Self-Anchor: Large Language Model Reasoning via Step-by-step Attention Alignment
作者: Hongxiang Zhang, Yuan Tian, Tianyi Zhang
分类: cs.CL, cs.AI
发布日期: 2025-10-03
💡 一句话要点
Self-Anchor:通过逐步注意力对齐增强大语言模型推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理能力 注意力机制 提示学习 结构化推理 注意力对齐 长文本推理
📋 核心要点
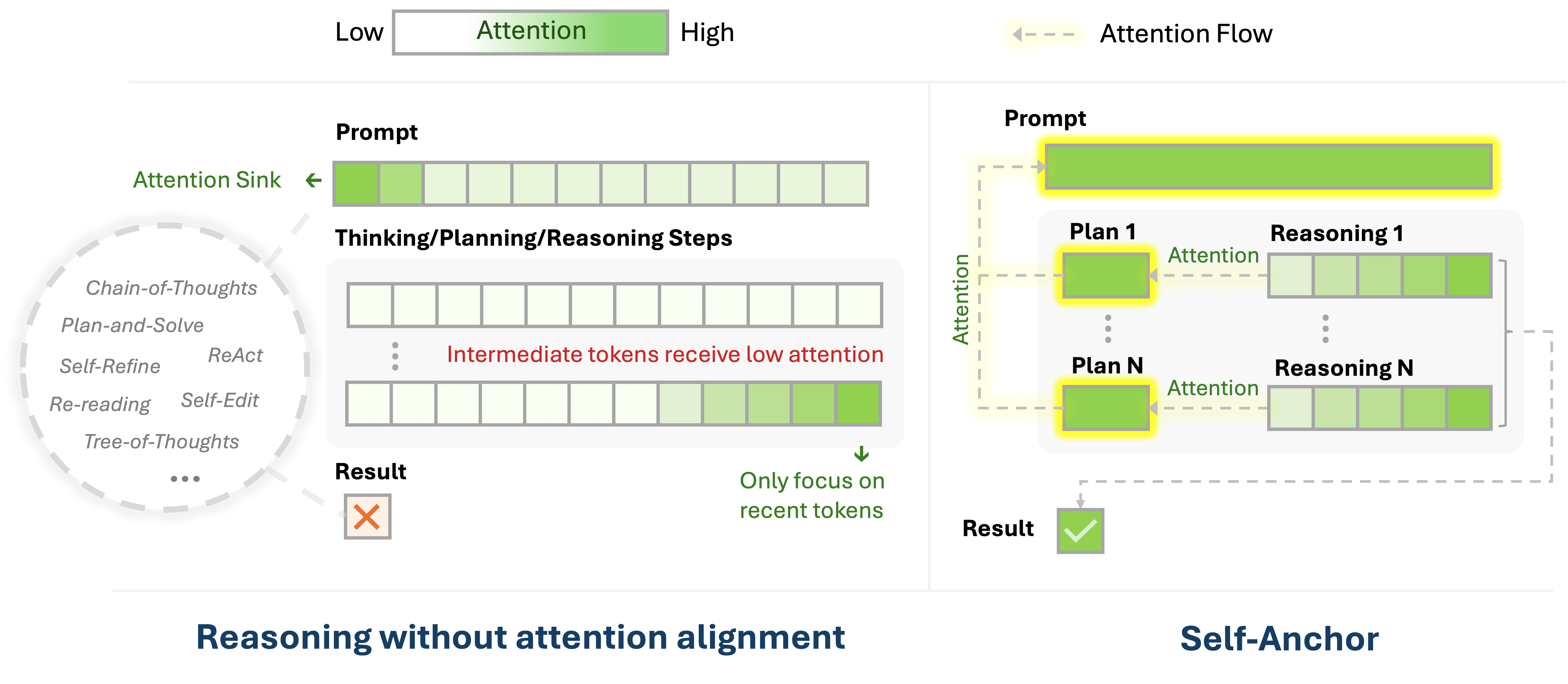
- 现有基于提示的LLM推理方法,在长推理链中易忽略关键中间步骤和原始提示,导致注意力分散和推理错误。
- Self-Anchor通过将推理分解为结构化计划,并自动对齐模型注意力到相关步骤,从而保持推理过程的专注。
- 实验表明,Self-Anchor在多个基准测试中超越现有最佳提示方法,并缩小了通用LLM与专用推理模型间的差距。
📝 摘要(中文)
为了解决大语言模型(LLMs)的复杂推理任务,基于提示的方法提供了一种轻量级的替代方案,无需微调和强化学习。然而,随着推理链的延长,关键的中间步骤和原始提示会被埋没在上下文中,导致注意力不足,从而产生错误。本文提出了一种名为Self-Anchor的新颖流程,它利用推理的内在结构来引导LLM的注意力。Self-Anchor将推理轨迹分解为结构化的计划,并自动将模型的注意力对齐到最相关的推理步骤,使模型能够在整个生成过程中保持专注。实验表明,Self-Anchor在六个基准测试中优于SOTA提示方法。值得注意的是,Self-Anchor显著缩小了“非推理”模型和专门推理模型之间的性能差距,有可能使大多数LLM能够在无需重新训练的情况下处理复杂的推理任务。
🔬 方法详解
问题定义:论文旨在解决大语言模型在复杂推理任务中,由于推理链过长导致的关键信息被稀释,模型无法有效关注重要步骤的问题。现有方法,如直接提示或链式提示,在长推理链中表现不佳,因为模型难以区分关键信息和噪声信息,导致推理错误。
核心思路:Self-Anchor的核心思路是利用推理过程的内在结构,将复杂的推理过程分解为一系列结构化的步骤,并引导模型将注意力集中在这些关键步骤上。通过显式地规划和对齐注意力,模型可以更好地理解推理过程,并减少无关信息的干扰。
技术框架:Self-Anchor包含两个主要阶段:计划阶段和执行阶段。在计划阶段,模型首先生成一个推理计划,该计划将整个推理过程分解为一系列步骤。在执行阶段,模型根据生成的计划,逐步执行每个步骤,并使用注意力机制将注意力集中在与当前步骤最相关的上下文信息上。整个过程通过迭代的方式进行,直到得到最终答案。
关键创新:Self-Anchor的关键创新在于其自动化的注意力对齐机制。与传统的注意力机制不同,Self-Anchor不是简单地计算所有上下文信息的注意力权重,而是根据推理计划,将注意力集中在与当前步骤最相关的上下文信息上。这种有针对性的注意力对齐可以显著提高模型的推理能力。
关键设计:Self-Anchor使用了一种特殊的提示模板来引导模型生成推理计划。该模板包含一系列指令,要求模型将推理过程分解为一系列步骤,并为每个步骤指定明确的目标。此外,Self-Anchor还使用了一种损失函数来鼓励模型将注意力集中在与当前步骤最相关的上下文信息上。该损失函数基于交叉熵,目标是最大化模型对相关信息的注意力权重。
