Think Less, Label Better: Multi-Stage Domain-Grounded Synthetic Data Generation for Fine-Tuning Large Language Models in Telecommunications
作者: Chenhua Shi, Gregor Macdonald, Bhavika Jalli, Wanlu Lei, John Zou, Mridul Jain, Joji Philip
分类: cs.CL, cs.AI, cs.IT, cs.NI
发布日期: 2025-09-30 (更新: 2026-01-30)
备注: 6 pages, 6 figures, 5 tables, IEEE ICC 2026
💡 一句话要点
提出基于领域知识图谱的多阶段合成数据生成方法,用于电信领域大语言模型微调
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 合成数据生成 领域知识图谱 检索增强生成 大语言模型微调 电信网络故障排除
📋 核心要点
- 人工标注领域特定数据成本高昂,尤其是在电信等需要专业知识的场景。
- 论文提出一种全自动的检索增强流水线,利用领域知识图谱生成高质量合成数据。
- 该方法通过多阶段框架和质量过滤,生成适用于大语言模型微调的优质数据集。
📝 摘要(中文)
大型语言模型(LLM)的成功很大程度上依赖于大规模、高质量的指令跟随和强化学习数据集。然而,通过人工标注生成此类数据非常耗时,尤其是在电信网络故障排除等特定领域任务中,准确的响应需要深厚的技术专业知识和上下文理解。本文提出了一种全自动、检索增强的流水线,用于生成基于结构化领域知识的合成问答(QA)对。我们的多阶段框架集成了检索器、基础生成器和精炼模型,利用从领域特定知识图谱中检索的文档来合成和增强QA对。为了确保数据质量,我们采用定制的基于RAGAS的评分来过滤低质量样本,从而生成适用于强化微调(RFT)的高质量数据集。我们在一个真实的电信场景中,重点关注无线接入网(RAN)故障排除,展示了我们的方法。由此产生的流水线无需人工干预即可生成复杂的、上下文丰富的故障排除解决方案计划。这项工作为在特定领域构建指令和强化数据集提供了一种可扩展的解决方案,显著减少了对人工标注的依赖,同时保持了较高的技术保真度。
🔬 方法详解
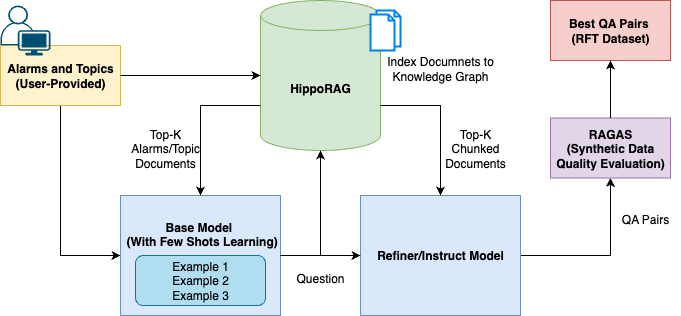
问题定义:论文旨在解决电信领域,特别是无线接入网(RAN)故障排除场景下,缺乏高质量、大规模的指令跟随和强化学习数据集的问题。现有方法依赖人工标注,成本高、效率低,且需要领域专家参与。
核心思路:核心思路是利用领域知识图谱,通过检索增强生成(RAG)技术,自动生成高质量的合成问答数据。通过多阶段的生成和精炼,以及基于RAGAS的质量评估,确保生成的数据既具有领域知识的准确性,又符合指令跟随的要求。
技术框架:整体框架包含三个主要阶段:1) 检索器:从领域知识图谱中检索相关文档;2) 基础生成器:利用检索到的文档生成初始的问答对;3) 精炼模型:对生成的问答对进行优化和改进,使其更符合实际场景和指令要求。此外,还包含一个基于RAGAS的质量评估模块,用于过滤低质量的样本。
