Fine-Tuning on Noisy Instructions: Effects on Generalization and Performance
作者: Ahmed Alajrami, Xingwei Tan, Nikolaos Aletras
分类: cs.CL
发布日期: 2025-10-03 (更新: 2025-11-11)
备注: Accepted to AACL 2025 main conference
💡 一句话要点
通过噪声指令微调提升大语言模型泛化性和鲁棒性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令微调 噪声指令 鲁棒性 大语言模型 数据增强
📋 核心要点
- 现有大语言模型对指令措辞的细微变化敏感,影响其在实际应用中的鲁棒性。
- 论文提出通过在指令微调数据中引入扰动,增强模型对噪声指令的抵抗力。
- 实验结果表明,使用扰动指令进行微调在某些情况下可以提高下游任务的性能。
📝 摘要(中文)
指令微调在提升大型语言模型(LLMs)的任务解决能力方面起着至关重要的作用,提高了它们在各种任务上生成有用响应的可用性。然而,之前的工作表明,它们对指令措辞的细微变化很敏感。在本文中,我们探讨了在指令微调数据中引入扰动是否可以增强LLMs对噪声指令的抵抗力。我们重点研究了使用扰动(例如删除停用词或打乱词序)进行指令微调如何影响LLMs在广泛使用的基准测试(MMLU、BBH、GSM8K)的原始版本和扰动版本上的性能。我们进一步评估了学习动态和模型行为的潜在变化。令人惊讶的是,我们的结果表明,在某些情况下,对扰动指令进行指令微调可以提高下游性能。这些发现强调了在指令微调中包含扰动指令的重要性,这可以使LLMs对嘈杂的用户输入更具弹性。
🔬 方法详解
问题定义:现有的大语言模型在指令微调后,虽然在特定任务上表现出色,但对指令的微小变化非常敏感。这种敏感性导致模型在面对真实用户输入的各种表达方式时,性能显著下降。因此,如何提高模型对指令噪声的鲁棒性是一个重要的研究问题。
核心思路:论文的核心思路是通过在指令微调阶段引入带有扰动的指令数据,让模型学习到指令的不同表达方式,从而提高其泛化能力和对噪声指令的抵抗力。这种方法类似于数据增强,旨在使模型更加稳健。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择预训练的大语言模型;2) 准备指令微调数据集;3) 对指令数据进行扰动处理,例如删除停用词、打乱词序等;4) 使用原始指令和扰动后的指令对模型进行微调;5) 在原始指令和扰动后的指令上评估模型的性能。
关键创新:该研究的关键创新在于探索了使用扰动指令进行微调以提高大语言模型鲁棒性的方法。与传统的指令微调方法不同,该方法更加关注模型在面对真实世界噪声数据时的表现。
关键设计:在指令扰动方面,论文采用了两种主要策略:一是删除停用词,二是随机打乱指令中的词序。这些扰动方式旨在模拟用户在实际使用中可能出现的指令表达不规范的情况。此外,论文还仔细评估了不同扰动程度对模型性能的影响,并选择了合适的扰动参数。
🖼️ 关键图片

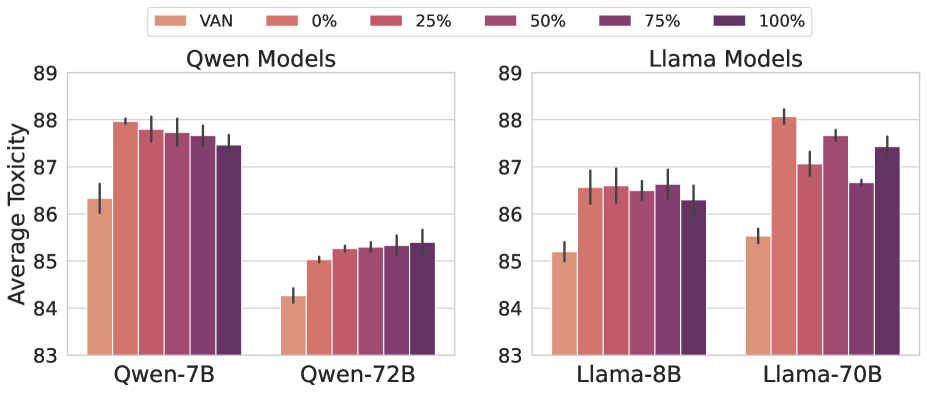

📊 实验亮点
实验结果表明,在某些情况下,使用扰动指令进行微调可以提高模型在下游任务上的性能。例如,在MMLU、BBH和GSM8K等基准测试中,经过扰动指令微调的模型在原始指令和扰动指令上的表现均有所提升,这表明该方法能够有效提高模型的泛化能力和鲁棒性。
🎯 应用场景
该研究成果可应用于各种需要与用户进行自然语言交互的场景,例如智能助手、聊天机器人、问答系统等。通过提高模型对噪声指令的鲁棒性,可以显著提升用户体验,并降低模型出错的概率。未来,该方法还可以扩展到其他类型的噪声数据,例如语音识别错误、图像模糊等。
📄 摘要(原文)
Instruction-tuning plays a vital role in enhancing the task-solving abilities of large language models (LLMs), improving their usability in generating helpful responses on various tasks. However, previous work has demonstrated that they are sensitive to minor variations in instruction phrasing. In this paper, we explore whether introducing perturbations in instruction-tuning data can enhance LLMs' resistance against noisy instructions. We focus on how instruction-tuning with perturbations, such as removing stop words or shuffling words, affects LLMs' performance on the original and perturbed versions of widely-used benchmarks (MMLU, BBH, GSM8K). We further assess learning dynamics and potential shifts in model behavior. Surprisingly, our results suggest that instruction-tuning on perturbed instructions can, in some cases, improve downstream performance. These findings highlight the importance of including perturbed instructions in instruction-tuning, which can make LLMs more resilient to noisy user inputs.