Beyond the Final Layer: Intermediate Representations for Better Multilingual Calibration in Large Language Models
作者: Ej Zhou, Caiqi Zhang, Tiancheng Hu, Chengzu Li, Nigel Collier, Ivan Vulić, Anna Korhonen
分类: cs.CL
发布日期: 2025-10-03
💡 一句话要点
提出语言感知的层集成方法LACE,提升大语言模型在多语言环境下的校准性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 多语言 置信度校准 层集成 语言感知
📋 核心要点
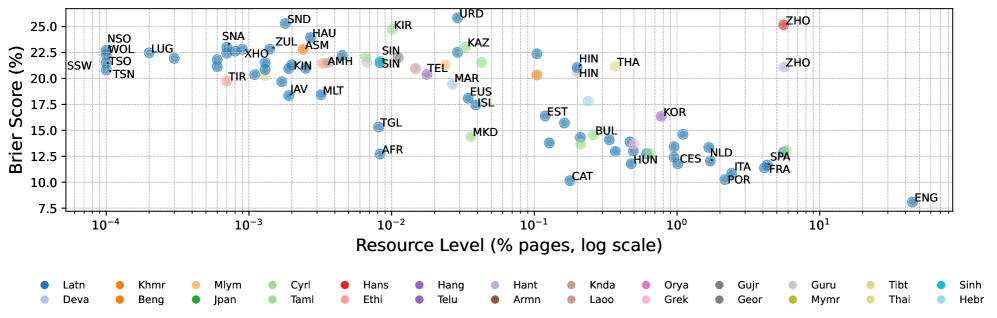
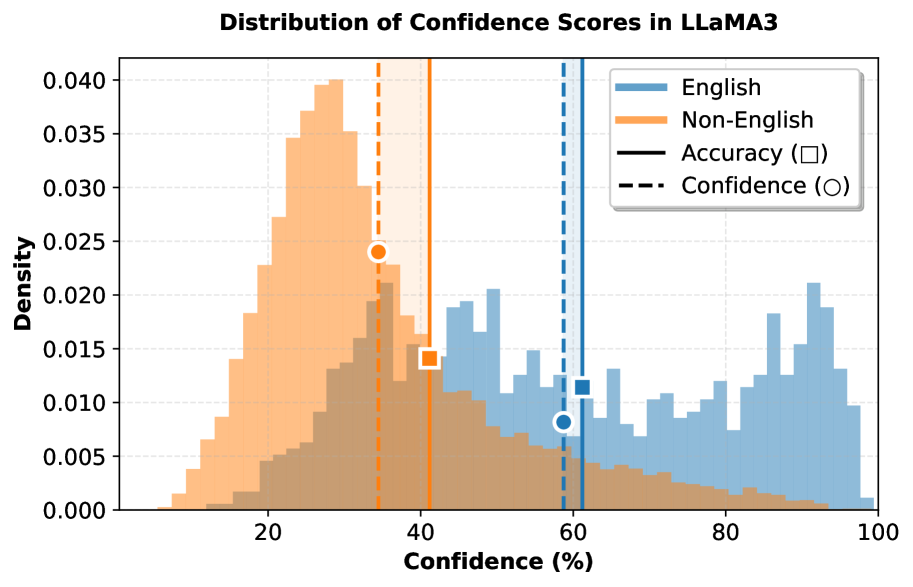
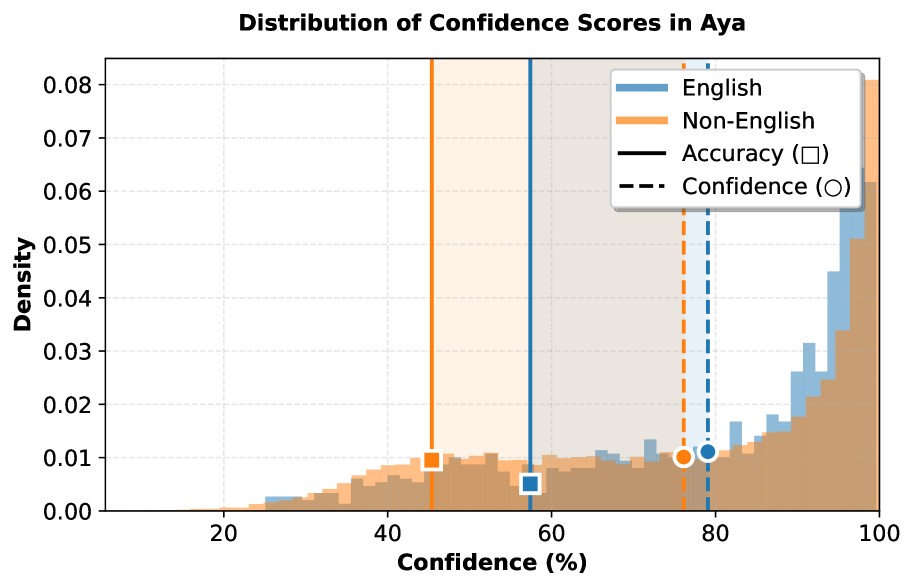
- 现有大语言模型在多语言环境下的置信度校准不足,尤其是在非英语语言上表现更差。
- 论文提出语言感知的置信度集成方法LACE,通过自适应地选择不同层的输出来提升校准性能。
- 实验表明,LACE方法在多种语言上显著提升了模型的校准性能,无需额外的训练。
📝 摘要(中文)
置信度校准,即模型预测置信度与其真实准确率的一致性,对于大语言模型(LLMs)的可靠部署至关重要。然而,在多语言环境中,这一关键属性在很大程度上尚未被充分研究。本文首次对六个模型家族和100多种语言进行了大规模、系统的多语言校准研究,揭示了非英语语言的校准性能系统性地更差。为了诊断这个问题,我们研究了模型的内部表示,发现受以英语为中心的训练影响,最后一层为多语言置信度提供了较差的信号。相比之下,我们的逐层分析揭示了一个关键见解,即较晚的中间层始终提供更可靠和更好校准的信号。在此基础上,我们引入了一套无需训练的方法,包括语言感知置信度集成(LACE),它自适应地为每种特定语言选择最佳的层集成。我们的研究突出了以英语为中心的对齐的隐藏成本,并通过关注最后一层之外的层,为构建更具全球公平性和可信赖的LLM提供了一条新途径。
🔬 方法详解
问题定义:论文旨在解决大语言模型在多语言环境下置信度校准不足的问题。现有方法主要依赖模型的最后一层输出进行置信度评估,但由于模型训练数据偏向英语,导致最后一层输出对于非英语语言的置信度估计不准确,从而影响模型在多语言环境下的可靠性。
核心思路:论文的核心思路是,模型的不同层包含不同层次的语言信息,而中间层可能包含更适合多语言置信度校准的信息。因此,通过集成不同层的输出来提升整体的置信度校准性能。论文假设,通过语言感知的自适应选择,可以找到对于特定语言最优的层集成方式。
技术框架:论文提出的方法主要包含以下几个阶段:1) 对大语言模型的每一层进行置信度评估;2) 使用验证集数据,针对每种语言,学习一个层选择策略,该策略决定如何集成不同层的置信度估计;3) 在测试阶段,使用学习到的层选择策略,对不同层的置信度估计进行加权平均,得到最终的置信度估计。
关键创新:论文的关键创新在于:1) 首次系统性地研究了大语言模型在多语言环境下的置信度校准问题;2) 提出了语言感知的层集成方法LACE,该方法可以自适应地为每种语言选择最佳的层集成方式,从而提升校准性能;3) 该方法无需额外的训练,可以直接应用于现有的预训练大语言模型。
