EditLens: Quantifying the Extent of AI Editing in Text
作者: Katherine Thai, Bradley Emi, Elyas Masrour, Mohit Iyyer
分类: cs.CL
发布日期: 2025-10-03
💡 一句话要点
EditLens:量化文本中AI编辑程度,区分人写、AI生成和混合文本
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: AI编辑检测 文本相似度 中间监督学习 人机混合写作 作者身份归属
📋 核心要点
- 现有方法难以区分和量化AI对文本的编辑程度,尤其是在人机混合写作场景下。
- 提出EditLens模型,利用相似度指标量化AI编辑程度,并以此作为中间监督训练回归模型。
- 实验表明,EditLens在区分人写、AI生成和混合文本方面表现出色,F1值最高达94.7%。
📝 摘要(中文)
大量语言模型查询要求其编辑用户提供的文本,而非从头生成新文本。现有工作主要集中于检测完全由AI生成的文本,而本文证明了AI编辑过的文本与人类撰写和AI生成的文本是可区分的。首先,我们提出使用轻量级相似度指标来量化文本中AI编辑的程度,并使用人工标注员验证这些指标。然后,我们使用这些相似度指标作为中间监督,训练EditLens,一个回归模型,用于预测文本中存在的AI编辑量。我们的模型在区分人类、AI和混合写作的二元(F1=94.7%)和三元(F1=90.4%)分类任务中均取得了最先进的性能。我们不仅表明可以检测到AI编辑的文本,而且可以检测到AI对人类写作所做的更改程度,这对作者身份归属、教育和政策具有影响。最后,作为一个案例研究,我们使用我们的模型来分析Grammarly(一种流行的写作辅助工具)应用的AI编辑效果。为了鼓励进一步研究,我们承诺公开发布我们的模型和数据集。
🔬 方法详解
问题定义:论文旨在解决如何量化文本中AI编辑的程度,并区分人类撰写、AI生成以及AI编辑过的文本。现有方法主要集中于检测完全由AI生成的文本,而忽略了AI在人类写作基础上进行修改的情况,这在实际应用中更为常见,也更难检测。现有方法缺乏对AI编辑程度的量化,无法有效区分不同类型的文本。
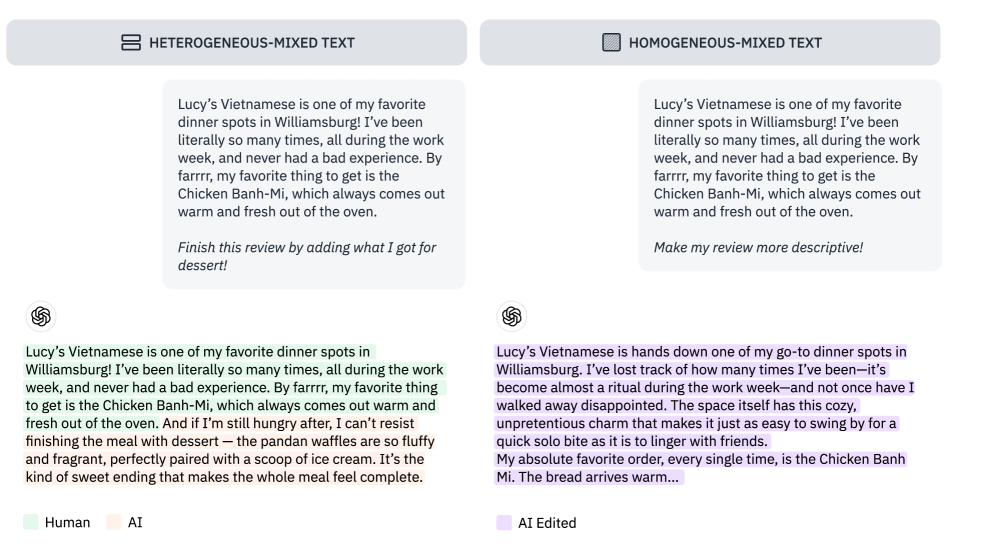
核心思路:论文的核心思路是利用文本相似度指标来量化AI编辑的程度。通过比较原始人类文本和经过AI编辑后的文本,计算它们之间的相似度得分,从而反映AI修改的幅度。这种方法基于一个假设:AI编辑的文本与原始文本的相似度越高,AI的修改程度就越小。
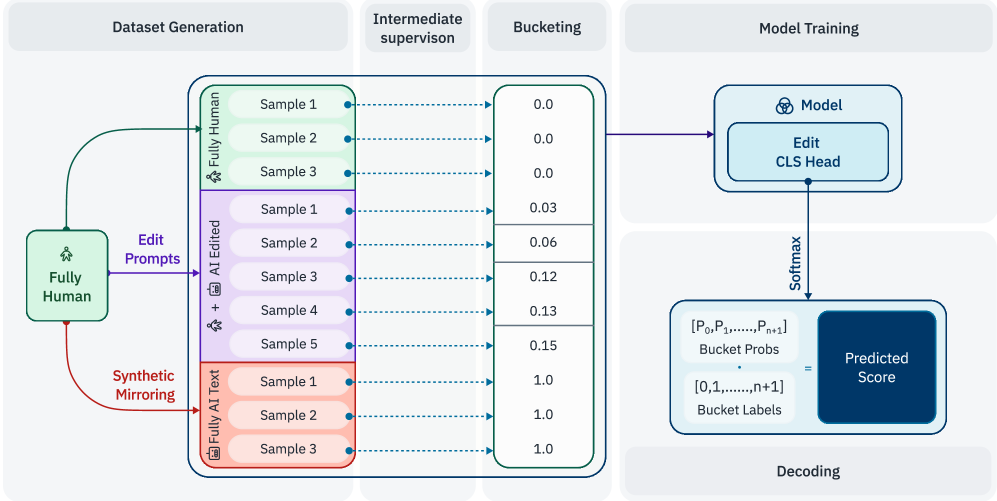
技术框架:EditLens的整体框架包含以下几个主要阶段:1) 使用轻量级相似度指标(如编辑距离、余弦相似度等)计算原始文本和AI编辑文本之间的相似度;2) 使用人工标注员验证这些相似度指标的有效性,确保它们能够准确反映AI编辑的程度;3) 将这些相似度指标作为中间监督信号,训练一个回归模型(EditLens),用于预测文本中存在的AI编辑量;4) 使用训练好的EditLens模型进行二元(人类 vs. AI/混合)和三元(人类 vs. AI vs. 混合)分类任务,评估其性能。
关键创新:论文的关键创新在于提出了使用相似度指标作为中间监督来量化AI编辑程度的方法。与以往直接训练分类器区分不同类型的文本不同,EditLens首先学习如何量化AI的修改幅度,然后再利用这些信息进行分类。这种方法更加细粒度,能够更好地捕捉AI编辑的特征。
关键设计:论文的关键设计包括:1) 选择合适的相似度指标,需要考虑计算效率和准确性;2) 设计有效的中间监督策略,确保相似度指标能够为回归模型提供有用的信息;3) 选择合适的回归模型结构,需要考虑模型的表达能力和泛化能力。论文使用了多种相似度指标,并进行了实验比较,最终选择了效果最好的指标组合。损失函数使用了均方误差(MSE)来衡量预测的AI编辑量与实际AI编辑量之间的差异。
