FocusAgent: Simple Yet Effective Ways of Trimming the Large Context of Web Agents
作者: Imene Kerboua, Sahar Omidi Shayegan, Megh Thakkar, Xing Han Lù, Léo Boisvert, Massimo Caccia, Jérémy Espinas, Alexandre Aussem, Véronique Eglin, Alexandre Lacoste
分类: cs.CL
发布日期: 2025-10-03
💡 一句话要点
FocusAgent:利用轻量级LLM检索,有效精简Web Agent上下文,提升效率与安全性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Web Agent 大型语言模型 上下文剪枝 信息检索 提示注入攻击 可访问性树 安全性
📋 核心要点
- Web Agent面临处理海量网页信息的挑战,现有剪枝方法效果不佳,影响效率和安全性。
- FocusAgent利用轻量级LLM检索器,根据任务目标从网页可访问性树中提取关键信息。
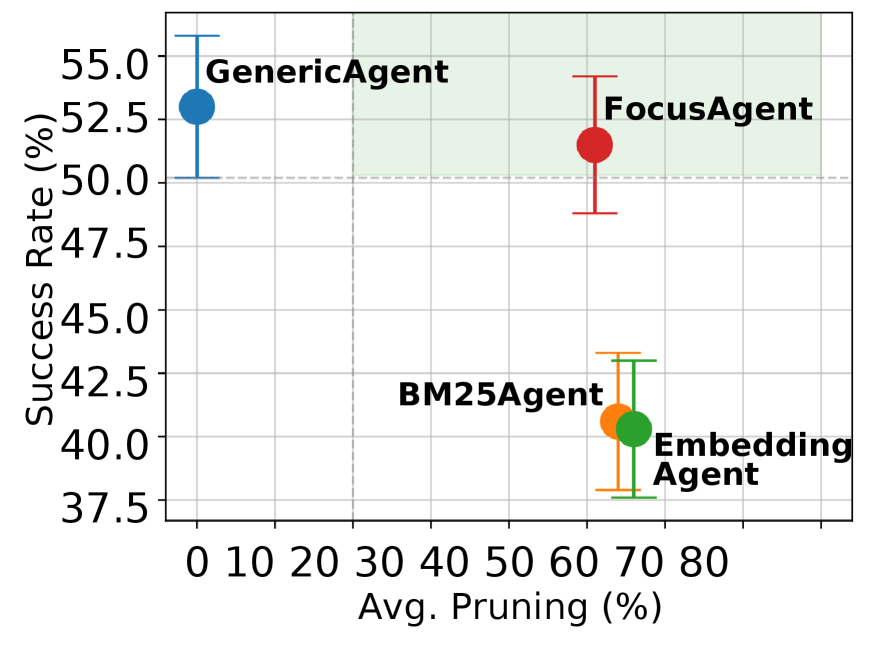
- 实验表明,FocusAgent在保持性能的同时,显著减少了观察大小,并降低了提示注入攻击的成功率。
📝 摘要(中文)
基于大型语言模型(LLM)的Web Agent需要处理冗长的网页信息以完成用户目标,这些页面通常包含数万个token,超出上下文限制并增加计算成本。此外,处理完整页面还会使Agent面临提示注入等安全风险。现有的剪枝策略要么丢弃相关内容,要么保留不相关的上下文,导致次优的动作预测。我们提出了FocusAgent,一种简单而有效的方法,它利用轻量级LLM检索器,在任务目标的指导下,从可访问性树(AxTree)观察中提取最相关的行。通过修剪噪声和不相关的内容,FocusAgent能够实现高效推理,同时降低受到注入攻击的风险。在WorkArena和WebArena基准测试上的实验表明,FocusAgent在将观察大小减少50%以上的同时,匹配了强大基线的性能。此外,FocusAgent的一个变体显著降低了提示注入攻击(包括横幅和弹出窗口攻击)的成功率,同时保持了无攻击设置下的任务成功性能。我们的结果表明,有针对性的基于LLM的检索是构建高效、有效和安全的Web Agent的一种实用且稳健的策略。
🔬 方法详解
问题定义:Web Agent需要处理大量网页内容以完成任务,但现有方法要么丢弃关键信息,要么保留过多无关信息,导致效率低下、易受攻击。现有剪枝策略无法有效区分相关和不相关的内容,影响了Agent的决策质量和安全性。
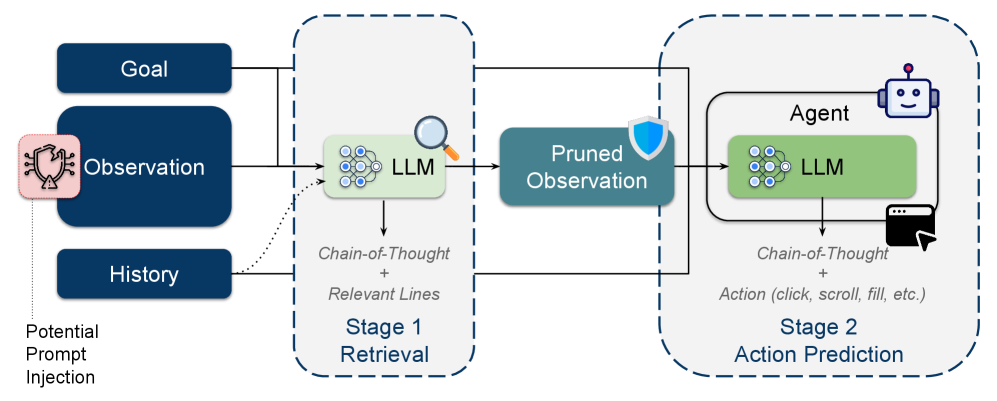
核心思路:FocusAgent的核心思路是利用轻量级LLM作为检索器,根据当前任务目标,从网页的可访问性树(AxTree)中提取最相关的文本行。通过这种方式,Agent可以专注于关键信息,避免被噪声干扰,从而提高效率和安全性。
技术框架:FocusAgent的整体框架包括以下几个主要步骤:1) 获取网页的可访问性树(AxTree);2) 使用轻量级LLM检索器,根据任务目标,从AxTree中提取最相关的文本行;3) 将提取的文本行作为Agent的输入,进行后续的决策和动作执行。该框架的关键在于LLM检索器的设计和训练。
关键创新:FocusAgent的关键创新在于利用轻量级LLM进行上下文感知的信息检索。与传统的基于规则或关键词的剪枝方法不同,FocusAgent能够理解任务目标,并根据目标动态地选择相关信息。这种方法能够更准确地识别和保留关键信息,同时去除噪声和冗余信息。
关键设计:FocusAgent使用预训练的LLM(例如,BART或T5)作为检索器的基础模型,并使用对比学习方法进行微调。对比学习的目标是使检索器能够区分与任务目标相关的文本行和不相关的文本行。损失函数通常采用InfoNCE损失,鼓励检索器将相关的文本行嵌入到相似的空间中,并将不相关的文本行嵌入到不同的空间中。此外,还采用了负采样技术,以提高训练效率和效果。
