TUMIX: Multi-Agent Test-Time Scaling with Tool-Use Mixture
作者: Yongchao Chen, Jiefeng Chen, Rui Meng, Ji Yin, Na Li, Chuchu Fan, Chi Wang, Tomas Pfister, Jinsung Yoon
分类: cs.CL, cs.AI
发布日期: 2025-09-30
备注: 27 pages, 13 figures
💡 一句话要点
TUMIX:基于工具使用混合的多Agent测试时扩展方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 工具使用 多Agent系统 测试时扩展 集成学习
📋 核心要点
- 现有大型语言模型工具使用策略缺乏有效指导,难以有效结合文本推理、编码和搜索。
- TUMIX通过并行运行多个agent,利用不同的工具使用策略,迭代共享和优化答案,实现更优的推理性能。
- 实验表明,TUMIX在推理精度上显著优于现有方法,并能通过自适应停止机制降低推理成本。
📝 摘要(中文)
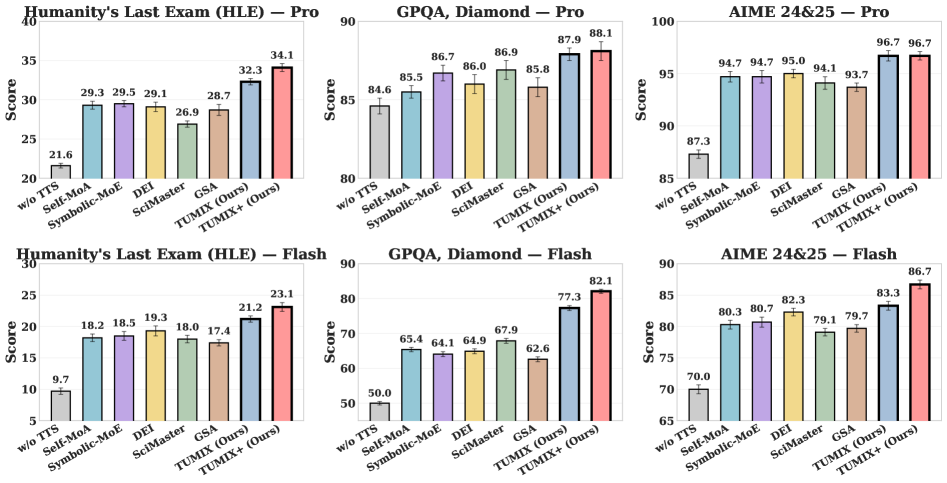
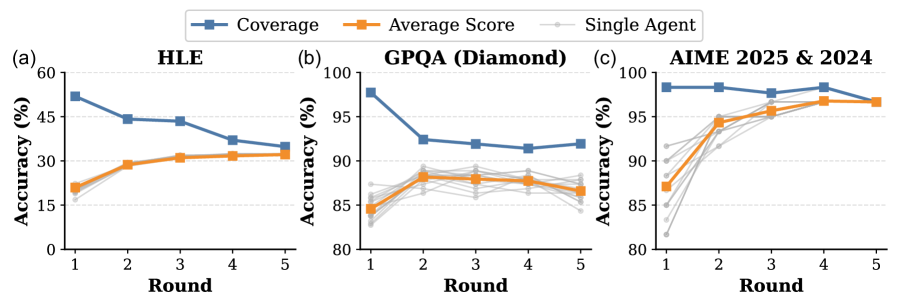
本文提出了一种名为工具使用混合(TUMIX)的集成框架,旨在提升大型语言模型(LLM)在复杂推理任务中的性能。TUMIX并行运行多个agent,每个agent采用不同的工具使用策略和答案路径。这些agent基于问题和先前的答案迭代地共享和改进响应。实验结果表明,TUMIX在Gemini-2.5-Pro和Gemini-2.5-Flash等模型上,相较于最先进的工具增强和测试时扩展方法,在关键推理基准测试中实现了平均高达3.55%的准确率提升,且推理成本几乎相同。研究发现,agent的多样性和质量至关重要,可以通过使用LLM自动优化agent设计来增强。此外,TUMIX可以在达到足够的置信度时停止改进,从而在仅49%的推理成本下保持性能。进一步扩展可以实现更高的性能,但成本也会增加。
🔬 方法详解
问题定义:现有的大型语言模型(LLM),如ChatGPT Agent和Gemini-Pro,集成了代码解释器和搜索等工具,显著增强了推理能力。然而,如何有效地利用这些工具仍然是一个挑战。核心问题在于如何针对不同的问题,有效地结合文本推理、编码和搜索,以获得最佳的答案。现有方法缺乏对工具使用的优化策略,导致性能提升受限。
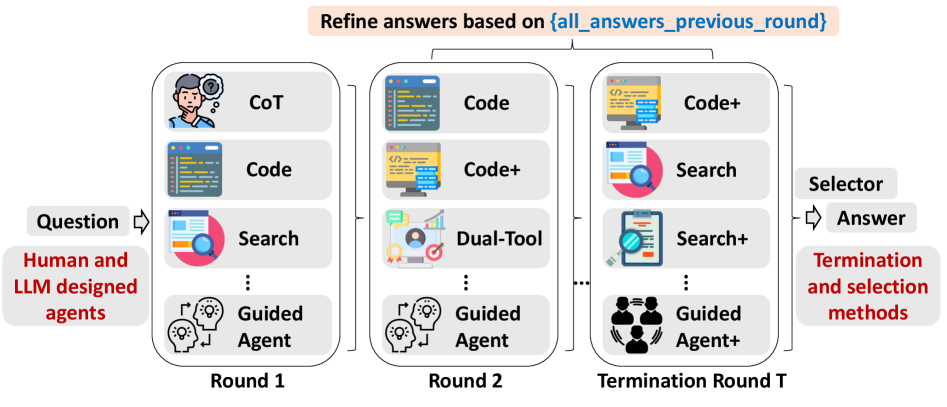
核心思路:TUMIX的核心思路是采用集成学习的思想,并行运行多个agent,每个agent采用不同的工具使用策略和答案路径。通过让这些agent相互协作、共享信息和改进答案,从而提高整体的推理性能。这种方法的核心在于利用agent的多样性来探索不同的解决方案,并利用集体的智慧来找到最佳答案。
技术框架:TUMIX的整体框架包括以下几个主要模块:1) Agent池:包含多个agent,每个agent具有不同的工具使用策略。2) 并行执行:所有agent并行地对问题进行推理,并生成初步答案。3) 答案共享与改进:agent之间共享答案,并根据其他agent的答案和问题本身,迭代地改进自己的答案。4) 停止机制:当达到预定的置信度或迭代次数时,停止改进过程。5) 答案选择:选择最佳的答案作为最终结果。
关键创新:TUMIX最重要的技术创新点在于其工具使用混合策略。与传统的单一agent方法不同,TUMIX通过并行运行多个具有不同工具使用策略的agent,从而探索更广泛的解决方案空间。此外,TUMIX还引入了答案共享和改进机制,使得agent之间可以相互学习和协作,从而提高整体的推理性能。
