Reward Models are Metrics in a Trench Coat
作者: Sebastian Gehrmann
分类: cs.CL, cs.AI
发布日期: 2025-10-03
💡 一句话要点
强调奖励模型与评估指标的关联,提升大语言模型后训练效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 奖励模型 评估指标 大型语言模型 强化学习 后训练
📋 核心要点
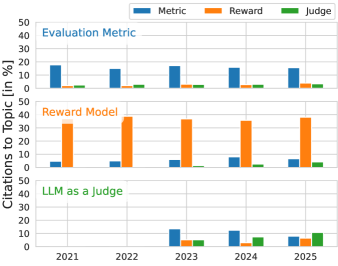
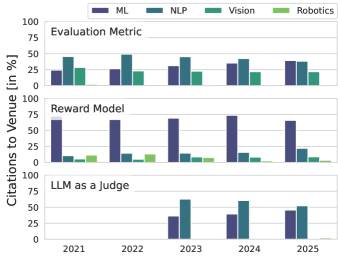
- 现有奖励模型与评估指标研究领域相对独立,导致术语重复和方法上的重复探索,效率较低。
- 论文核心思想是连接奖励模型和评估指标两个领域,借鉴彼此的经验,从而解决共同的挑战。
- 论文通过实验证明,在特定任务上,评估指标的表现优于奖励模型,突出了融合的潜力。
📝 摘要(中文)
大型语言模型后训练中,基于强化学习的方法因奖励模型的出现而备受关注。奖励模型评估模型输出样本的质量,从而生成训练信号。评估指标也执行类似的任务,用于监控AI模型的性能。本文发现这两个研究领域相对独立,导致术语冗余和重复的缺陷。两者面临的共同挑战包括:易受虚假相关性影响、对下游奖励攻击的影响、提高数据质量的方法以及元评估方法。本文认为,两个领域更紧密的合作有助于克服这些问题。为此,我们展示了指标在特定任务上优于奖励模型的情况,并对这两个领域进行了广泛的调研。基于此调研,我们指出了多个研究主题,在这些主题中,更紧密的结合可以改进奖励模型和指标,例如偏好引导方法、避免虚假相关性和奖励攻击,以及校准感知的元评估。
🔬 方法详解
问题定义:论文旨在解决大型语言模型后训练中奖励模型和评估指标研究领域割裂的问题。现有方法中,奖励模型和评估指标各自发展,导致术语冗余、重复研究,并且在应对虚假相关性、奖励攻击等方面面临相似的挑战。
核心思路:论文的核心思路是将奖励模型视为一种特殊的评估指标,强调两个领域之间的联系和共通之处。通过借鉴评估指标领域的经验和方法,可以改进奖励模型的设计和应用,反之亦然。这种融合的视角有助于避免重复研究,并加速两个领域的发展。
技术框架:论文没有提出一个全新的技术框架,而是通过调研和分析,对比了奖励模型和评估指标在数据质量、偏好引导、避免奖励攻击和元评估等方面的研究现状。论文旨在建立一个桥梁,促进两个领域的研究者进行更有效的交流和合作。
关键创新:论文的关键创新在于提出了“奖励模型是穿着外套的指标”这一新颖的观点,强调了奖励模型和评估指标的本质相似性。这种观点挑战了以往将两者视为独立领域的认知,为未来的研究方向提供了新的思路。
关键设计:论文没有涉及具体的参数设置或网络结构设计。其主要贡献在于概念上的整合和对现有研究的系统性分析。论文通过案例研究,展示了评估指标在某些任务上优于奖励模型的表现,从而论证了融合的必要性。
🖼️ 关键图片

📊 实验亮点
论文通过实验证明,在特定任务上,传统的评估指标能够超越专门设计的奖励模型。这一发现强调了评估指标在奖励模型设计中的重要性,并为未来的研究方向提供了有力的支持。具体的性能数据和对比基线在论文中进行了详细的阐述。
🎯 应用场景
该研究成果可应用于提升大型语言模型的训练效果,特别是在奖励模型的构建和评估方面。通过借鉴评估指标领域的经验,可以设计更鲁棒、更可靠的奖励模型,从而提高模型的生成质量和安全性。此外,该研究也为其他AI模型的评估和改进提供了新的思路。
📄 摘要(原文)
The emergence of reinforcement learning in post-training of large language models has sparked significant interest in reward models. Reward models assess the quality of sampled model outputs to generate training signals. This task is also performed by evaluation metrics that monitor the performance of an AI model. We find that the two research areas are mostly separate, leading to redundant terminology and repeated pitfalls. Common challenges include susceptibility to spurious correlations, impact on downstream reward hacking, methods to improve data quality, and approaches to meta-evaluation. Our position paper argues that a closer collaboration between the fields can help overcome these issues. To that end, we show how metrics outperform reward models on specific tasks and provide an extensive survey of the two areas. Grounded in this survey, we point to multiple research topics in which closer alignment can improve reward models and metrics in areas such as preference elicitation methods, avoidance of spurious correlations and reward hacking, and calibration-aware meta-evaluation.