Topic Modeling as Long-Form Generation: Can Long-Context LLMs revolutionize NTM via Zero-Shot Prompting?
作者: Xuan Xu, Haolun Li, Zhongliang Yang, Beilin Chu, Jia Song, Moxuan Xu, Linna Zhou
分类: cs.CL, cs.AI
发布日期: 2025-10-03
💡 一句话要点
提出基于长文本生成范式的LLM主题建模方法,通过零样本提示超越传统NTM模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 主题建模 大型语言模型 零样本学习 长文本生成 神经主题模型
📋 核心要点
- 传统神经主题模型依赖于推理和生成网络学习潜在主题分布,存在训练复杂和主题质量受限等问题。
- 论文提出将主题建模视为长文本生成任务,利用LLM的强大生成能力,通过零样本提示直接生成主题和代表性文本。
- 实验表明,基于LLM的长文本生成方法在主题质量上优于传统的神经主题模型,验证了LLM在主题建模领域的潜力。
📝 摘要(中文)
本文探索了大型语言模型时代主题建模的新范式,将主题建模定义为长文本生成任务。我们提出了一种简单而实用的方法,可以开箱即用地实现基于LLM的主题建模任务(采样数据子集,使用我们的提示生成主题和代表性文本,通过关键词匹配进行文本分配)。然后,我们研究了长文本生成范式是否可以通过零样本提示击败神经主题模型(NTM)。我们对NTM和LLM在主题质量方面进行了系统比较,并实证检验了“大多数NTM已经过时”的说法。
🔬 方法详解
问题定义:传统主题模型,特别是神经主题模型(NTM),依赖于复杂的推理和生成网络来学习潜在的主题分布。这些模型通常需要大量的训练数据和精细的架构设计,并且在主题质量方面存在局限性。现有的NTM模型可能已经无法充分利用最新的语言模型技术,面临着被淘汰的风险。
核心思路:论文的核心思路是将主题建模任务重新定义为长文本生成任务。利用大型语言模型(LLM)强大的文本生成能力,通过简单的零样本提示,直接生成主题和代表性文本,从而避免了传统NTM模型复杂的训练过程和架构设计。这种方法的核心在于利用LLM的先验知识和泛化能力,实现高效且高质量的主题建模。
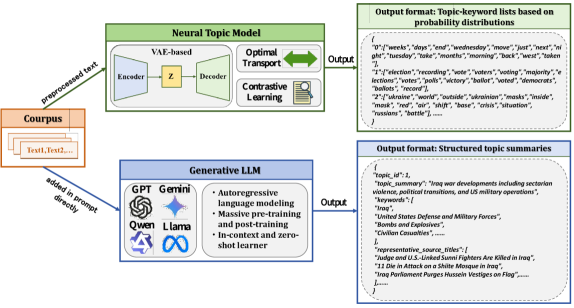
技术框架:该方法主要包含以下几个阶段:1. 数据采样:从原始文本数据集中抽取一个子集作为输入。2. 主题生成:使用预定义的提示(prompt)引导LLM生成主题和代表性文本。提示的设计至关重要,需要清晰地定义主题建模的目标和约束。3. 文本分配:将原始文本分配到最相关的主题。论文采用关键词匹配的方法,将文本分配给包含最多关键词的主题。
关键创新:最重要的技术创新点在于将主题建模任务转化为长文本生成任务,并利用LLM的零样本学习能力。与传统的NTM模型相比,该方法无需训练特定的主题模型,而是直接利用LLM的先验知识生成主题,从而大大简化了主题建模的流程。此外,该方法还能够生成更具可解释性和多样性的主题。
关键设计:关键的设计包括:1. 提示工程:设计有效的提示,引导LLM生成高质量的主题和代表性文本。提示需要清晰地定义主题建模的目标和约束,例如主题的数量、主题的粒度等。2. 文本分配策略:选择合适的文本分配策略,将原始文本分配到最相关的主题。论文采用关键词匹配的方法,但也可以考虑使用更复杂的文本相似度计算方法。
🖼️ 关键图片
📊 实验亮点
实验结果表明,基于LLM的长文本生成方法在主题质量上优于传统的神经主题模型。通过零样本提示,LLM能够生成更具可解释性和多样性的主题,并且能够更好地捕捉文本数据中的潜在语义信息。这表明LLM在主题建模领域具有巨大的潜力,有望取代传统的NTM模型。
🎯 应用场景
该研究成果可广泛应用于文本挖掘、信息检索、知识发现等领域。例如,可以用于自动生成新闻报道的主题标签,帮助用户快速了解新闻内容;可以用于分析用户评论,了解用户对产品的关注点;还可以用于构建知识图谱,挖掘文本数据中的潜在关系。该方法具有简单、高效、可扩展等优点,有望成为未来主题建模的主流方法。
📄 摘要(原文)
Traditional topic models such as neural topic models rely on inference and generation networks to learn latent topic distributions. This paper explores a new paradigm for topic modeling in the era of large language models, framing TM as a long-form generation task whose definition is updated in this paradigm. We propose a simple but practical approach to implement LLM-based topic model tasks out of the box (sample a data subset, generate topics and representative text with our prompt, text assignment with keyword match). We then investigate whether the long-form generation paradigm can beat NTMs via zero-shot prompting. We conduct a systematic comparison between NTMs and LLMs in terms of topic quality and empirically examine the claim that "a majority of NTMs are outdated."