🖼️ 关键图片

📊 实验亮点
实验结果表明,FocusAgent在WorkArena和WebArena基准测试中,在将观察大小减少50%以上的同时,匹配了强大基线的性能。此外,FocusAgent的一个变体显著降低了提示注入攻击的成功率,包括横幅和弹出窗口攻击,同时保持了无攻击设置下的任务成功性能。例如,针对横幅攻击,成功率从50%以上降低到10%以下。
🎯 应用场景
FocusAgent可应用于各种需要Web Agent与网页交互的场景,例如自动化网页浏览、信息提取、在线购物助手等。该方法能够提高Agent的效率和安全性,降低计算成本,并减少Agent受到恶意攻击的风险。未来,FocusAgent可以扩展到其他类型的Agent,例如对话Agent和机器人Agent。
📄 摘要(原文)
Web agents powered by large language models (LLMs) must process lengthy web page observations to complete user goals; these pages often exceed tens of thousands of tokens. This saturates context limits and increases computational cost processing; moreover, processing full pages exposes agents to security risks such as prompt injection. Existing pruning strategies either discard relevant content or retain irrelevant context, leading to suboptimal action prediction. We introduce FocusAgent, a simple yet effective approach that leverages a lightweight LLM retriever to extract the most relevant lines from accessibility tree (AxTree) observations, guided by task goals. By pruning noisy and irrelevant content, FocusAgent enables efficient reasoning while reducing vulnerability to injection attacks. Experiments on WorkArena and WebArena benchmarks show that FocusAgent matches the performance of strong baselines, while reducing observation size by over 50%. Furthermore, a variant of FocusAgent significantly reduces the success rate of prompt-injection attacks, including banner and pop-up attacks, while maintaining task success performance in attack-free settings. Our results highlight that targeted LLM-based retrieval is a practical and robust strategy for building web agents that are efficient, effective, and secure.