🖼️ 关键图片

📊 实验亮点
Self-Anchor在六个基准测试中均优于现有的最佳提示方法。例如,在某些基准测试中,Self-Anchor的性能提升超过10%。更重要的是,Self-Anchor显著缩小了通用LLM与专用推理模型之间的性能差距,表明该方法具有很强的通用性和有效性。实验结果表明,Self-Anchor能够有效地提高大语言模型的推理能力,使其能够更好地处理复杂的推理任务。
🎯 应用场景
Self-Anchor具有广泛的应用前景,可应用于问答系统、代码生成、数学问题求解等需要复杂推理的任务。该方法可以提升大语言模型在这些任务上的准确性和可靠性,使其能够更好地服务于实际应用。未来,Self-Anchor还可以与其他技术相结合,例如知识图谱、外部工具等,进一步增强大语言模型的推理能力。
📄 摘要(原文)
To solve complex reasoning tasks for Large Language Models (LLMs), prompting-based methods offer a lightweight alternative to fine-tuning and reinforcement learning. However, as reasoning chains extend, critical intermediate steps and the original prompt will be buried in the context, receiving insufficient attention and leading to errors. In this paper, we propose Self-Anchor, a novel pipeline that leverages the inherent structure of reasoning to steer LLM attention. Self-Anchor decomposes reasoning trajectories into structured plans and automatically aligns the model's attention to the most relevant inference steps, allowing the model to maintain focus throughout generation. Our experiment shows that Self-Anchor outperforms SOTA prompting methods across six benchmarks. Notably, Self-Anchor significantly reduces the performance gap between ``non-reasoning'' models and specialized reasoning models, with the potential to enable most LLMs to tackle complex reasoning tasks without retraining.