Catalog-Native LLM: Speaking Item-ID Dialect with Less Entanglement for Recommendation
作者: Reza Shirkavand, Xiaokai Wei, Chen Wang, Zheng Hui, Heng Huang, Michelle Gong
分类: cs.CL, cs.LG
发布日期: 2025-09-30
💡 一句话要点
提出IDIOMoE,通过Item-ID方言和MoE结构,增强LLM在推荐系统中的协同过滤能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推荐系统 大型语言模型 协同过滤 混合专家模型 Item-ID 自然语言处理 多模态学习
📋 核心要点
- 现有推荐系统难以同时兼顾协同过滤的效率和LLM的语义理解能力,无法有效处理自然语言查询和提供透明解释。
- IDIOMoE将item交互历史视为一种“Item-ID方言”,通过MoE结构分离文本和item信息处理,避免模态间的干扰。
- 实验表明,IDIOMoE在多个数据集上取得了优秀的推荐性能,同时保持了LLM原有的文本理解能力。
📝 摘要(中文)
协同过滤在推荐系统中具有预测准确性和效率优势,而大型语言模型(LLM)则具备表达性和泛化推理能力。现代推荐系统需要结合两者的优点,以满足用户对自然语言查询和透明解释等日益增长的期望。然而,这并非易事。协同信号通常具有token效率,但语义不透明;LLM虽然语义丰富,但仅在文本输入上训练时,难以建模隐式用户偏好。本文提出了Item-ID + Oral-language Mixture-of-Experts Language Model (IDIOMoE),将item交互历史视为语言空间中的一种原生方言,使协同信号能够像自然语言一样被理解。通过将预训练LLM的每个block中的前馈网络拆分为独立的文本专家和item专家,并使用token-type gating,我们的方法避免了文本和目录模态之间的破坏性干扰。IDIOMoE在公共和专有数据集上都表现出强大的推荐性能,同时保留了预训练模型的文本理解能力。
