VietBinoculars: A Zero-Shot Approach for Detecting Vietnamese LLM-Generated Text
作者: Trieu Hai Nguyen, Sivaswamy Akilesh
分类: cs.CL
发布日期: 2025-09-30
备注: 27 pages
💡 一句话要点
VietBinoculars:一种零样本越南语LLM生成文本检测方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 越南语文本检测 LLM生成文本 零样本学习 阈值优化 自然语言处理
📋 核心要点
- 区分人类撰写文本和LLM生成文本日益困难,传统方法在面对快速涌现的新LLM模型时效果不佳。
- 论文提出VietBinoculars,通过优化全局阈值改进Binoculars方法,专门用于检测越南语LLM生成的文本。
- 实验表明,VietBinoculars在多个领域外数据集上表现优异,各项指标均超过99%,优于现有方法。
📝 摘要(中文)
基于Transformer架构的大型语言模型(LLM)的快速发展带来了一系列关键挑战,其中之一是区分人工撰写的文本和LLM生成的文本。随着LLM生成的文本内容变得越来越复杂,并且越来越像人类写作,传统的检测方法正变得越来越无效,特别是随着LLM的数量和多样性不断增长,新的模型和版本以惊人的速度发布。本研究提出了VietBinoculars,它是Binoculars方法的一种改进版本,具有优化的全局阈值,旨在增强越南语LLM生成文本的检测能力。我们构建了新的越南语AI生成数据集,以确定VietBinoculars的最佳阈值并进行基准测试。实验结果表明,VietBinoculars在多个领域外数据集上的准确率、F1分数和AUC均超过99%。它优于原始的Binoculars模型、传统的检测方法以及其他最先进的方法,包括ZeroGPT和DetectGPT等商业工具,尤其是在经过专门修改的提示策略下。
🔬 方法详解
问题定义:论文旨在解决区分越南语人工撰写文本和LLM生成文本的问题。现有方法,特别是传统的检测方法,在面对不断涌现的新型LLM及其生成的复杂文本时,检测效果不佳,难以适应LLM的多样性和快速发展。
核心思路:论文的核心思路是改进现有的Binoculars方法,通过优化全局阈值来提高其在越南语LLM生成文本检测方面的性能。Binoculars方法本身基于对文本统计特征的分析,而VietBinoculars的关键在于针对越南语的特性,找到更合适的阈值,从而更准确地区分人工文本和机器生成文本。
技术框架:VietBinoculars的整体框架基于Binoculars方法,主要包括以下几个步骤:1) 文本预处理;2) 特征提取(例如,词频、n-gram频率等);3) 使用预定义的全局阈值对提取的特征进行分析;4) 根据分析结果判断文本是人工生成还是机器生成。论文的关键在于优化步骤3中的全局阈值,使其更适合越南语。
关键创新:论文最重要的技术创新点在于针对越南语LLM生成文本的特性,对Binoculars方法的全局阈值进行了优化。通过构建新的越南语AI生成数据集,论文能够更准确地确定最佳阈值,从而显著提高检测性能。与现有方法的本质区别在于,VietBinoculars是专门为越南语设计的,并针对越南语的特点进行了优化。
关键设计:论文的关键设计在于构建了新的越南语AI生成数据集,并利用该数据集来确定VietBinoculars的最佳全局阈值。具体来说,论文可能采用了网格搜索或优化算法来寻找最佳阈值组合。此外,论文还可能考虑了不同的特征组合和权重分配,以进一步提高检测性能。具体的损失函数和网络结构(如果涉及)在论文中未明确提及,但阈值优化是核心。
