Fast-dLLM v2: Efficient Block-Diffusion LLM
作者: Chengyue Wu, Hao Zhang, Shuchen Xue, Shizhe Diao, Yonggan Fu, Zhijian Liu, Pavlo Molchanov, Ping Luo, Song Han, Enze Xie
分类: cs.CL
发布日期: 2025-09-30
💡 一句话要点
Fast-dLLM v2:高效块扩散语言模型,加速并行文本生成。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散语言模型 并行生成 自回归模型 高效推理 分层缓存 注意力机制 文本生成 大型语言模型
📋 核心要点
- 自回归LLM推理效率受限于顺序解码,成为实际应用的瓶颈。
- Fast-dLLM v2通过块扩散机制和互补注意力掩码,将预训练AR模型转化为并行生成dLLM。
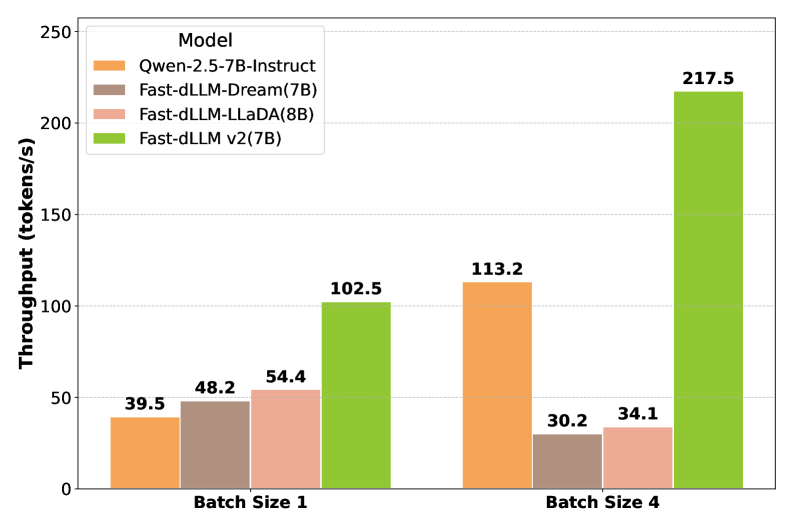
- 实验表明,Fast-dLLM v2在保持或超过AR模型准确率的同时,实现了高达2.5倍的推理加速。
📝 摘要(中文)
自回归(AR)大型语言模型(LLM)在各种自然语言任务中取得了显著的性能,但其固有的顺序解码限制了推理效率。本文提出了Fast-dLLM v2,这是一种精心设计的块扩散语言模型(dLLM),能够有效地将预训练的AR模型适配为dLLM,用于并行文本生成,仅需约10亿token的微调。与Dream等全注意力扩散LLM(5800亿token)相比,这减少了500倍的训练数据,同时保留了原始模型的性能。我们的方法引入了一种新颖的训练方案,该方案结合了块扩散机制和互补注意力掩码,从而实现了块状双向上下文建模,而不会牺牲AR训练目标。为了进一步加速解码,我们设计了一种分层缓存机制:块级缓存,用于存储跨块的历史上下文表示;子块缓存,用于在部分解码的块内实现高效的并行生成。结合我们的并行解码流水线,Fast-dLLM v2在不影响生成质量的前提下,实现了比标准AR解码高达2.5倍的加速。在各种基准测试中进行的大量实验表明,Fast-dLLM v2在准确性方面与AR基线相匹配或超过了AR基线,同时在dLLM中提供了最先进的效率——标志着朝着快速准确的LLM的实际部署迈出了重要一步。代码和模型将公开发布。
🔬 方法详解
问题定义:论文旨在解决自回归大型语言模型(LLM)推理效率低下的问题。传统的自回归模型需要顺序解码,这严重限制了生成速度,尤其是在长文本生成场景下。现有扩散语言模型(dLLM)虽然支持并行生成,但通常需要大量的训练数据,且性能难以与自回归模型媲美。
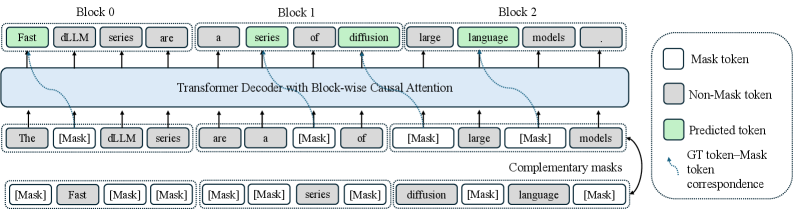
核心思路:论文的核心思路是将预训练的自回归模型转化为块扩散语言模型,从而实现并行文本生成。通过引入块扩散机制和互补注意力掩码,模型能够在块级别进行双向上下文建模,同时保留自回归训练的目标。此外,分层缓存机制进一步加速了解码过程。
技术框架:Fast-dLLM v2的整体框架包括以下几个主要模块:1) 块扩散机制:将文本分成块,并使用扩散过程逐步生成每个块。2) 互补注意力掩码:允许模型在块内进行双向注意力,同时保持块间的自回归依赖关系。3) 分层缓存机制:包括块级缓存和子块缓存,用于存储历史上下文信息,加速并行解码。4) 并行解码流水线:利用GPU并行计算能力,加速块的生成过程。
关键创新:论文最重要的技术创新点在于提出了一种高效的训练方案,该方案能够在少量数据(约10亿token)上将预训练的自回归模型转化为高性能的块扩散语言模型。与需要大量训练数据的全注意力扩散LLM相比,Fast-dLLM v2大大降低了训练成本,并保留了原始模型的性能。
关键设计:关键设计包括:1) 块大小的选择:需要平衡并行度和上下文依赖关系。2) 互补注意力掩码的设计:需要确保块内双向注意力的有效性,同时避免破坏块间的自回归依赖关系。3) 分层缓存机制的实现:需要考虑缓存的容量和访问效率。4) 损失函数的设计:需要结合自回归损失和扩散损失,以保证模型的生成质量。
🖼️ 关键图片

📊 实验亮点
