Omni-Embed-Nemotron: A Unified Multimodal Retrieval Model for Text, Image, Audio, and Video
作者: Mengyao Xu, Wenfei Zhou, Yauhen Babakhin, Gabriel Moreira, Ronay Ak, Radek Osmulski, Bo Liu, Even Oldridge, Benedikt Schifferer
分类: cs.CL
发布日期: 2025-10-03
💡 一句话要点
Omni-Embed-Nemotron:统一多模态检索模型,支持文本、图像、音频和视频检索
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态检索 跨模态学习 统一嵌入 文本图像视频 检索增强生成
📋 核心要点
- 现有检索方法难以处理现实文档中视觉和语义丰富的内容,限制了RAG在实际场景中的应用。
- Omni-Embed-Nemotron通过统一的多模态嵌入,支持文本、图像、音频和视频的跨模态和联合模态检索。
- 实验结果表明,Omni-Embed-Nemotron在文本、图像和视频检索方面表现出色,验证了其有效性。
📝 摘要(中文)
本文提出了Omni-Embed-Nemotron,一个统一的多模态检索嵌入模型,旨在处理日益复杂的现实世界信息需求。检索增强生成(RAG)通过整合外部知识显著提升了语言模型的能力,但现有的基于文本的检索器依赖于干净、结构化的输入,难以处理PDF、幻灯片或视频等现实文档中富含视觉和语义的内容。ColPali等近期工作表明,使用基于图像的表示来保留文档布局可以提高检索质量。受Qwen2.5-Omni等最新多模态模型能力的启发,我们将检索范围扩展到文本和图像之外,同时支持音频和视频模态。Omni-Embed-Nemotron使用单个模型实现跨模态(例如,文本-视频)和联合模态(例如,文本-视频+音频)检索。我们描述了Omni-Embed-Nemotron的架构、训练设置和评估结果,并展示了其在文本、图像和视频检索方面的有效性。
🔬 方法详解
问题定义:现有基于文本的检索器在处理现实世界文档(如PDF、幻灯片、视频等)时面临挑战,这些文档包含丰富的视觉和语义信息,而不仅仅是文本。传统方法难以有效利用这些多模态信息进行检索,导致检索效果不佳。
核心思路:Omni-Embed-Nemotron的核心思路是构建一个统一的多模态嵌入空间,将文本、图像、音频和视频等不同模态的数据映射到该空间中。通过计算不同模态数据在该空间中的相似度,实现跨模态和联合模态的检索。
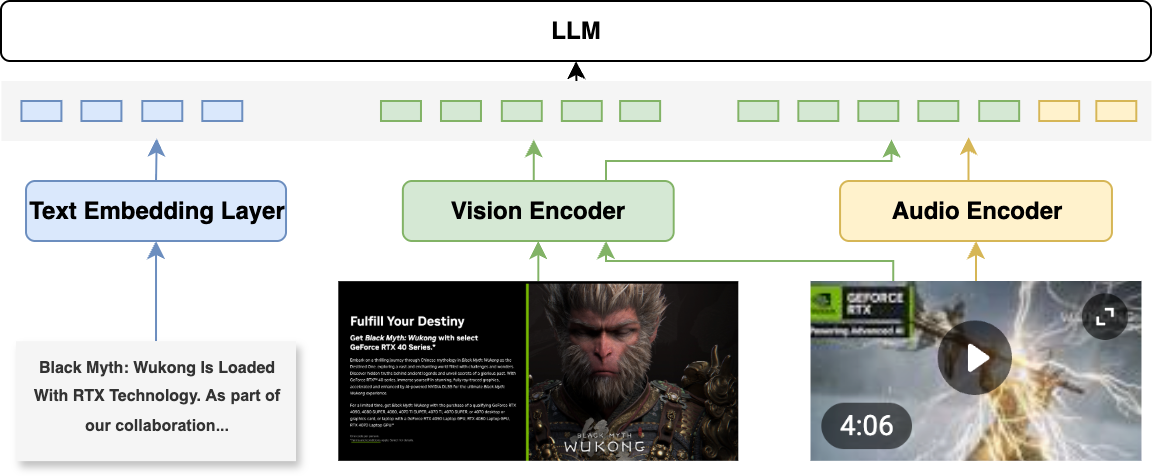
技术框架:Omni-Embed-Nemotron的整体架构包含多个模态编码器和一个共享的嵌入空间。每个模态编码器负责将对应模态的数据(文本、图像、音频、视频)编码成向量表示。然后,这些向量表示被映射到共享的嵌入空间中。检索时,将查询和候选文档分别编码到嵌入空间中,计算它们的相似度,并根据相似度排序返回检索结果。
关键创新:Omni-Embed-Nemotron的关键创新在于其统一的多模态嵌入框架,能够同时处理文本、图像、音频和视频等多种模态的数据。这使得模型能够利用不同模态之间的互补信息,提高检索的准确性和鲁棒性。此外,该模型支持跨模态和联合模态检索,进一步扩展了其应用范围。
关键设计:具体的网络结构和损失函数细节在论文中未明确给出,属于未知信息。但可以推测,模型可能采用了对比学习或三元组损失等方法来训练嵌入空间,使得相似的样本在嵌入空间中距离更近,不相似的样本距离更远。具体的参数设置和网络结构可能参考了Qwen2.5-Omni等先进的多模态模型。
🖼️ 关键图片


📊 实验亮点
论文展示了Omni-Embed-Nemotron在文本、图像和视频检索方面的有效性,但具体的性能数据、对比基线和提升幅度等信息在摘要中未给出。更详细的实验结果需要在论文正文中查找。摘要强调了其支持跨模态和联合模态检索的能力。
🎯 应用场景
Omni-Embed-Nemotron可应用于多种场景,如多媒体文档检索、视频内容理解、智能客服、教育资源检索等。该模型能够有效利用多模态信息,提高检索准确率,为用户提供更精准、更全面的信息服务。未来,该模型有望在RAG系统中发挥更大的作用,提升语言模型的知识获取能力。
📄 摘要(原文)
We present Omni-Embed-Nemotron, a unified multimodal retrieval embedding model developed to handle the increasing complexity of real-world information needs. While Retrieval-Augmented Generation (RAG) has significantly advanced language models by incorporating external knowledge, existing text-based retrievers rely on clean, structured input and struggle with the visually and semantically rich content found in real-world documents such as PDFs, slides, or videos. Recent work such as ColPali has shown that preserving document layout using image-based representations can improve retrieval quality. Building on this, and inspired by the capabilities of recent multimodal models such as Qwen2.5-Omni, we extend retrieval beyond text and images to also support audio and video modalities. Omni-Embed-Nemotron enables both cross-modal (e.g., text - video) and joint-modal (e.g., text - video+audio) retrieval using a single model. We describe the architecture, training setup, and evaluation results of Omni-Embed-Nemotron, and demonstrate its effectiveness in text, image, and video retrieval.