Uncertainty-Aware Answer Selection for Improved Reasoning in Multi-LLM Systems
作者: Aakriti Agrawal, Rohith Aralikatti, Anirudh Satheesh, Souradip Chakraborty, Amrit Singh Bedi, Furong Huang
分类: cs.CL, cs.LG
发布日期: 2025-09-30
💡 一句话要点
提出一种不确定性感知的答案选择方法,提升多LLM系统推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多LLM系统 答案选择 不确定性感知 对数似然 模型校准
📋 核心要点
- 现有方法在多LLM系统中选择最佳答案时,依赖昂贵的验证器或多次采样,效率较低。
- 该论文提出一种基于校准对数似然得分的方法,利用LLM的内在知识和置信度来选择答案。
- 实验表明,该方法在多个数据集上,相较于现有方法,性能提升显著,尤其是在辩论和非辩论场景。
📝 摘要(中文)
大型语言模型(LLM)展现了卓越的能力,但从多个LLM中选择最可靠的响应仍然是一个挑战,尤其是在资源受限的环境中。现有方法通常依赖于昂贵的外部验证器、人工评估员或需要从单个模型中进行多次采样的自洽性技术。虽然多LLM系统比单个模型产生更多样化的响应,因此具有更大的潜力,但它们通常不如单个LLM自洽性表现好。我们提出了一种有原则的、新颖的且计算高效的方法,使用校准的对数似然得分从多个不同的LLM中选择最佳响应,隐式地利用这些模型固有的知识和置信度。我们的方法在GSM8K、MMLU(6个子集)和ARC数据集的辩论(多轮LLM讨论)和非辩论(使用多个LLM的Best-of-N)设置中分别实现了约4%、3%和5%的改进。
🔬 方法详解
问题定义:现有方法在多LLM系统中选择最佳答案时,面临着资源消耗大和效率低下的问题。依赖外部验证器成本高昂,而自洽性方法需要对单个LLM进行多次采样,计算量大。这些方法无法有效利用多LLM系统提供的多样性信息,导致性能提升有限。
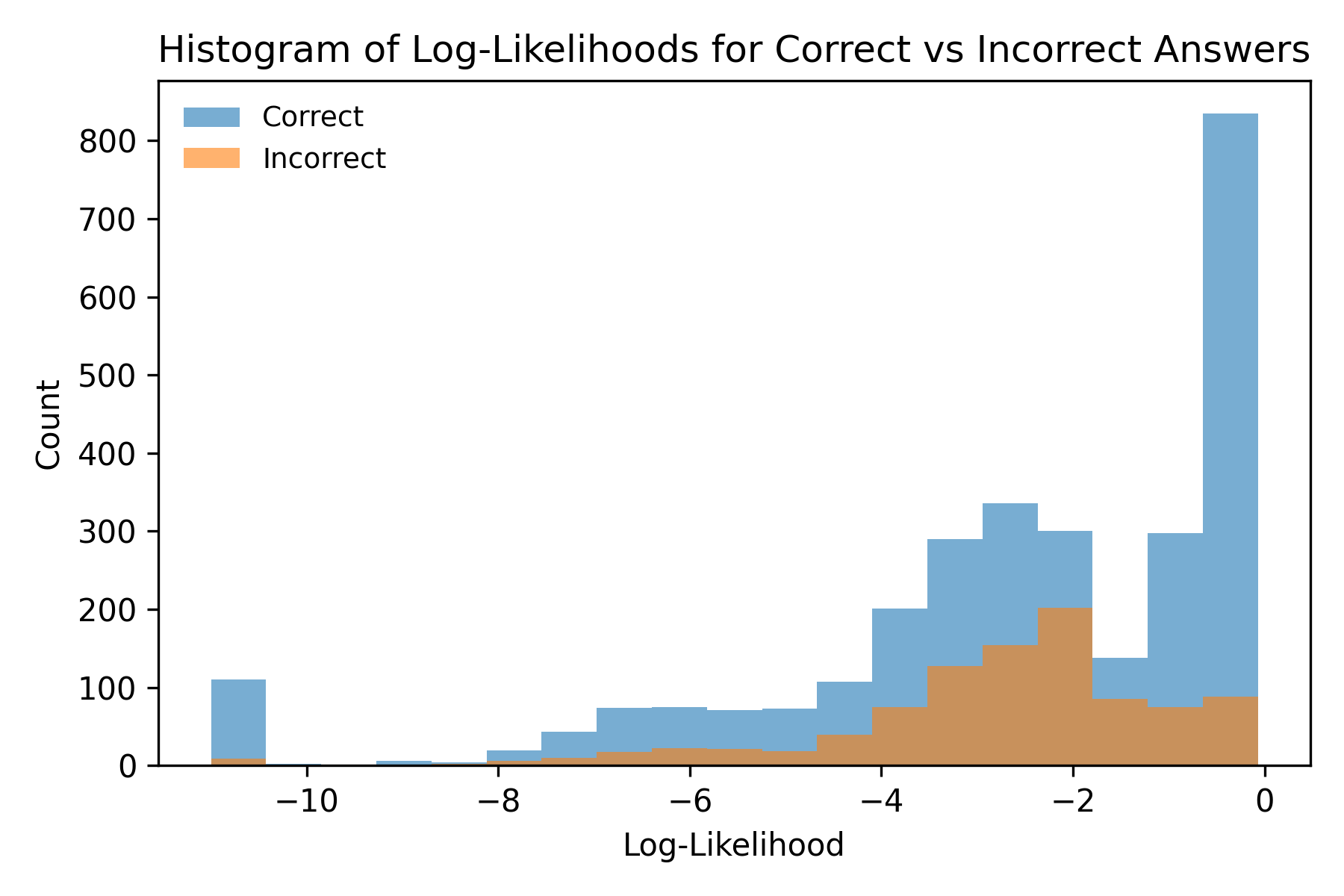
核心思路:该论文的核心思路是利用LLM自身提供的置信度信息,通过校准的对数似然得分来选择最佳答案。这种方法避免了外部验证和多次采样,从而提高了效率。核心假设是,LLM在生成答案时,其对数似然得分能够反映答案的质量和可靠性。
技术框架:该方法主要包含以下几个阶段:1) 使用多个不同的LLM生成答案;2) 计算每个LLM生成答案的对数似然得分;3) 对对数似然得分进行校准,以消除不同LLM之间的偏差;4) 选择具有最高校准对数似然得分的答案作为最终答案。整个流程无需额外的训练数据或外部知识。
关键创新:该方法最重要的技术创新点在于利用校准的对数似然得分来选择答案。与现有方法相比,该方法无需外部验证器或多次采样,从而显著提高了效率。此外,该方法能够有效利用多LLM系统提供的多样性信息,从而提升性能。
