Mem-α: Learning Memory Construction via Reinforcement Learning
作者: Yu Wang, Ryuichi Takanobu, Zhiqi Liang, Yuzhen Mao, Yuanzhe Hu, Julian McAuley, Xiaojian Wu
分类: cs.CL
发布日期: 2025-09-30
💡 一句话要点
提出Mem-α框架以优化复杂记忆系统管理
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 记忆增强 强化学习 大型语言模型 信息管理 智能代理 多轮交互 问答系统
📋 核心要点
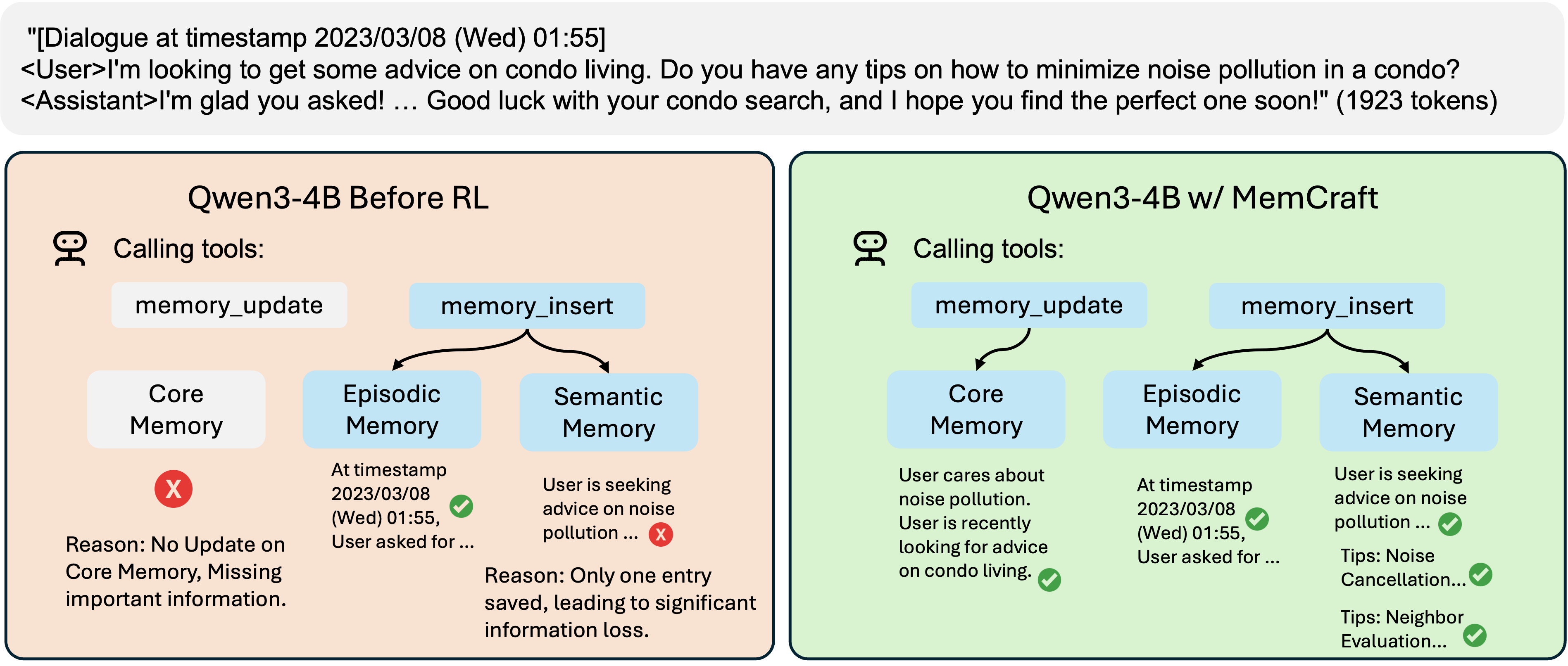
- 现有记忆增强代理依赖预定义指令,导致信息存储和更新能力不足,影响记忆构建效果。
- Mem-α框架通过强化学习训练代理,优化复杂记忆系统的管理,提升信息提取和存储能力。
- 实验结果显示,Mem-α在记忆构建上显著优于现有基线,且具备良好的泛化能力,处理长达400k tokens的序列。
📝 摘要(中文)
大型语言模型(LLM)代理受到有限上下文窗口的限制,需依赖外部记忆系统以实现长期信息理解。现有的记忆增强代理通常依赖预定义的指令和工具进行记忆更新,但语言模型在存储信息、结构化信息和更新时机方面能力不足,导致记忆构建不佳和信息丢失。为此,本文提出Mem-α,一个通过交互和反馈训练代理有效管理复杂记忆系统的强化学习框架。我们构建了一个涵盖多轮交互模式的专用训练数据集,并设计了全面的评估问题以教授有效的记忆管理。实验表明,Mem-α在现有记忆增强代理基线中取得了显著提升,且在训练实例长度为30k tokens的情况下,代理对超过400k tokens的序列表现出良好的泛化能力。
🔬 方法详解
问题定义:本文旨在解决大型语言模型在复杂记忆系统管理中的不足,现有方法依赖固定指令,导致信息存储和更新不够灵活,影响记忆的有效性。
核心思路:Mem-α框架通过强化学习训练代理,使其能够自主决定存储的信息、结构化方式及更新时机,从而优化记忆管理。
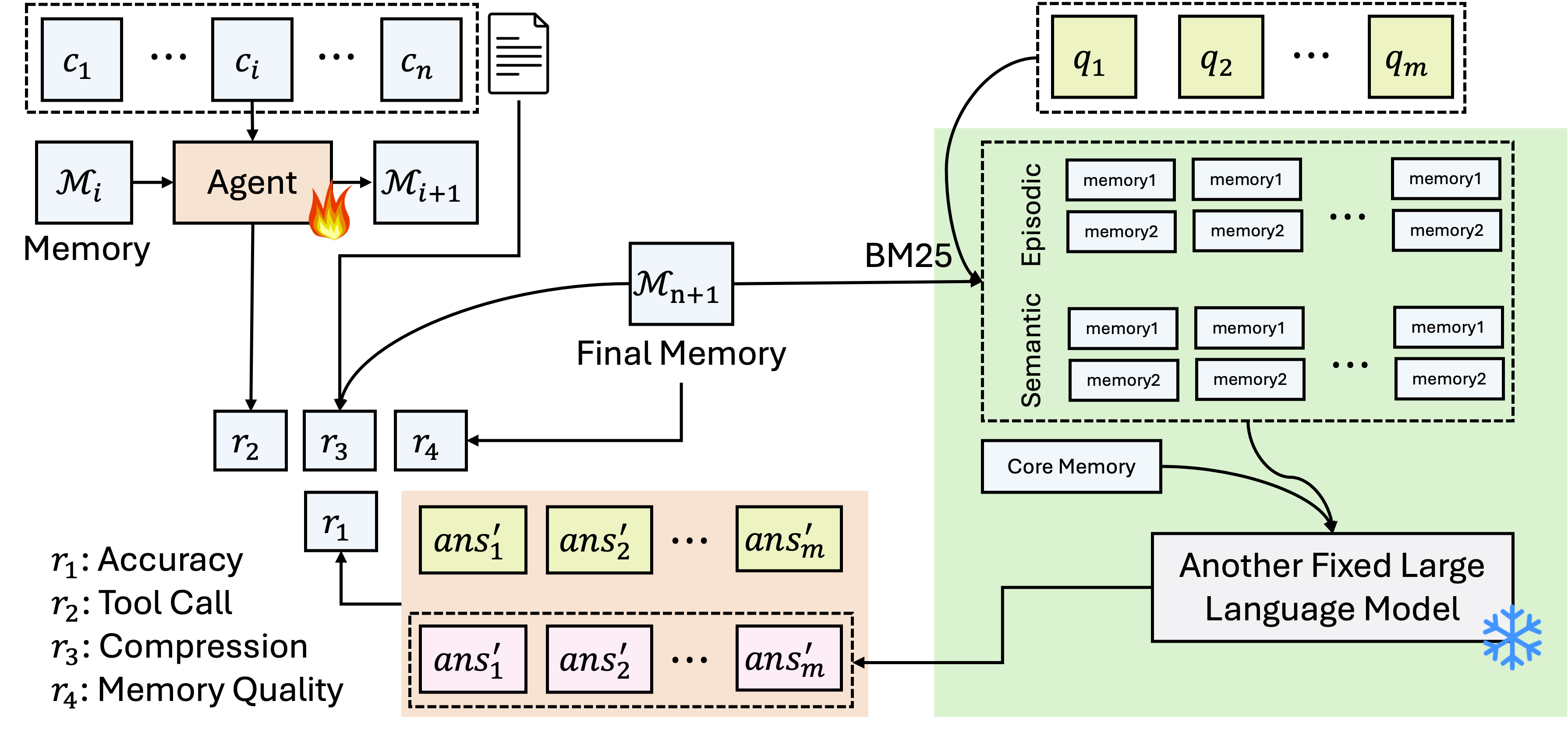
技术框架:Mem-α的整体架构包括核心、情节和语义组件,代理通过处理顺序信息块,提取和存储相关内容,并更新记忆系统。训练过程中,代理根据下游问答准确性获得奖励信号,直接优化记忆构建。
