Judging with Confidence: Calibrating Autoraters to Preference Distributions
作者: Zhuohang Li, Xiaowei Li, Chengyu Huang, Guowang Li, Katayoon Goshvadi, Bo Dai, Dale Schuurmans, Paul Zhou, Hamid Palangi, Yiwen Song, Palash Goyal, Murat Kantarcioglu, Bradley A. Malin, Yuan Xue
分类: cs.CL
发布日期: 2025-09-30
💡 一句话要点
提出校准概率自评判器框架,使其与目标偏好分布对齐,提升LLM评估可靠性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 自动评判 偏好分布 校准 强化学习
📋 核心要点
- 现有LLM自评判器训练于离散标签,无法有效处理主观、模糊任务中存在的偏好分布。
- 论文提出通用框架,通过监督微调或强化学习,使自评判器概率预测与目标偏好分布对齐。
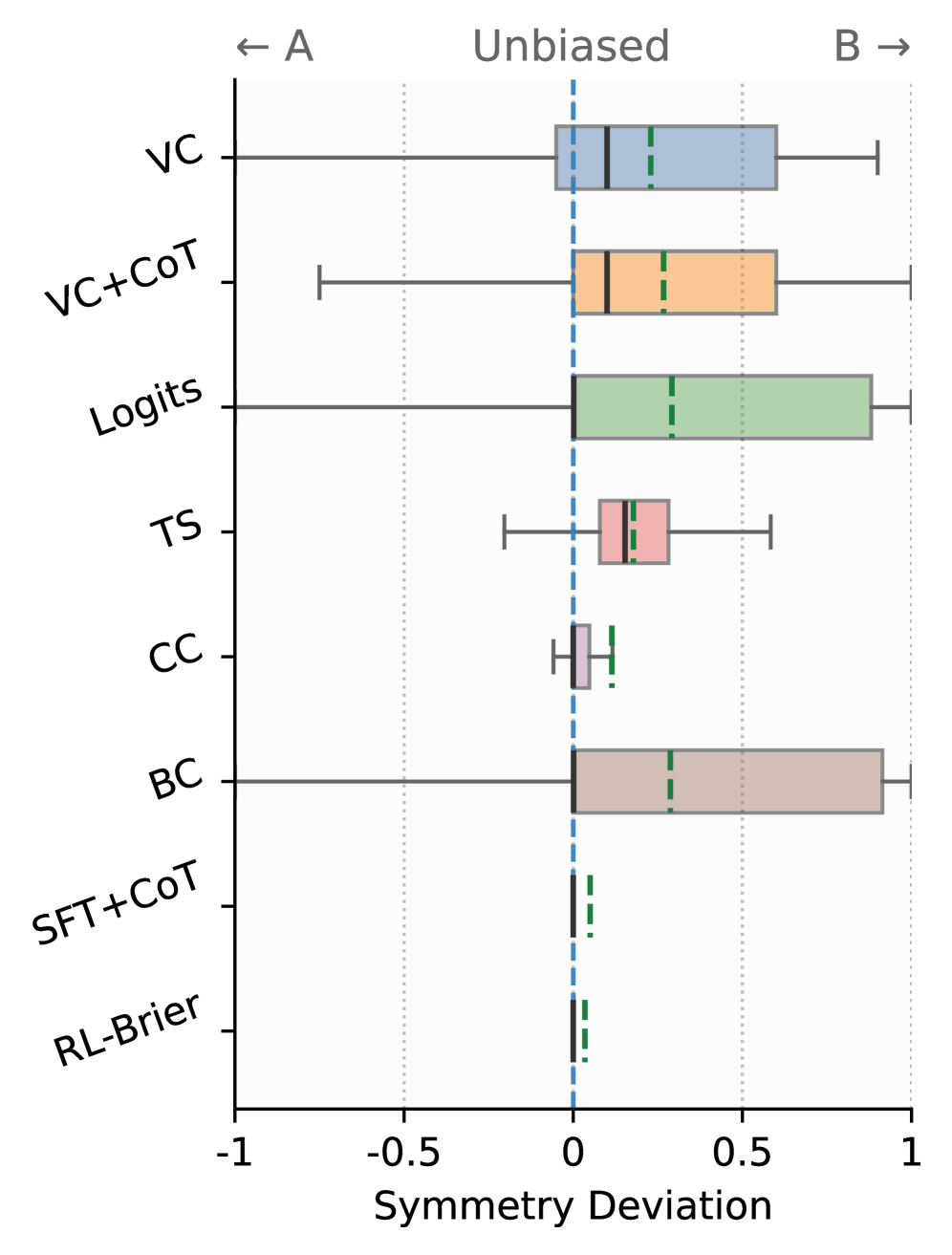
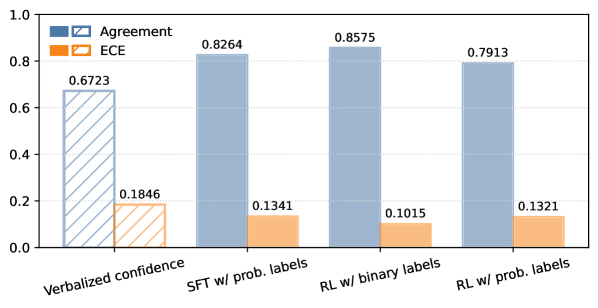
- 实验表明,该方法能提升自评判器的校准性,降低位置偏差,同时保持客观任务性能。
📝 摘要(中文)
大型语言模型(LLM)与人类价值观的对齐越来越依赖于使用其他LLM作为自动评判器(autoraters)。然而,它们的可靠性受到一个根本问题的限制:它们是在离散偏好标签上训练的,这迫使主观、模糊或细微的任务采用单一的ground truth。我们认为,一个可靠的自评判器必须学习对目标人群定义的完整偏好分布进行建模。在本文中,我们提出了一个通用框架,用于将概率自评判器校准到任何给定的偏好分布。我们形式化了这个问题,并提出了两种针对不同数据条件的学习方法:1) 针对密集概率标签的直接监督微调,以及 2) 针对稀疏二元标签的强化学习方法。我们的实验结果表明,使用分布匹配目标微调自评判器可以生成与目标偏好分布更好对齐的口头概率预测,具有改进的校准和显著降低的位置偏差,同时保持在客观任务上的性能。
🔬 方法详解
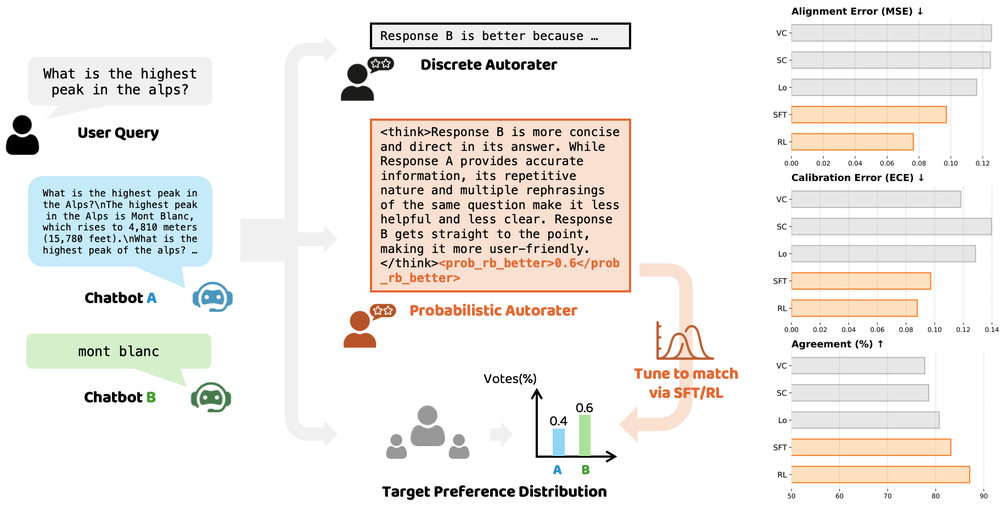
问题定义:现有的大型语言模型自评判器通常基于离散的偏好标签进行训练,这在处理主观性强、存在多种合理答案的任务时会遇到困难。这种方法无法捕捉到人群对不同答案的偏好分布,导致自评判器的可靠性降低。现有方法的痛点在于无法准确反映人类偏好的细微差别和不确定性。
核心思路:论文的核心思路是将自评判器校准到目标偏好分布。这意味着自评判器不仅要预测哪个答案更好,还要预测不同答案被不同人偏好的概率分布。通过学习模拟人群的偏好分布,自评判器可以更准确地评估答案的质量,并减少因主观性带来的偏差。
技术框架:该框架包含两个主要分支,分别对应于不同的数据条件:1) 当有密集的概率标签可用时,采用直接监督微调的方法。2) 当只有稀疏的二元标签可用时,采用强化学习的方法。两种方法的目标都是使自评判器的预测概率分布尽可能接近目标偏好分布。整体流程包括数据预处理、模型微调/训练和评估三个阶段。
关键创新:最重要的技术创新点在于将自评判问题从传统的离散标签预测转化为概率分布匹配问题。与现有方法只关注单一“正确”答案不同,该方法关注整个偏好分布,从而更好地模拟人类的判断过程。这种方法能够更有效地利用有限的标注数据,并提高自评判器的泛化能力。