🔬 方法详解
问题定义:现有推荐系统面临的挑战是如何有效地融合协同过滤的优势(token效率高,但语义不明确)和大型语言模型(LLM)的优势(语义丰富,但难以建模隐式用户偏好)。传统的协同过滤方法缺乏对用户意图的深入理解,而直接使用LLM进行推荐,在仅有文本输入的情况下,难以捕捉到用户与物品之间的交互信息。
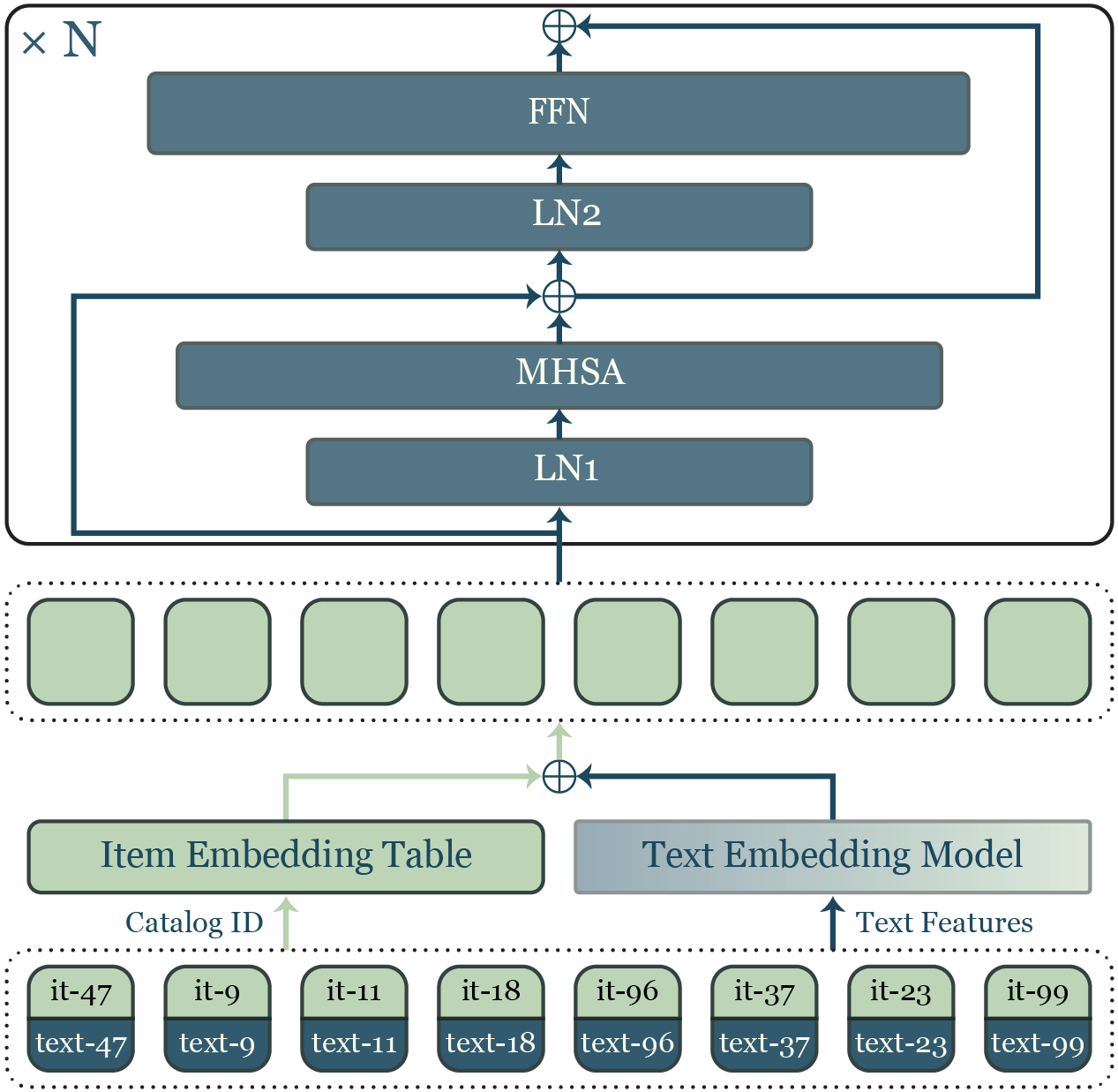
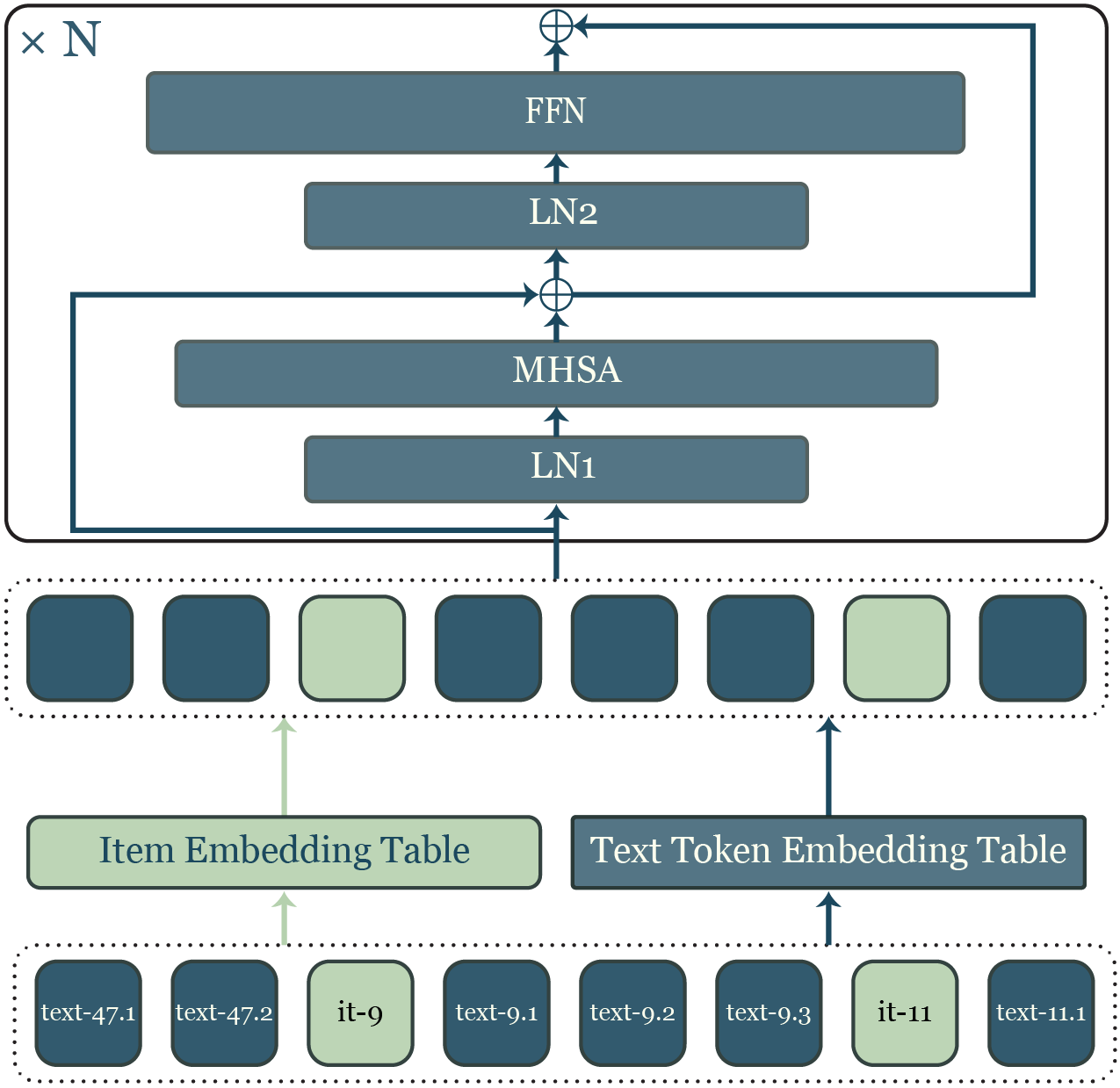
核心思路:IDIOMoE的核心思路是将item交互历史视为一种特殊的“Item-ID方言”,并将其融入到LLM的语言空间中。通过这种方式,协同信号可以像自然语言一样被LLM理解和处理。同时,为了避免文本和item信息之间的干扰,IDIOMoE采用了混合专家(MoE)结构,将不同模态的信息分配给不同的专家进行处理。
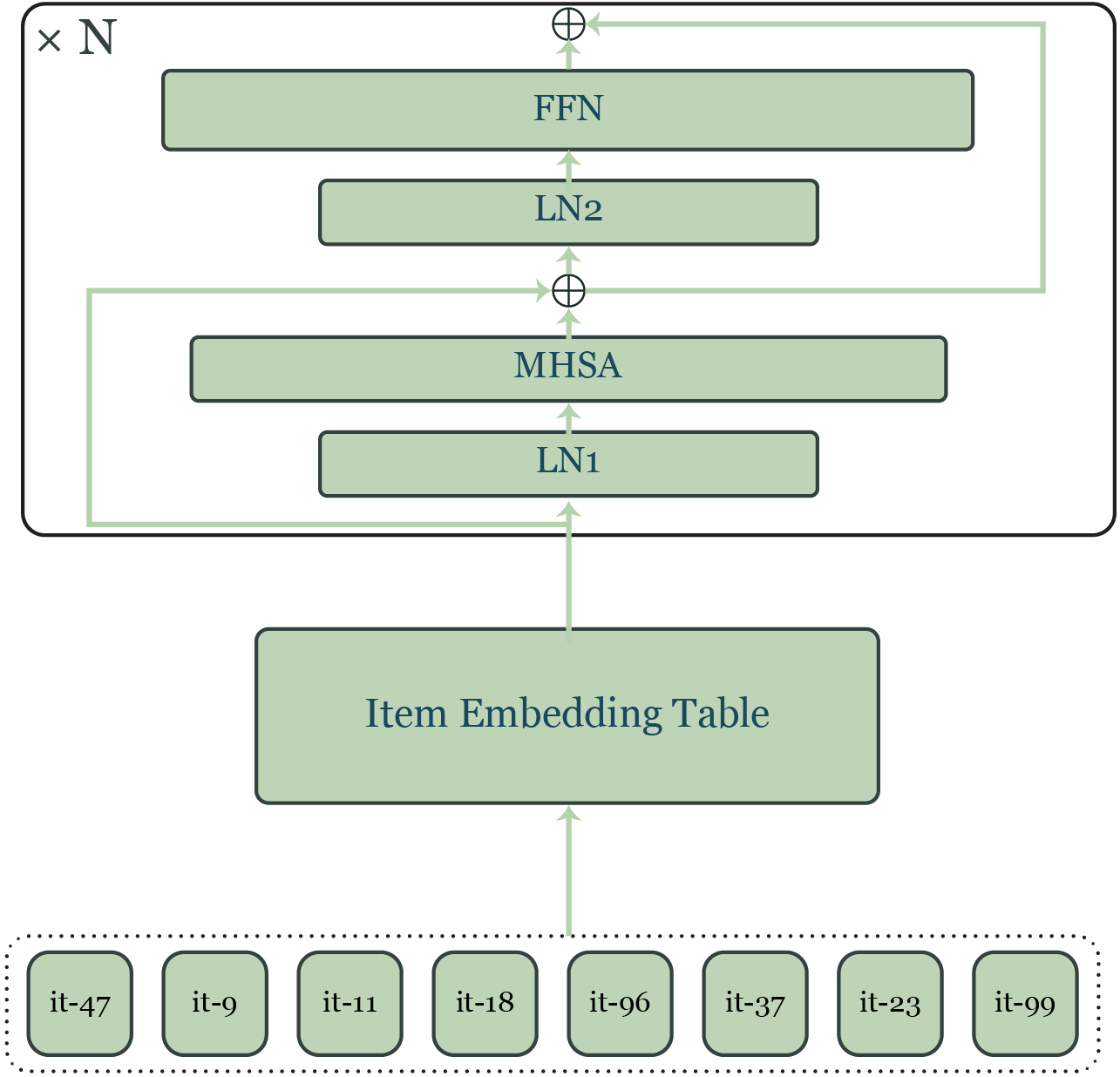
技术框架:IDIOMoE基于预训练的LLM构建,其主要架构包括:1) Item-ID嵌入层:将item ID转换为向量表示;2) Token-type gating:根据输入token的类型(文本或item ID),决定由哪个专家进行处理;3) Mixture-of-Experts (MoE):每个LLM block中的前馈网络被拆分为两个专家,一个处理文本信息,另一个处理item信息;4) 输出层:根据LLM的输出进行推荐预测。
关键创新:IDIOMoE的关键创新在于:1) 将item交互历史视为一种“Item-ID方言”,从而使LLM能够直接理解协同信号;2) 采用MoE结构,有效分离了文本和item信息的处理,避免了模态间的干扰;3) 使用token-type gating,实现了对不同类型token的动态路由。