🖼️ 关键图片

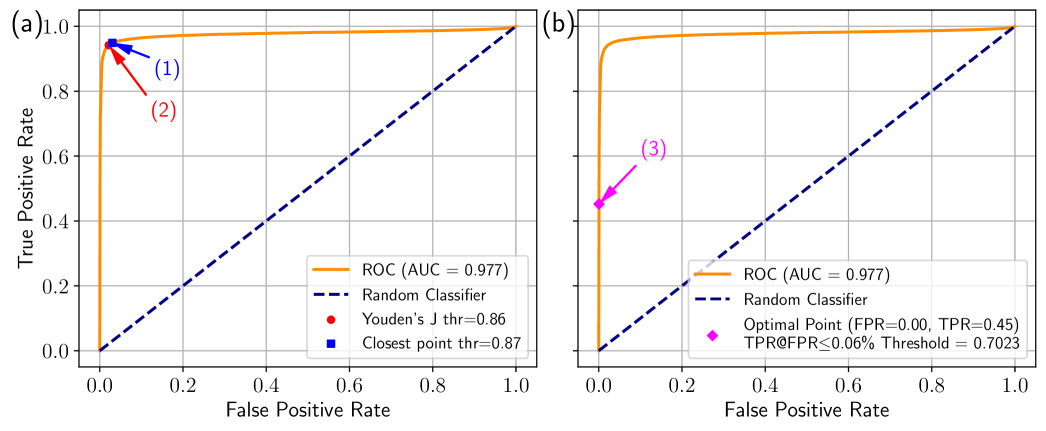
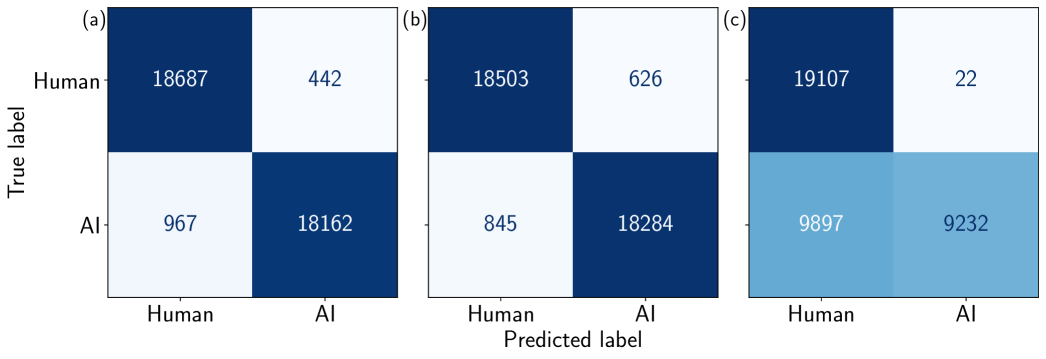
📊 实验亮点
VietBinoculars在多个领域外数据集上实现了超过99%的准确率、F1分数和AUC,显著优于原始的Binoculars模型、传统检测方法以及ZeroGPT和DetectGPT等商业工具。尤其是在经过专门修改的提示策略下,VietBinoculars的优势更加明显,表明其对LLM生成文本的鲁棒性更强。
🎯 应用场景
VietBinoculars可应用于内容审核、学术诚信检测、新闻真实性验证等领域,尤其是在越南语环境下。该研究有助于识别和过滤LLM生成的虚假信息、抄袭内容,维护网络信息安全和学术规范,具有重要的社会价值和实际应用前景。
📄 摘要(原文)
The rapid development research of Large Language Models (LLMs) based on transformer architectures raises key challenges, one of them being the task of distinguishing between human-written text and LLM-generated text. As LLM-generated textual content, becomes increasingly complex over time, and resembles human writing, traditional detection methods are proving less effective, especially as the number and diversity of LLMs continue to grow with new models and versions being released at a rapid pace. This study proposes VietBinoculars, an adaptation of the Binoculars method with optimized global thresholds, to enhance the detection of Vietnamese LLM-generated text. We have constructed new Vietnamese AI-generated datasets to determine the optimal thresholds for VietBinoculars and to enable benchmarking. The results from our experiments show results show that VietBinoculars achieves over 99\% in all two domains of accuracy, F1-score, and AUC on multiple out-of-domain datasets. It outperforms the original Binoculars model, traditional detection methods, and other state-of-the-art approaches, including commercial tools such as ZeroGPT and DetectGPT, especially under specially modified prompting strategies.