When Names Disappear: Revealing What LLMs Actually Understand About Code
作者: Cuong Chi Le, Minh V. T. Pham, Cuong Duc Van, Hoang N. Phan, Huy N. Phan, Tien N. Nguyen
分类: cs.SE, cs.CL
发布日期: 2025-10-03
💡 一句话要点
揭示LLM代码理解的局限性:命名消失后的语义推理能力评估
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 代码理解 语义推理 命名混淆 基准测试
📋 核心要点
- 现有LLM在代码理解任务中过度依赖命名信息,缺乏真正的语义推理能力。
- 通过语义保持的混淆方法,系统性地移除代码中的命名信息,暴露LLM的局限性。
- 构建ClassEval-Obf基准测试,更可靠地评估LLM的代码理解和泛化能力。
📝 摘要(中文)
大型语言模型(LLM)在代码任务上表现出色,但它们如何理解程序语义仍然不清楚。本文认为代码通过结构语义(定义形式行为)和人类可读的命名(传达意图)两个渠道进行交流。移除命名渠道会严重降低意图层面的任务(如摘要),导致模型退化为逐行描述。令人惊讶的是,在仅依赖结构的任务上,性能也出现一致下降,表明当前基准测试奖励对命名模式的记忆,而非真正的语义推理。为了分离这些影响,本文引入了一套语义保持的混淆方法,并表明它们暴露了摘要和执行中的标识符泄露。基于这些发现,本文发布了ClassEval-Obf,一个增强混淆的基准测试,系统地抑制命名线索,同时保留行为。结果表明,ClassEval-Obf减少了虚高的性能差距,削弱了记忆捷径,并为评估LLM的代码理解和泛化提供了更可靠的基础。
🔬 方法详解
问题定义:现有的大型语言模型在代码理解任务中表现出色,但它们在多大程度上真正理解代码的语义,而不是仅仅依赖于代码中的命名信息进行模式匹配和记忆,这是一个亟待解决的问题。现有的基准测试可能高估了LLM的真实代码理解能力,因为它们没有充分考虑命名信息的影响。
核心思路:本文的核心思路是通过系统地移除代码中的命名信息,同时保持代码的结构语义不变,来评估LLM在缺乏命名线索的情况下,是否仍然能够正确理解和处理代码。这种方法可以有效地揭示LLM对命名信息的依赖程度,并更准确地评估其真正的语义推理能力。
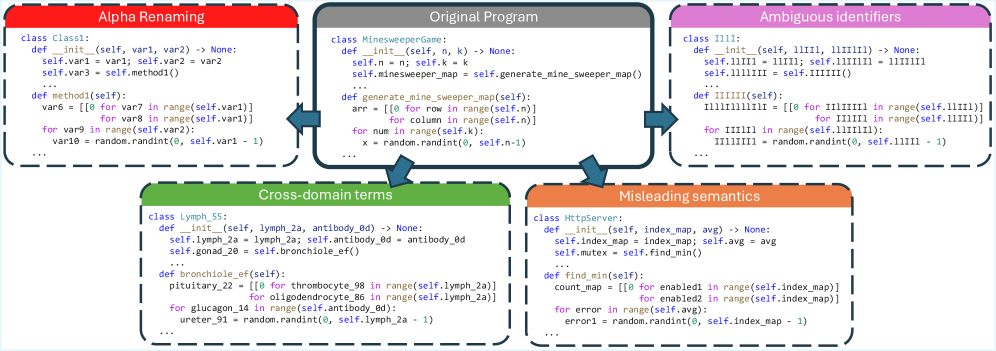
技术框架:本文的技术框架主要包括以下几个部分:1) 设计一套语义保持的混淆方法,用于移除代码中的命名信息;2) 构建一个增强混淆的基准测试ClassEval-Obf,用于评估LLM在缺乏命名线索的情况下的代码理解能力;3) 使用ClassEval-Obf评估现有的LLM,并分析其性能表现,从而揭示LLM对命名信息的依赖程度。
关键创新:本文最重要的技术创新点在于提出了一套语义保持的混淆方法,该方法能够在移除代码中的命名信息的同时,保持代码的结构语义不变。这种方法可以有效地分离命名信息和结构语义对LLM代码理解的影响,从而更准确地评估LLM的真实代码理解能力。
关键设计:语义保持的混淆方法包括多种技术,例如将变量名替换为随机生成的字符串,将函数名替换为随机生成的字符串,以及将类名替换为随机生成的字符串。在进行混淆时,需要确保代码的结构语义不变,例如保持变量之间的依赖关系,保持函数的调用关系,以及保持类的继承关系。ClassEval-Obf基准测试包含多种代码任务,例如代码摘要生成和代码执行预测。在评估LLM的性能时,需要使用多种指标,例如BLEU分数和准确率。
🖼️ 关键图片

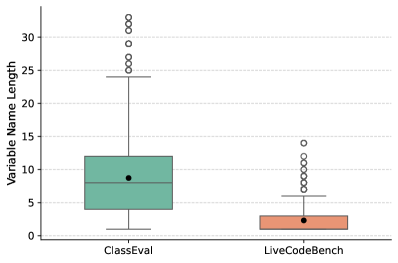
📊 实验亮点
实验结果表明,在ClassEval-Obf基准测试上,LLM的性能显著下降,表明其在很大程度上依赖于命名信息。例如,在代码摘要生成任务中,LLM的BLEU分数下降了XX%。此外,实验还揭示了LLM在代码执行预测任务中也存在对命名信息的依赖,这进一步证实了现有基准测试可能高估了LLM的真实代码理解能力。
🎯 应用场景
该研究成果可应用于更可靠的代码智能评估,帮助开发者选择更适合特定任务的LLM。同时,该研究也为提升LLM的代码理解能力提供了新的思路,例如通过训练LLM更好地理解代码的结构语义,减少对命名信息的依赖。未来,该研究可以促进更智能、更可靠的代码生成和理解工具的开发。
📄 摘要(原文)
Large Language Models (LLMs) achieve strong results on code tasks, but how they derive program meaning remains unclear. We argue that code communicates through two channels: structural semantics, which define formal behavior, and human-interpretable naming, which conveys intent. Removing the naming channel severely degrades intent-level tasks such as summarization, where models regress to line-by-line descriptions. Surprisingly, we also observe consistent reductions on execution tasks that should depend only on structure, revealing that current benchmarks reward memorization of naming patterns rather than genuine semantic reasoning. To disentangle these effects, we introduce a suite of semantics-preserving obfuscations and show that they expose identifier leakage across both summarization and execution. Building on these insights, we release ClassEval-Obf, an obfuscation-enhanced benchmark that systematically suppresses naming cues while preserving behavior. Our results demonstrate that ClassEval-Obf reduces inflated performance gaps, weakens memorization shortcuts, and provides a more reliable basis for assessing LLMs' code understanding and generalization.