Direct Token Optimization: A Self-contained Approach to Large Language Model Unlearning
作者: Hong kyu Lee, Ruixuan Liu, Li Xiong
分类: cs.CL, cs.AI, cs.CR
发布日期: 2025-09-30
💡 一句话要点
提出直接Token优化(DTO)方法,实现大语言模型自包含式遗忘学习。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 遗忘学习 隐私保护 自包含方法 Token优化
📋 核心要点
- 现有大语言模型遗忘学习方法依赖外部资源,存在不实用和潜在隐私风险。
- 提出直接Token优化(DTO)方法,通过优化token级别目标实现自包含式遗忘。
- 实验表明,DTO在遗忘质量上显著优于现有方法,同时保持了模型效用。
📝 摘要(中文)
本文提出了一种针对大语言模型(LLM)的自包含式遗忘学习方法——直接Token优化(DTO),旨在从模型中移除特定训练数据子集(遗忘集)的影响,而无需完全重新训练。现有的LLM遗忘学习方法通常依赖于辅助语言模型、保留数据集,甚至商业AI服务,这既不实用,也可能引入额外的隐私风险。DTO通过直接优化token级别的目标,消除了对外部资源的依赖。该方法识别两种token:目标token,用于捕获遗忘的关键知识;非目标token,用于维持模型效用。实验结果表明,在多个基准数据集上,DTO的遗忘质量比最新的基线方法提高了高达16.8倍,同时保持了相当的模型效用。
🔬 方法详解
问题定义:大语言模型(LLM)的遗忘学习旨在从模型中移除特定训练数据的影响,而无需完全重新训练。现有方法的痛点在于依赖外部资源(如辅助模型、数据集或商业服务),这增加了部署难度,并可能引入新的隐私风险。
核心思路:论文的核心思路是直接在token级别上优化遗忘目标,避免对外部资源的依赖。通过区分“目标token”(包含需要遗忘的关键知识)和“非目标token”(用于保持模型效用),分别进行优化,从而在遗忘特定信息的同时,尽可能保留模型的通用能力。
技术框架:DTO方法主要包含以下步骤:1) 输入需要遗忘的序列;2) 识别目标token和非目标token;3) 使用目标token优化遗忘目标(例如,降低模型对这些token的预测概率);4) 使用非目标token保持模型效用(例如,通过正则化或约束,防止模型参数过度调整)。整个过程无需外部数据或模型。
关键创新:DTO的关键创新在于其自包含性,即完全依赖模型自身进行遗忘学习,无需任何外部资源。这与依赖辅助模型或数据集的现有方法形成了鲜明对比,降低了部署成本和隐私风险。此外,区分目标token和非目标token,并分别进行优化,有助于在遗忘特定信息的同时,更好地保持模型的通用能力。
关键设计:目标token和非目标token的识别方法是关键设计之一。论文可能采用基于注意力机制或梯度信息的策略来确定哪些token对遗忘目标贡献最大。遗忘目标的优化可以通过调整模型参数来实现,例如,使用梯度下降法最小化模型对目标token的预测概率。同时,为了防止模型过度遗忘,可以使用正则化项或约束条件来限制模型参数的调整幅度。
🖼️ 关键图片
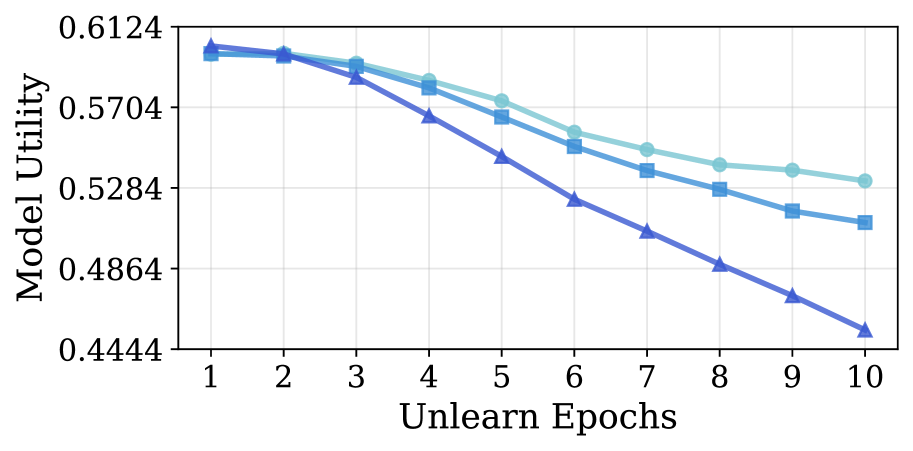
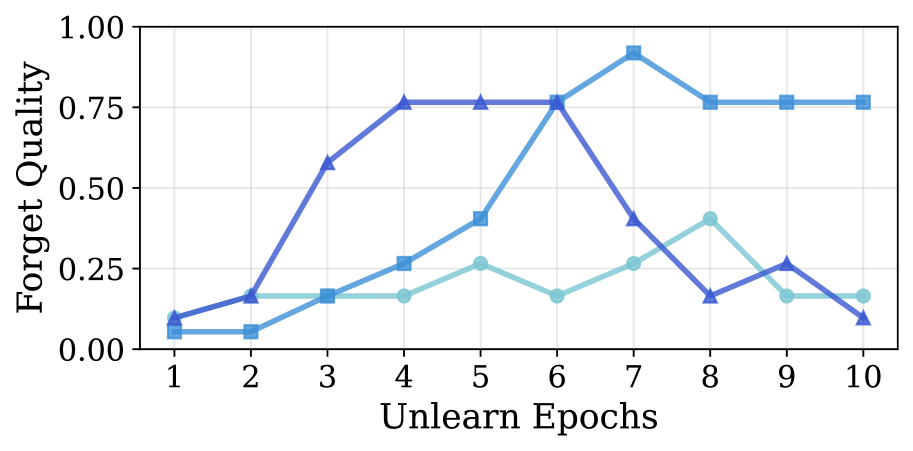
📊 实验亮点
实验结果表明,提出的DTO方法在多个基准数据集上显著优于现有方法。具体而言,DTO在遗忘质量上比最新的基线方法提高了高达16.8倍,同时保持了与基线方法相当的模型效用。这些结果验证了DTO在实现高效、安全的LLM遗忘学习方面的有效性。
🎯 应用场景
