Personalized Scientific Figure Caption Generation: An Empirical Study on Author-Specific Writing Style Transfer
作者: Jaeyoung Kim, Jongho Lee, Hongjun Choi, Sion Jang
分类: cs.CL, cs.CV
发布日期: 2025-09-30
💡 一句话要点
研究基于作者风格迁移的个性化科学图表标题生成方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图表标题生成 个性化 作者风格迁移 多模态学习 大型语言模型
📋 核心要点
- 现有图表标题生成方法难以捕捉不同作者的写作风格,导致生成的标题缺乏个性化。
- 论文提出利用作者个人资料数据和元数据,结合多模态大型语言模型,实现作者风格的迁移。
- 实验结果表明,该方法能有效提升个性化标题生成效果,但需权衡作者风格匹配和标题质量。
📝 摘要(中文)
本文研究了利用科学论文中的作者个人资料数据进行个性化图表标题生成。实验表明,丰富的作者个人资料数据与相关的元数据相结合,可以显著提高多模态大型语言模型的个性化性能。然而,我们也揭示了匹配作者风格和保持标题质量之间存在根本性的权衡。我们的研究结果为开发能够平衡这两个目标的实用标题自动化系统提供了宝贵的见解和未来方向。这项工作是第三届SciCap挑战赛的一部分。
🔬 方法详解
问题定义:论文旨在解决科学论文中图表标题生成缺乏个性化的问题。现有的图表标题生成方法通常忽略了作者的写作风格,导致生成的标题千篇一律,无法体现作者的个人特色。因此,如何根据作者的个人资料和写作习惯,生成具有作者风格的个性化图表标题是一个重要的研究问题。
核心思路:论文的核心思路是利用作者的个人资料数据(例如,发表论文数量、研究领域、常用词汇等)和论文的元数据(例如,摘要、关键词等),来指导多模态大型语言模型生成图表标题。通过将作者的个人信息融入到标题生成过程中,可以使生成的标题更符合作者的写作风格,从而实现个性化。
技术框架:整体框架包含以下几个主要模块:1) 作者资料提取模块:从科学论文数据库中提取作者的个人资料信息,例如,发表论文数量、研究领域、常用词汇等。2) 元数据提取模块:从论文中提取元数据信息,例如,摘要、关键词等。3) 多模态大型语言模型:使用预训练的多模态大型语言模型作为标题生成器,例如,基于Transformer的模型。4) 风格迁移模块:将作者的个人资料信息和元数据信息融入到多模态大型语言模型中,以实现作者风格的迁移。