关键设计:对于监督微调,关键在于设计合适的损失函数来衡量预测概率分布与目标偏好分布之间的差异,例如可以使用交叉熵损失或KL散度。对于强化学习,需要设计合适的奖励函数,鼓励自评判器生成与目标偏好分布一致的预测。具体的网络结构可以采用现有的Transformer模型,并根据任务需求进行调整。参数设置方面,需要根据数据集的大小和模型的复杂度进行调整,以避免过拟合或欠拟合。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用分布匹配目标微调的自评判器在校准性方面有显著提升,位置偏差显著降低。具体而言,与基线方法相比,该方法能够更准确地预测不同答案被偏好的概率,从而更好地反映人群的真实偏好。同时,该方法在客观任务上的性能也得到了保持,表明其具有良好的泛化能力。
🎯 应用场景
该研究成果可应用于各种需要自动评估的场景,例如:LLM对齐、内容审核、代码生成质量评估、教育评估等。通过提高自评判器的可靠性,可以更有效地利用LLM进行自动化评估,降低人工成本,并提高评估的公平性和一致性。未来,该方法可以进一步扩展到更复杂的评估任务,例如多轮对话评估、开放式问题评估等。
📄 摘要(原文)
The alignment of large language models (LLMs) with human values increasingly relies on using other LLMs as automated judges, or ``autoraters''. However, their reliability is limited by a foundational issue: they are trained on discrete preference labels, forcing a single ground truth onto tasks that are often subjective, ambiguous, or nuanced. We argue that a reliable autorater must learn to model the full distribution of preferences defined by a target population. In this paper, we propose a general framework for calibrating probabilistic autoraters to any given preference distribution. We formalize the problem and present two learning methods tailored to different data conditions: 1) a direct supervised fine-tuning for dense, probabilistic labels, and 2) a reinforcement learning approach for sparse, binary labels. Our empirical results show that finetuning autoraters with a distribution-matching objective leads to verbalized probability predictions that are better aligned with the target preference distribution, with improved calibration and significantly lower positional bias, all while preserving performance on objective tasks.