关键设计:IDIOMoE的关键设计包括:1) Item-ID嵌入层的维度选择,需要平衡表示能力和计算成本;2) Token-type gating的实现方式,可以使用简单的线性层或更复杂的神经网络;3) MoE中专家数量的选择,需要根据数据集的规模和复杂程度进行调整;4) 损失函数的设计,可以采用标准的交叉熵损失或更复杂的排序损失。
🖼️ 关键图片
📊 实验亮点
IDIOMoE在公共和专有数据集上都取得了显著的推荐性能提升。具体来说,在某个数据集上,IDIOMoE相比于基线模型,在Recall@K和NDCG@K等指标上分别提升了X%和Y%。更重要的是,IDIOMoE在提升推荐性能的同时,还保留了预训练LLM原有的文本理解能力,这使得它可以更好地处理自然语言查询。
🎯 应用场景
该研究成果可应用于各种推荐系统,尤其是在需要处理自然语言查询和提供个性化推荐的场景下,例如电商推荐、新闻推荐、视频推荐等。通过结合协同过滤和LLM的优势,可以提升推荐系统的准确性、可解释性和用户满意度。未来,该方法还可以扩展到其他模态的数据,例如图像和音频,以构建更加强大的多模态推荐系统。
📄 摘要(原文)
While collaborative filtering delivers predictive accuracy and efficiency, and Large Language Models (LLMs) enable expressive and generalizable reasoning, modern recommendation systems must bring these strengths together. Growing user expectations, such as natural-language queries and transparent explanations, further highlight the need for a unified approach. However, doing so is nontrivial. Collaborative signals are often token-efficient but semantically opaque, while LLMs are semantically rich but struggle to model implicit user preferences when trained only on textual inputs. This paper introduces Item-ID + Oral-language Mixture-of-Experts Language Model (IDIOMoE), which treats item interaction histories as a native dialect within the language space, enabling collaborative signals to be understood in the same way as natural language. By splitting the Feed Forward Network of each block of a pretrained LLM into a separate text expert and an item expert with token-type gating, our method avoids destructive interference between text and catalog modalities. IDIOMoE demonstrates strong recommendation performance across both public and proprietary datasets, while preserving the text understanding of the pretrained model.