What is a protest anyway? Codebook conceptualization is still a first-order concern in LLM-era classification
作者: Andrew Halterman, Katherine A. Keith
分类: cs.CL
发布日期: 2025-10-03
💡 一句话要点
强调LLM时代文本分类中概念化重要性,避免因忽略概念定义导致偏差
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本分类 大语言模型 概念化 偏差分析 计算社会科学
📋 核心要点
- 现有方法在LLM时代容易忽略文本分类任务中的概念化步骤,导致下游分析产生偏差。
- 论文核心在于强调概念化的重要性,并指出仅仅提高LLM准确率无法消除概念偏差。
- 通过模拟实验,验证了概念化偏差的存在,并为CSS分析师提供了避免偏差的建议。
📝 摘要(中文)
生成式大语言模型(LLMs)目前被广泛应用于计算社会科学(CSS)中的文本分类。本文关注LLM提示前后两个步骤:待分类概念的概念化,以及在下游统计推断中使用LLM预测结果。我们认为,LLM可能会诱使分析师跳过概念化步骤,从而产生概念化错误,进而导致下游估计产生偏差。通过模拟实验,我们证明了这种概念化引起的偏差不能仅仅通过提高LLM的准确性或事后偏差校正方法来纠正。最后,我们提醒CSS分析师,概念化在LLM时代仍然是首要考虑的问题,并为如何获得低成本、无偏、低方差的下游估计提供了具体建议。
🔬 方法详解
问题定义:论文旨在解决计算社会科学(CSS)领域中,使用大型语言模型(LLM)进行文本分类时,由于忽略概念化步骤而导致的偏差问题。现有方法过度依赖LLM的能力,容易跳过对分类概念的清晰定义,导致分类结果与研究目标不一致,进而影响下游统计推断的准确性。这种概念化偏差是现有方法的一个重要痛点。
核心思路:论文的核心思路是强调在LLM时代,概念化仍然是文本分类的首要关注点。即使LLM具有强大的文本理解和生成能力,如果对分类概念的定义不清晰或存在偏差,LLM的预测结果也会受到影响,导致下游分析出现错误。因此,论文建议分析师在使用LLM进行文本分类之前,必须认真进行概念化,明确分类概念的内涵和外延。
技术框架:论文主要通过模拟实验来验证概念化偏差的存在。具体而言,论文首先定义了一组模拟数据,其中包含了不同概念的文本样本。然后,论文使用LLM对这些文本样本进行分类,并比较了不同概念化策略下的分类结果。最后,论文分析了分类结果中的偏差,并探讨了如何通过改进概念化策略来减少偏差。论文没有提出新的技术架构或流程,而是侧重于强调概念化的重要性。
关键创新:论文最重要的技术创新点在于,它指出了在LLM时代,概念化仍然是文本分类的关键环节,即使LLM具有强大的能力,也不能忽略概念化的重要性。与现有方法不同,论文强调了概念化偏差的存在,并提出了通过改进概念化策略来减少偏差的建议。
