件驱动的架构和固定大小的STM。与传统的Transformer模型需要处理整个对话历史不同,RxT只需要处理当前轮次的交互信息,并将关键信息存储在STM中。这种设计将计算复杂度从O(N^2 * T)降低到O(N * T),其中N是交互次数,T是序列长度。
关键设计:RxT的关键设计包括: 1. 固定大小的STM: STM的大小是一个重要的超参数,需要根据具体的应用场景进行调整。 2. Memory Attention Network: 该网络的设计需要保证能够有效地融合新的记忆表示和之前的记忆状态。 3. 异步更新机制: 响应生成和记忆更新的解耦是实现低延迟的关键。
🖼️ 关键图片
📊 实验亮点
论文通过在合成数据上的实验验证了RxT的性能。实验结果表明,RxT在推理延迟方面优于基线模型,实现了恒定时间的推理延迟。此外,RxT在记忆保持方面也表现出更好的性能,能够更有效地维持对话状态。具体性能数据未知,但结论是RxT在长对话场景下具有显著优势。
🎯 应用场景
RxT适用于需要实时交互和长期记忆的对话系统,例如智能客服、虚拟助手、游戏AI等。其低延迟和线性计算复杂度的特性使得它可以处理更长的对话,并维持更一致的对话状态。未来,RxT可以应用于更复杂的任务,例如多轮对话推理、个性化对话等。
📄 摘要(原文)
The Transformer architecture has become the de facto standard for Large Language Models (LLMs), demonstrating remarkable capabilities in language understanding and generation. However, its application in conversational AI is fundamentally constrained by its stateless nature and the quadratic computational complexity ($O(L^2)$) with respect to sequence length $L$. Current models emulate memory by reprocessing an ever-expanding conversation history with each turn, leading to prohibitive costs and latency in long dialogues. This paper introduces the Reactive Transformer (RxT), a novel architecture designed to overcome these limitations by shifting from a data-driven to an event-driven paradigm. RxT processes each conversational turn as a discrete event in real-time, maintaining context in an integrated, fixed-size Short-Term Memory (STM) system. The architecture features a distinct operational cycle where a generator-decoder produces a response based on the current query and the previous memory state, after which a memory-encoder and a dedicated Memory Attention network asynchronously update the STM with a representation of the complete interaction. This design fundamentally alters the scaling dynamics, reducing the total user-facing cost of a conversation from quadratic ($O(N^2 \cdot T)$) to linear ($O(N \cdot T)$) with respect to the number of interactions $N$. By decoupling response generation from memory updates, RxT achieves low latency, enabling truly real-time, stateful, and economically viable long-form conversations. We validated our architecture with a series of proof-of-concept experiments on synthetic data, demonstrating superior performance and constant-time inference latency compared to a baseline stateless model of comparable size.