关键设计:LACE方法的关键设计包括:1) 使用温度缩放(Temperature Scaling)对每一层的输出进行校准;2) 使用验证集数据学习一个线性权重,用于集成不同层的校准后的输出;3) 针对每种语言,独立学习一个权重向量,从而实现语言感知的层选择。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LACE方法在多种语言上显著提升了模型的校准性能。例如,在某些语言上,LACE方法可以将模型的Expected Calibration Error (ECE) 降低 10% 以上。此外,LACE方法在不同的模型家族上都表现出良好的泛化能力,证明了其有效性和通用性。
🎯 应用场景
该研究成果可应用于任何需要大语言模型提供可靠置信度估计的多语言场景,例如多语言信息检索、机器翻译质量评估、跨语言情感分析等。通过提升模型在非英语语言上的校准性能,可以提高模型在这些场景下的可靠性和公平性,从而促进更广泛的语言覆盖和更公平的人工智能应用。
📄 摘要(原文)
Confidence calibration, the alignment of a model's predicted confidence with its actual accuracy, is crucial for the reliable deployment of Large Language Models (LLMs). However, this critical property remains largely under-explored in multilingual contexts. In this work, we conduct the first large-scale, systematic studies of multilingual calibration across six model families and over 100 languages, revealing that non-English languages suffer from systematically worse calibration. To diagnose this, we investigate the model's internal representations and find that the final layer, biased by English-centric training, provides a poor signal for multilingual confidence. In contrast, our layer-wise analysis uncovers a key insight that late-intermediate layers consistently offer a more reliable and better-calibrated signal. Building on this, we introduce a suite of training-free methods, including Language-Aware Confidence Ensemble (LACE), which adaptively selects an optimal ensemble of layers for each specific language. Our study highlights the hidden costs of English-centric alignment and offer a new path toward building more globally equitable and trustworthy LLMs by looking beyond the final layer.