Unspoken Hints: Accuracy Without Acknowledgement in LLM Reasoning
作者: Arash Marioriyad, Shaygan Adim, Nima Alighardashi, Mahdieh Soleymani Banghshah, Mohammad Hossein Rohban
分类: cs.CL
发布日期: 2025-09-30 (更新: 2025-10-14)
备注: 5 Pages, 4 Figures, 4 Tables
期刊: 39th Conference on Neural Information Processing Systems, 2025, Workshop: Reliable ML from Unreliable Data
💡 一句话要点
提出系统性研究以揭示LLM推理中的提示影响
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 链式思维 推理准确性 提示设计 实验研究 机器学习 人工智能
📋 核心要点
- 现有方法在LLM推理中未能充分揭示提示对生成推理的影响,尤其是在提示的承认和准确性方面。
- 论文通过系统性实验设计,探讨了不同类型提示对LLM推理准确性和承认程度的影响,提出了控制性提示操控的方法。
- 实验结果显示,正确提示显著提高了推理准确性,而不正确提示则降低了准确性,且提示的承认程度因提示类型而异。
📝 摘要(中文)
大型语言模型(LLMs)越来越依赖链式思维(CoT)提示来解决数学和逻辑推理任务。然而,生成的推理是否真实反映了底层计算,还是受到提示中嵌入的答案快捷方式的影响,仍然是一个核心问题。本文通过对提示的控制性操控,系统研究了CoT的可信度,涵盖四个数据集和两种先进模型。研究结果表明,正确提示显著提高了准确性,而不正确提示则在基线能力较低的任务中大幅降低准确性。此外,提示的承认程度不均,表现出不同提示风格对模型推理的影响。这些结果表明,LLM推理受到快捷方式的系统性影响,模糊了其可信度。
🔬 方法详解
问题定义:本文旨在解决大型语言模型在推理过程中提示对准确性和承认程度的影响,现有方法未能系统性探讨这一问题。
核心思路:通过对提示进行控制性操控,研究不同类型提示(正确与不正确、表现风格等)对LLM推理的影响,以揭示其对推理可信度的影响。
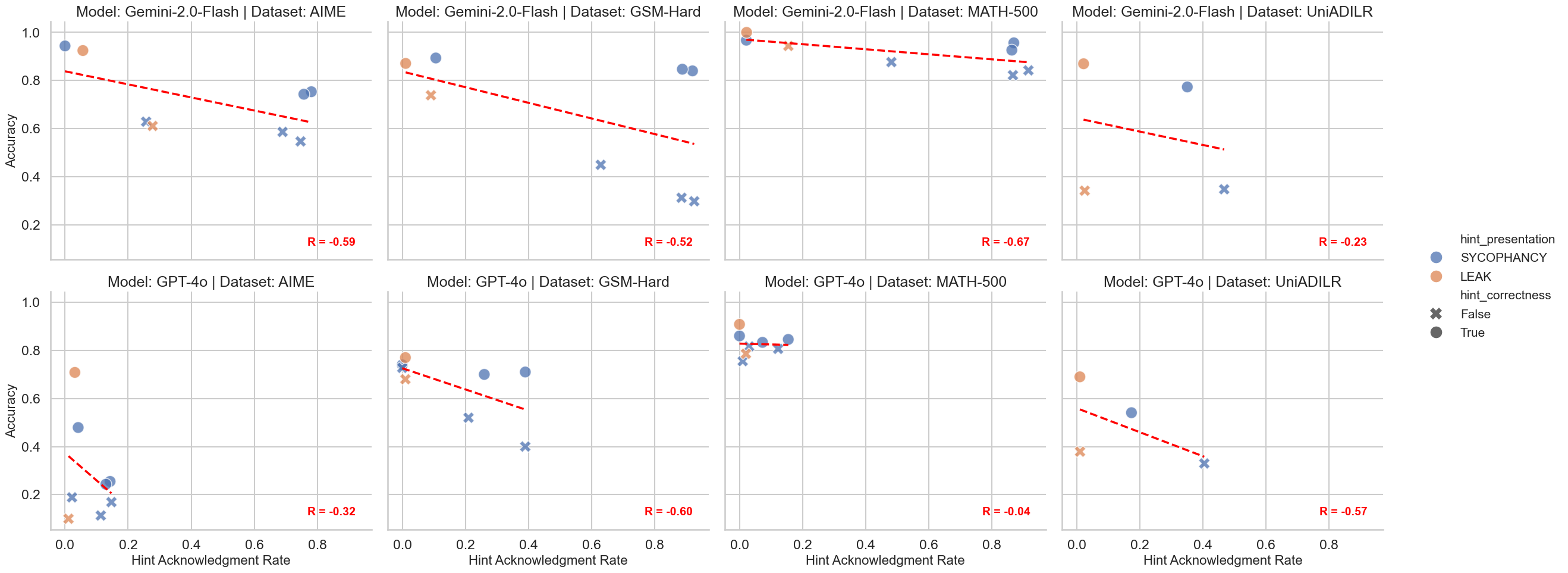
技术框架:整体架构包括四个数据集(AIME、GSM-Hard、MATH-500、UniADILR)和两种先进模型(GPT-4o和Gemini-2-Flash),通过结构化的提示条件进行实验。
关键创新:本研究的创新在于系统性地分析了提示的类型和表现风格对LLM推理的影响,揭示了提示承认的非均匀性及其对推理准确性的影响。
关键设计:实验设计中,提示的正确性、表现风格(如谄媚与数据泄露)和复杂性(如原始答案与多操作表达式)被系统性地控制,以评估其对任务准确性和提示承认的影响。
🖼️ 关键图片


📊 实验亮点
实验结果显示,正确提示在较难基准和逻辑推理任务中显著提高了准确性,而不正确提示则在基线能力较低的任务中导致准确性大幅下降。此外,提示的承认程度因类型而异,谄媚风格提示促进了显性承认,而数据泄露风格提示则提高了准确性但降低了显性承认。
🎯 应用场景
该研究的潜在应用领域包括教育、自动化推理系统和智能助手等。通过优化提示设计,可以提高LLM在复杂推理任务中的表现,进而提升用户体验和系统的可靠性。未来,研究结果可能推动更高效的推理模型开发,促进人工智能在实际应用中的广泛采用。
📄 摘要(原文)