该研究成果可应用于多种场景,包括:保护用户隐私(从模型中删除个人信息)、内容审核(移除有害或不当内容的影响)、模型修正(纠正模型中的错误知识)。通过自包含式遗忘学习,可以更安全、高效地更新和维护大语言模型,降低部署成本和隐私风险,促进LLM在各个领域的广泛应用。
📄 摘要(原文)
Machine unlearning is an emerging technique that removes the influence of a subset of training data (forget set) from a model without full retraining, with applications including privacy protection, content moderation, and model correction. The key challenge lies in ensuring that the model completely forgets the knowledge of the forget set without compromising its overall utility. Existing unlearning methods for large language models (LLMs) often utilize auxiliary language models, retain datasets, or even commercial AI services for effective unlearning and maintaining the model utility. However, dependence on these external resources is often impractical and could potentially introduce additional privacy risks. In this work, we propose direct token optimization (DTO), a novel self-contained unlearning approach for LLMs that directly optimizes the token level objectives and eliminates the need for external resources. Given a sequence to unlearn, we identify two categories of tokens: target tokens, which capture critical knowledge for unlearning, and the remaining non-target tokens, which are crucial for maintaining the model utility. The former are used to optimize the unlearning objective, while the latter serve to preserve the model's performance. The experimental results show that the proposed DTO achieves up to 16.8$\times$ improvement in forget quality on several benchmark datasets than the latest baselines while maintaining a comparable level of model utility.