关键设计:TUMIX的关键设计包括:1) Agent多样性:通过使用不同的LLM、不同的工具组合和不同的提示工程技术来增加agent的多样性。2) 答案共享机制:agent之间共享答案的方式,例如,可以通过投票、加权平均或更复杂的模型来组合答案。3) 停止机制:确定何时停止改进过程,以平衡性能和推理成本。论文中提到可以使用LLM来自动优化agent设计,这可能涉及到使用强化学习或进化算法来搜索最佳的agent配置。
🖼️ 关键图片
📊 实验亮点
TUMIX在Gemini-2.5-Pro和Gemini-2.5-Flash等模型上进行了实验,结果表明,TUMIX在关键推理基准测试中实现了平均高达3.55%的准确率提升,相较于最先进的工具增强和测试时扩展方法。此外,TUMIX可以在仅49%的推理成本下保持性能,通过自适应停止机制。进一步扩展可以实现更高的性能,但成本也会增加。
🎯 应用场景
TUMIX具有广泛的应用前景,可以应用于各种需要复杂推理的任务,例如问答系统、智能助手、代码生成和科学研究。通过提高LLM的推理能力,TUMIX可以帮助人们更有效地解决问题,并促进人工智能技术的发展。未来,TUMIX可以进一步扩展到其他领域,例如机器人控制和自动驾驶,从而实现更智能化的系统。
📄 摘要(原文)
While integrating tools like Code Interpreter and Search has significantly enhanced Large Language Model (LLM) reasoning in models like ChatGPT Agent and Gemini-Pro, practical guidance on optimal tool use is lacking. The core challenge is effectively combining textual reasoning, coding, and search for diverse questions. In this paper, we propose Tool-Use Mixture (TUMIX), an ensemble framework that runs multiple agents in parallel, each employing distinct tool-use strategies and answer paths. Agents in TUMIX iteratively share and refine responses based on the question and previous answers. In experiments, TUMIX achieves significant gains over state-of-the-art tool-augmented and test-time scaling methods, delivering an average accuracy improvement of up to 3.55% over the best baseline on Gemini-2.5-Pro and Gemini-2.5-Flash across key reasoning benchmarks, with near-equal inference costs. We find that agent diversity and quality are crucial and can be enhanced by using LLMs to auto-optimize agent designs. Furthermore, TUMIX can halt refinement upon reaching sufficient confidence, preserving performance at only 49% of the inference cost. Further scaling can achieve higher performance, albeit at a greater cost.