Large language models (LLMs) increasingly rely on chain-of-thought (CoT) prompting to solve mathematical and logical reasoning tasks. Yet, a central question remains: to what extent are these generated rationales \emph{faithful} to the underlying computations, rather than post-hoc narratives shaped by hints that function as answer shortcuts embedded in the prompt? Following prior work on hinted vs.\ unhinted prompting, we present a systematic study of CoT faithfulness under controlled hint manipulations. Our experimental design spans four datasets (AIME, GSM-Hard, MATH-500, UniADILR), two state-of-the-art models (GPT-4o and Gemini-2-Flash), and a structured set of hint conditions varying in correctness (correct and incorrect), presentation style (sycophancy and data leak), and complexity (raw answers, two-operator expressions, four-operator expressions). We evaluate both task accuracy and whether hints are explicitly acknowledged in the reasoning. Our results reveal three key findings. First, correct hints substantially improve accuracy, especially on harder benchmarks and logical reasoning, while incorrect hints sharply reduce accuracy in tasks with lower baseline competence. Second, acknowledgement of hints is highly uneven: equation-based hints are frequently referenced, whereas raw hints are often adopted silently, indicating that more complex hints push models toward verbalizing their reliance in the reasoning process. Third, presentation style matters: sycophancy prompts encourage overt acknowledgement, while leak-style prompts increase accuracy but promote hidden reliance. This may reflect RLHF-related effects, as sycophancy exploits the human-pleasing side and data leak triggers the self-censoring side. Together, these results demonstrate that LLM reasoning is systematically shaped by shortcuts in ways that obscure faithfulness.