Fast-dLLM v2在各种基准测试中表现出色,在准确性方面与AR基线相匹配或超过了AR基线,同时实现了高达2.5倍的推理加速。与需要5800亿token训练的全注意力扩散LLM相比,Fast-dLLM v2仅需约10亿token的微调,大大降低了训练成本,并在dLLM中提供了最先进的效率。
🎯 应用场景
Fast-dLLM v2具有广泛的应用前景,包括但不限于:快速文本生成、机器翻译、对话系统、代码生成等。其高效的并行生成能力使其能够满足对实时性要求较高的应用场景。该研究的成果有助于推动大型语言模型在实际应用中的部署,并加速人工智能技术的发展。
📄 摘要(原文)
Autoregressive (AR) large language models (LLMs) have achieved remarkable performance across a wide range of natural language tasks, yet their inherent sequential decoding limits inference efficiency. In this work, we propose Fast-dLLM v2, a carefully designed block diffusion language model (dLLM) that efficiently adapts pretrained AR models into dLLMs for parallel text generation, requiring only approximately 1B tokens of fine-tuning. This represents a 500x reduction in training data compared to full-attention diffusion LLMs such as Dream (580B tokens), while preserving the original model's performance. Our approach introduces a novel training recipe that combines a block diffusion mechanism with a complementary attention mask, enabling blockwise bidirectional context modeling without sacrificing AR training objectives. To further accelerate decoding, we design a hierarchical caching mechanism: a block-level cache that stores historical context representations across blocks, and a sub-block cache that enables efficient parallel generation within partially decoded blocks. Coupled with our parallel decoding pipeline, Fast-dLLM v2 achieves up to 2.5x speedup over standard AR decoding without compromising generation quality. Extensive experiments across diverse benchmarks demonstrate that Fast-dLLM v2 matches or surpasses AR baselines in accuracy, while delivering state-of-the-art efficiency among dLLMs - marking a significant step toward the practical deployment of fast and accurate LLMs. Code and model will be publicly released.