关键设计:对数似然得分的校准是关键设计之一。论文可能采用了温度缩放(Temperature Scaling)或直方图均衡化等方法来校准不同LLM的对数似然得分,以确保它们具有可比性。具体的校准方法和参数设置可能在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在GSM8K、MMLU和ARC数据集上均取得了显著的性能提升。在辩论和非辩论设置中,分别实现了约4%、3%和5%的改进。这些结果表明,该方法能够有效利用多LLM系统提供的多样性信息,并选择最可靠的答案。相较于依赖外部验证器或多次采样的现有方法,该方法具有更高的效率和更好的性能。
🎯 应用场景
该研究成果可广泛应用于需要多LLM协作的场景,例如智能问答系统、对话机器人、自动摘要等。通过选择最可靠的答案,可以提高系统的准确性和用户体验。该方法还可以应用于资源受限的环境,例如移动设备或边缘计算平台,因为其计算效率较高。未来,该方法可以进一步扩展到其他类型的任务和模型。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated exceptional capabilities, yet selecting the most reliable response from multiple LLMs remains a challenge, particularly in resource-constrained settings. Existing approaches often depend on costly external verifiers, human evaluators, or self-consistency techniques that require multiple samples from a single model. While multi-LLM systems produce more diverse responses than single models and thus have greater potential, they often underperform compared to single LLM self-consistency. We propose a principled, novel and computationally efficient method to select the best response from multiple different LLMs using a calibrated log-likelihood score, implicitly leveraging the inherent knowledge and confidence of these models. Our method demonstrates improvements of approx. 4%, 3%, and 5% across both debate (multi-round LLM discussions) and non-debate (Best-of-N with multiple LLMs) settings on GSM8K, MMLU (6 subsets), and ARC datasets respectively.