Automatic Fact-checking in English and Telugu
作者: Ravi Kiran Chikkala, Tatiana Anikina, Natalia Skachkova, Ivan Vykopal, Rodrigo Agerri, Josef van Genabith
分类: cs.CL
发布日期: 2025-09-30 (更新: 2025-11-18)
备注: Proceedings of the First Workshop on Advancing NLP for Low Resource Languages associated with RANLP 2025 Varna Bulgaria September 13 2025 pages 140-151
💡 一句话要点
构建英-泰双语数据集,探索LLM在英语和泰卢固语事实核查中的有效性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 事实核查 大型语言模型 自然语言处理 低资源语言 泰卢固语
📋 核心要点
- 手动事实核查耗时费力,难以应对大规模虚假信息传播的挑战。
- 论文提出利用大型语言模型(LLM)自动进行事实核查,并生成相应的理由。
- 构建了英-泰双语数据集,并对多种基于LLM的事实核查方法进行了基准测试。
📝 摘要(中文)
虚假信息构成了一项重大的全球性挑战,而手动验证声明既耗时又耗费资源。在这篇研究论文中,我们通过实验不同的方法,来研究大型语言模型(LLM)在根据事实的准确性对事实性声明进行分类,以及在英语和泰卢固语中生成理由方面的有效性。这项工作的主要贡献包括创建了一个英-泰双语数据集,以及对基于LLM的不同准确性分类方法进行基准测试。
🔬 方法详解
问题定义:论文旨在解决虚假信息泛滥的问题,现有的人工事实核查方法效率低下,无法满足需求。因此,需要一种自动化的方法来验证声明的真实性。现有的方法在低资源语言(如泰卢固语)上的表现通常较差,缺乏相应的标注数据。
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的语言理解和生成能力,自动判断声明的真实性并生成理由。通过构建英-泰双语数据集,可以促进LLM在低资源语言上的应用。这样设计的目的是为了降低人工成本,提高事实核查的效率和覆盖范围。
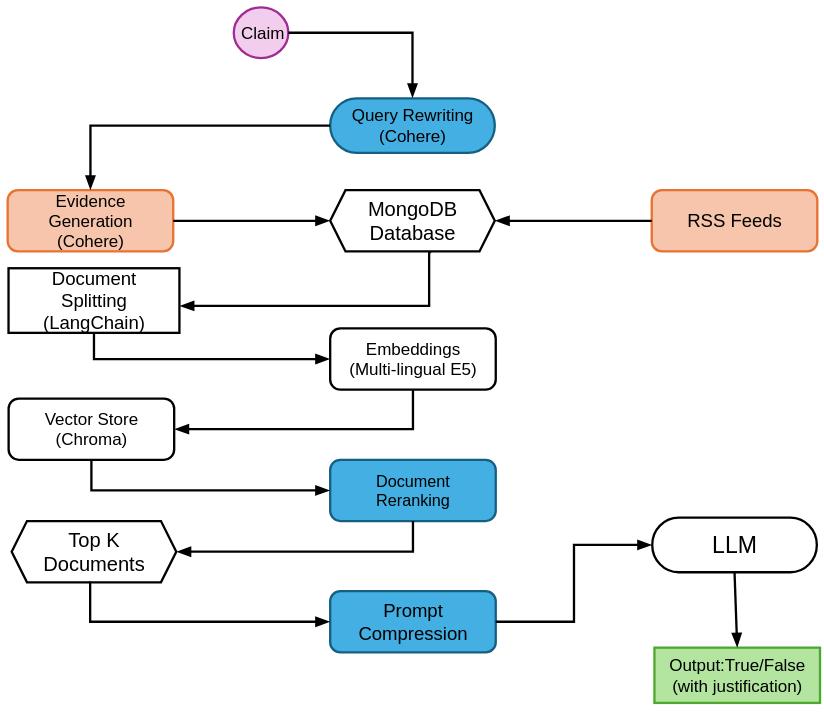
技术框架:论文的技术框架主要包括数据收集与标注、模型选择与训练、以及性能评估三个阶段。首先,收集英语和泰卢固语的事实性声明,并进行人工标注。然后,选择合适的LLM,并使用标注数据进行训练。最后,使用评估指标来衡量模型的性能。具体模块包括:数据预处理模块、LLM模型、分类模块、理由生成模块和评估模块。
关键创新:论文的关键创新在于构建了一个英-泰双语数据集,这为低资源语言的事实核查研究提供了宝贵的数据资源。此外,论文还对多种基于LLM的事实核查方法进行了基准测试,为后续研究提供了参考。与现有方法相比,该研究更注重低资源语言的处理,并探索了LLM在事实核查中的潜力。
关键设计:论文中关于LLM的选择、训练策略以及评估指标的选择等技术细节未知。数据集的构建和标注过程也缺乏具体描述。损失函数和网络结构等细节也未提及,这些是未来研究可以深入探索的方向。
🖼️ 关键图片


📊 实验亮点
论文的主要实验亮点在于构建了英-泰双语数据集,并对不同的LLM在事实核查任务上的性能进行了基准测试。具体的性能数据和对比基线未知,但该研究为低资源语言的事实核查提供了有价值的资源和参考。
🎯 应用场景
该研究成果可应用于新闻媒体、社交平台等领域,帮助自动识别和过滤虚假信息,提高信息的可信度。通过自动化事实核查,可以减少人工干预,提高效率,并降低虚假信息传播带来的负面影响。未来,该技术有望应用于更广泛的语言和领域,为构建健康的网络信息生态做出贡献。
📄 摘要(原文)
False information poses a significant global challenge, and manually verifying claims is a time-consuming and resource-intensive process. In this research paper, we experiment with different approaches to investigate the effectiveness of large language models (LLMs) in classifying factual claims by their veracity and generating justifications in English and Telugu. The key contributions of this work include the creation of a bilingual English-Telugu dataset and the benchmarking of different veracity classification approaches based on LLMs.