🖼️ 关键图片

📊 实验亮点
EditLens模型在二元分类(人类 vs. AI/混合)和三元分类(人类 vs. AI vs. 混合)任务中均取得了最先进的性能,F1值分别达到94.7%和90.4%。案例研究表明,EditLens可以有效分析Grammarly等写作辅助工具的AI编辑效果。论文公开了模型和数据集,为后续研究提供了便利。
🎯 应用场景
该研究成果可应用于多个领域,包括:作者身份归属,帮助判断文本是否经过AI修改;教育领域,辅助评估学生作业的原创性;政策制定,为规范AI写作提供技术支持;写作辅助工具,例如Grammarly,可以利用该模型评估AI编辑的效果,并提供更个性化的建议。未来,该技术还可以扩展到其他类型的内容,如图像和视频。
📄 摘要(原文)
A significant proportion of queries to large language models ask them to edit user-provided text, rather than generate new text from scratch. While previous work focuses on detecting fully AI-generated text, we demonstrate that AI-edited text is distinguishable from human-written and AI-generated text. First, we propose using lightweight similarity metrics to quantify the magnitude of AI editing present in a text given the original human-written text and validate these metrics with human annotators. Using these similarity metrics as intermediate supervision, we then train EditLens, a regression model that predicts the amount of AI editing present within a text. Our model achieves state-of-the-art performance on both binary (F1=94.7%) and ternary (F1=90.4%) classification tasks in distinguishing human, AI, and mixed writing. Not only do we show that AI-edited text can be detected, but also that the degree of change made by AI to human writing can be detected, which has implications for authorship attribution, education, and policy. Finally, as a case study, we use our model to analyze the effects of AI-edits applied by Grammarly, a popular writing assistance tool. To encourage further research, we commit to publicly releasing our models and dataset.