关键创新:论文的关键创新在于将作者的个人资料数据和元数据信息融入到多模态大型语言模型中,从而实现了作者风格的迁移。这种方法可以有效地提高图表标题的个性化程度,使其更符合作者的写作风格。
关键设计:论文的关键设计包括:1) 使用丰富的作者个人资料数据,例如,发表论文数量、研究领域、常用词汇等。2) 使用预训练的多模态大型语言模型作为标题生成器。3) 设计合适的风格迁移模块,将作者的个人资料信息和元数据信息融入到多模态大型语言模型中。4) 使用合适的损失函数来训练模型,例如,交叉熵损失函数和风格损失函数。
🖼️ 关键图片


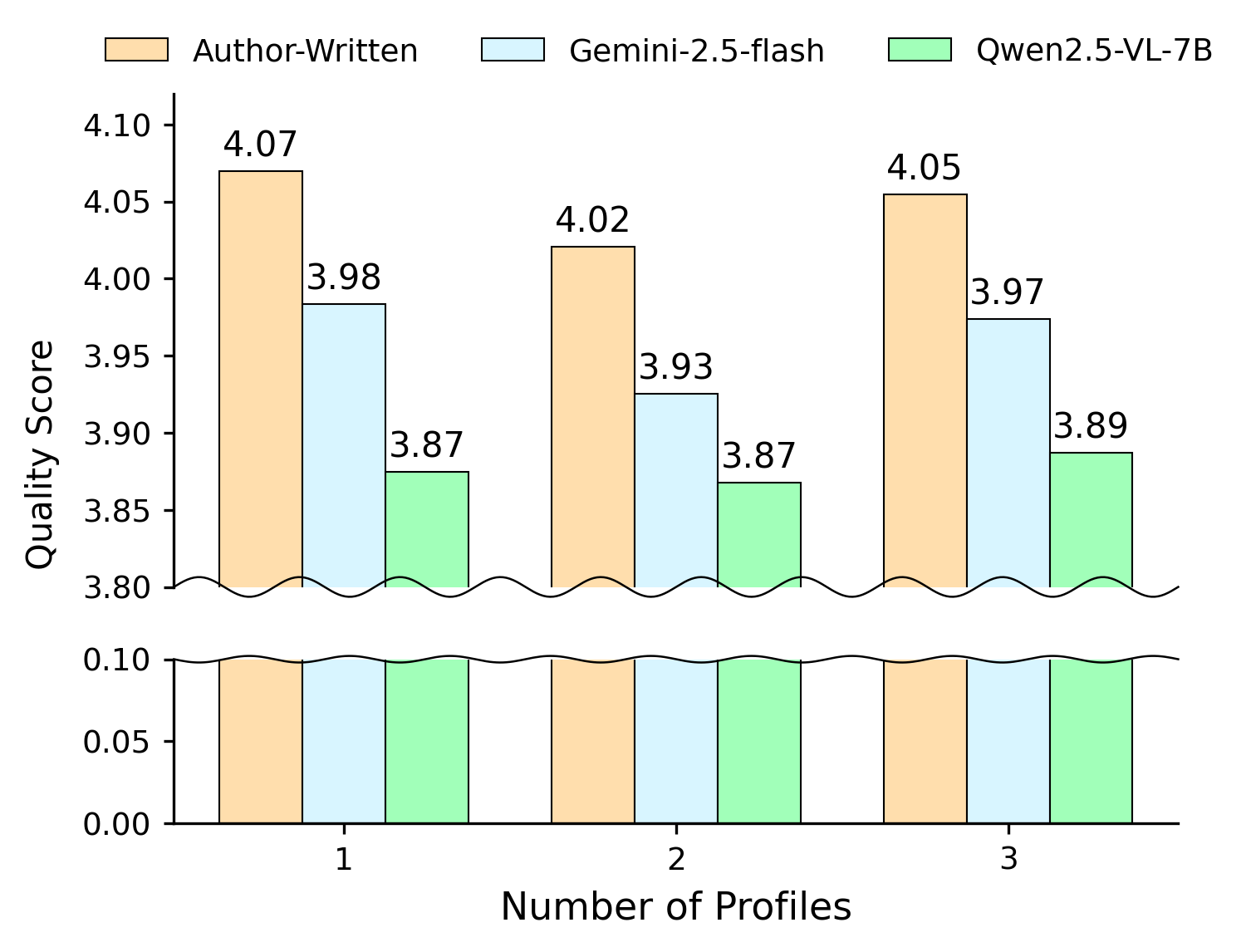
📊 实验亮点
实验结果表明,结合丰富的作者个人资料数据和元数据,可以显著提高多模态大型语言模型的个性化性能。然而,研究也揭示了匹配作者风格和保持标题质量之间存在权衡。未来的研究可以探索如何更好地平衡这两个目标,以开发更实用的标题自动化系统。
🎯 应用场景
该研究成果可应用于科学论文写作辅助工具,帮助研究人员自动生成具有个人风格的图表标题,提高写作效率和论文质量。此外,该技术还可扩展到其他文本生成任务,例如,个性化新闻标题生成、个性化邮件生成等,具有广泛的应用前景。
📄 摘要(原文)
We study personalized figure caption generation using author profile data from scientific papers. Our experiments demonstrate that rich author profile data, combined with relevant metadata, can significantly improve the personalization performance of multimodal large language models. However, we also reveal a fundamental trade-off between matching author style and maintaining caption quality. Our findings offer valuable insights and future directions for developing practical caption automation systems that balance both objectives. This work was conducted as part of the 3rd SciCap challenge.