关键设计:论文的关键设计在于模拟实验的设计。论文通过模拟数据来控制概念化偏差的来源,从而能够更清晰地分析概念化偏差的影响。此外,论文还探讨了不同概念化策略对分类结果的影响,为分析师提供了改进概念化策略的参考。
🖼️ 关键图片

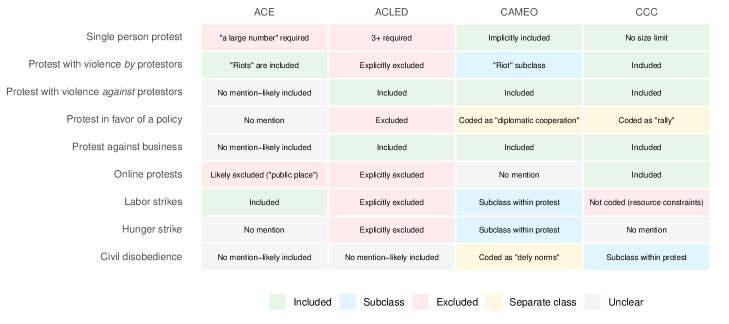
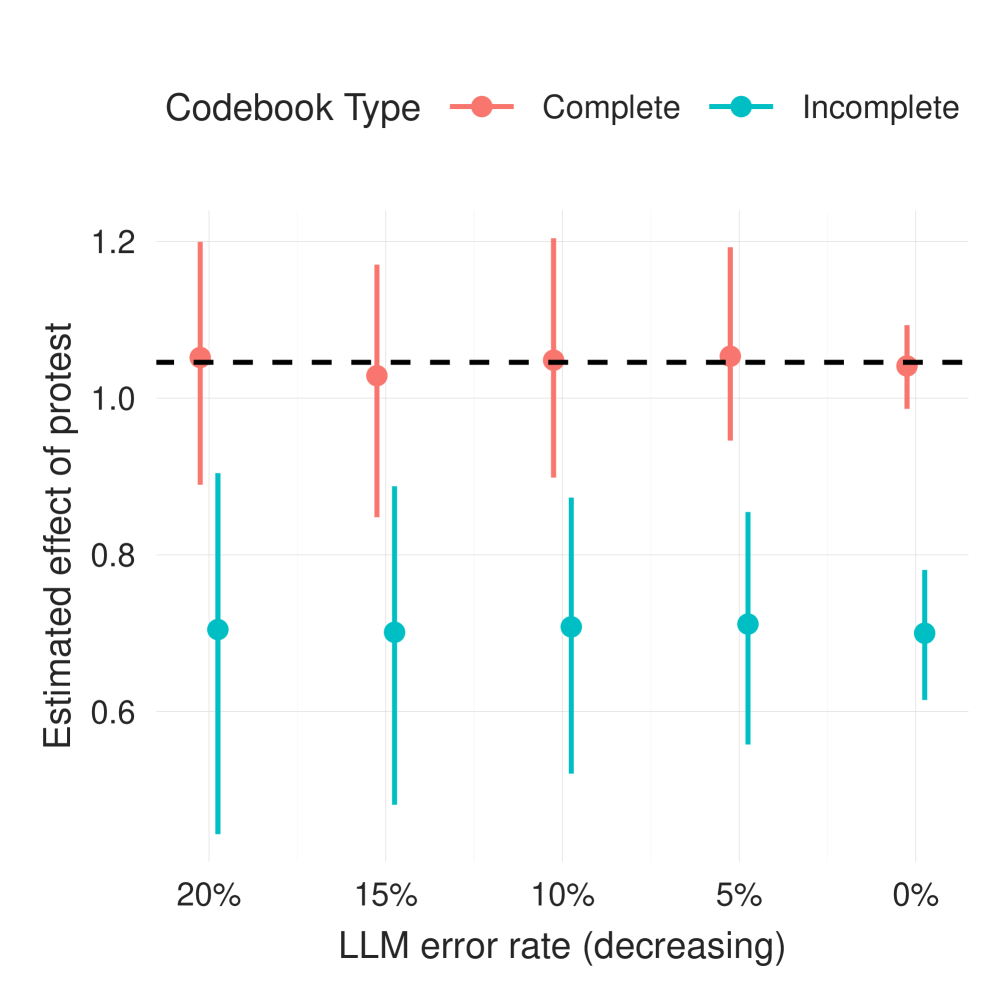
📊 实验亮点
论文通过模拟实验证明,即使提高LLM的准确性或采用事后偏差校正方法,也无法完全消除概念化偏差。这表明,在LLM时代,概念化仍然是文本分类的关键环节。论文还为CSS分析师提供了避免概念化偏差的具体建议,例如明确定义分类概念、进行概念验证等。
🎯 应用场景
该研究成果对计算社会科学、政治学、传播学等领域具有重要应用价值。在这些领域,研究人员经常需要使用文本分类技术来分析大量的文本数据,例如新闻报道、社交媒体帖子、政策文件等。通过强调概念化的重要性,该研究可以帮助研究人员更准确地理解和分析文本数据,从而得出更可靠的研究结论。此外,该研究还可以应用于舆情分析、情感分析、风险评估等领域。
📄 摘要(原文)
Generative large language models (LLMs) are now used extensively for text classification in computational social science (CSS). In this work, focus on the steps before and after LLM prompting -- conceptualization of concepts to be classified and using LLM predictions in downstream statistical inference -- which we argue have been overlooked in much of LLM-era CSS. We claim LLMs can tempt analysts to skip the conceptualization step, creating conceptualization errors that bias downstream estimates. Using simulations, we show that this conceptualization-induced bias cannot be corrected for solely by increasing LLM accuracy or post-hoc bias correction methods. We conclude by reminding CSS analysts that conceptualization is still a first-order concern in the LLM-era and provide concrete advice on how to pursue low-cost, unbiased, low-variance downstream estimates.