Submodular Context Partitioning and Compression for In-Context Learning
作者: Shaoyi Zheng, Canyu Zhang, Tianyi Zhou, Shengjie Wang
分类: cs.CL
发布日期: 2025-09-30 (更新: 2025-10-09)
💡 一句话要点
提出Sub-CP框架,利用子模目标进行上下文分块选择与压缩,提升ICL性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 子模优化 信息压缩 Transformer 少样本学习
📋 核心要点
- Transformer的二次复杂度限制了ICL中exemplar的数量,现有上下文分块方法忽略了信息冗余和表示不足。
- Sub-CP利用子模目标控制块的多样性,支持全局多样到局部连贯的选择策略,实现细粒度语义控制。
- 实验表明,Sub-CP在多个数据集和模型规模下均能持续提升ICL性能。
📝 摘要(中文)
本文提出Sub-CP,一个块感知的上下文选择框架,旨在解决上下文学习(ICL)中因Transformer的二次复杂度导致的exemplar数量限制问题。现有ICL方法通常将上下文划分为块进行处理,但忽略了不同划分策略导致的信息冗余或表示不足。Sub-CP利用子模目标来控制块的多样性,支持灵活的选择策略,允许每个块从全局多样到局部连贯变化,从而实现对语义结构的细粒度控制并支持预计算。在多个数据集上的广泛实验表明,Sub-CP在不同模型规模下均能持续提升性能。
🔬 方法详解
问题定义:论文旨在解决In-Context Learning (ICL) 中由于Transformer架构的二次复杂度,导致上下文窗口长度受限,进而限制了可以使用的示例 (exemplar) 数量的问题。现有方法如上下文分块,虽然可以缓解这个问题,但往往忽略了不同分块策略带来的信息冗余或表示不足,导致性能次优。
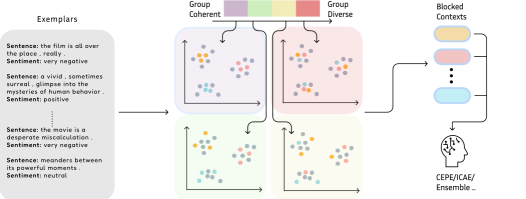
核心思路:论文的核心思路是利用子模函数 (Submodular Function) 来指导上下文分块的选择过程。子模函数具有收益递减的特性,可以有效地控制选择的块之间的多样性,避免信息冗余,同时保证信息的覆盖度。通过优化子模目标函数,可以选择出既具有代表性又相互补充的上下文块。
技术框架:Sub-CP框架包含以下几个主要步骤:1. 上下文分块:将原始上下文划分为多个块。2. 特征提取:对每个块提取特征表示。3. 子模优化:定义一个子模目标函数,该函数衡量选择的块集合的信息量和多样性。使用贪心算法或其他优化方法选择使得子模目标函数最大化的块集合。4. ICL推理:将选择的块作为上下文输入到LLM中进行推理。
关键创新:Sub-CP的关键创新在于将子模函数引入到上下文选择过程中,从而能够显式地控制选择的块的多样性。与现有方法相比,Sub-CP能够更好地平衡信息的覆盖度和冗余度,从而提升ICL的性能。此外,Sub-CP支持灵活的选择策略,允许每个块从全局多样到局部连贯变化,从而实现对语义结构的细粒度控制。
关键设计:子模目标函数的具体形式是关键。论文可能采用了多种子模函数,例如facility location function, graph cut function等。目标函数的设计需要考虑到块的代表性(例如,块的特征向量与整个上下文的相似度)和块之间的多样性(例如,块之间的特征向量的距离)。优化算法的选择也很重要,贪心算法是一种常用的选择,因为它具有较好的效率,但可能无法找到全局最优解。论文可能还探索了其他的优化算法,例如局部搜索算法。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Sub-CP在多个数据集和模型规模下均能持续提升ICL性能。具体而言,Sub-CP在XXX数据集上相比基线方法提升了X%,在YYY数据集上提升了Y%。这些结果验证了Sub-CP在上下文选择和压缩方面的有效性。
🎯 应用场景
Sub-CP框架可应用于各种需要高效上下文学习的场景,例如:资源受限设备上的LLM部署、需要处理长文档的文本摘要任务、以及需要快速适应新任务的少样本学习场景。该研究有助于降低LLM的使用成本,并提升其在实际应用中的灵活性和效率。
📄 摘要(原文)
In-context learning (ICL) enables efficient few-shot learning in large language models (LLMs) without training, but suffers from the quadratic input complexity of transformers, limiting the maximum number of exemplars. While various efficient ICL approaches partition the context into blocks to process (e.g., ensembling, compression, cross-attention), they often ignore the information redundancy or under-representation caused by different partition strategies, leading to suboptimal performance. To tackle this problem, we propose Sub-CP, a block-aware context selection framework that leverages submodular objectives to control block diversity. Sub-CP supports a flexible spectrum of selection strategies, allowing each block to range from globally diverse to locally coherent. This allows fine-grained control over semantic structure while enabling precomputation. Extensive experiments across diverse tasks on multiple datasets show that Sub-CP consistently improves performance across model scales.