关键创新:Mem-α的主要创新在于通过强化学习实现自主记忆管理,区别于传统依赖预定义指令的方法,提升了记忆系统的灵活性和有效性。
关键设计:在训练过程中,使用了多样化的多轮交互模式数据集,设计了全面的评估问题,代理的奖励信号基于完整交互历史的问答准确性,确保了记忆构建的优化。具体参数设置和损失函数设计未详细披露,需进一步研究。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Mem-α在记忆构建方面显著优于现有基线,尤其是在处理超过400k tokens的序列时,表现出超过13倍的训练长度泛化能力,显示出该框架的强大鲁棒性。
🎯 应用场景
Mem-α框架可广泛应用于需要长期记忆管理的智能代理系统,如对话系统、虚拟助手和自动化客户服务等领域。其灵活的记忆管理能力将提升这些系统在复杂交互中的表现,具有重要的实际价值和未来影响。
📄 摘要(原文)
Large language model (LLM) agents are constrained by limited context windows, necessitating external memory systems for long-term information understanding. Current memory-augmented agents typically depend on pre-defined instructions and tools for memory updates. However, language models may lack the ability to determine which information to store, how to structure it, and when to update it, especially as memory systems become more complex. This results in suboptimal memory construction and information loss. To this end, we propose Mem-alpha, a reinforcement learning framework that trains agents to effectively manage complex memory systems through interaction and feedback. We also construct a specialized training dataset spanning diverse multi-turn interaction patterns paired with comprehensive evaluation questions designed to teach effective memory management. During training, agents process sequential information chunks, learn to extract and store relevant content, then update the memory system. The reward signal derives from downstream question-answering accuracy over the full interaction history, directly optimizing for memory construction. To illustrate the effectiveness of our training framework, we design a memory architecture comprising core, episodic, and semantic components, equipped with multiple tools for memory operations. Empirical evaluation demonstrates that Mem-alpha achieves significant improvements over existing memory-augmented agent baselines. Despite being trained exclusively on instances with a maximum length of 30k tokens, our agents exhibit remarkable generalization to sequences exceeding 400k tokens, over 13x the training length, highlighting the robustness of Mem-alpha.