关键创新:关键创新在于将检索增强生成技术与多阶段的生成和精炼相结合,并引入了定制的RAGAS评分机制,从而在无需人工干预的情况下,生成高质量的领域特定合成数据。与传统的人工标注方法相比,该方法具有更高的效率和可扩展性。
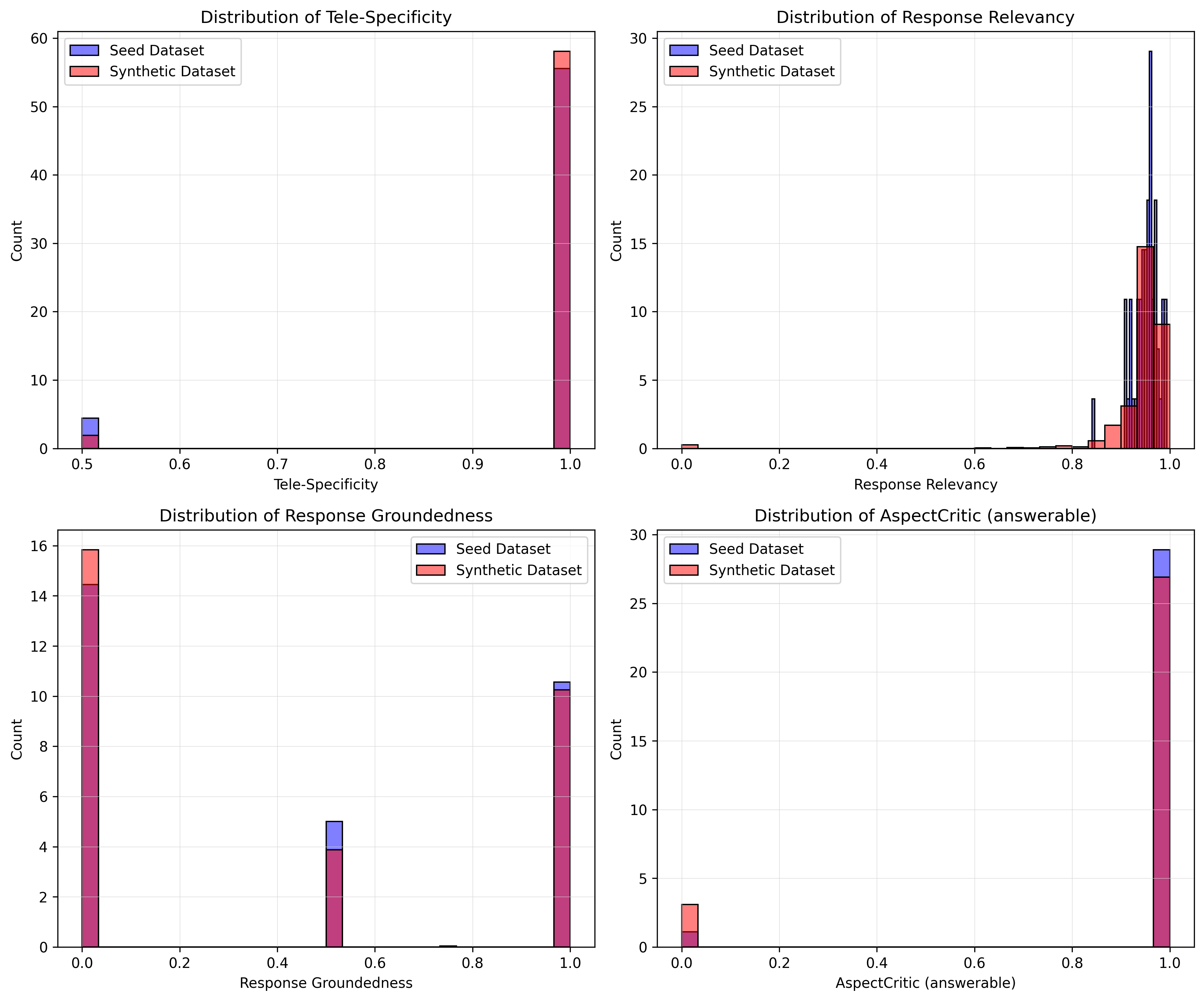
关键设计:论文中定制的RAGAS评分是关键设计之一,用于评估生成数据的质量,包括上下文相关性、答案的准确性和流畅性等。具体的参数设置和模型选择(例如,检索器的类型、生成模型的架构)可能需要根据具体的领域知识图谱和任务进行调整。损失函数的设计可能涉及到指令跟随的损失和领域知识一致性的损失。
🖼️ 关键图片

📊 实验亮点
论文在真实的电信无线接入网(RAN)故障排除场景中验证了该方法的有效性。实验结果表明,该方法能够生成复杂的、上下文丰富的故障排除解决方案计划,且无需人工干预。通过定制的RAGAS评分过滤低质量样本,保证了数据集的质量,使其适用于强化微调(RFT)。具体的性能数据和对比基线在论文中未明确给出,属于未知信息。
🎯 应用场景
该研究成果可广泛应用于各个专业领域,例如金融、医疗、法律等,通过构建领域知识图谱并结合该方法,可以低成本、高效地生成高质量的训练数据,从而提升大语言模型在特定领域的性能。该方法还可以用于构建智能客服、知识问答系统等应用,提供更专业、更准确的领域知识服务。
📄 摘要(原文)
The success of large language models (LLMs) depends heavily on large-scale, high-quality instruction-following and reinforcement datasets. However, generating such data through human annotation is prohibitively time-consuming particularly for domain-specific tasks like telecom network troubleshooting, where accurate responses require deep technical expertise and contextual understanding. In this paper, we present a fully automated, retrieval-augmented pipeline for generating synthetic question-answer (QA) pairs grounded in structured domain knowledge. Our multi-stage framework integrates a retriever, base generator, and refinement model to synthesize and enhance QA pairs using documents retrieved from a domain-specific knowledge graph. To ensure data quality, we employ customized RAGAS-based scoring to filter low-quality samples, producing a high-quality dataset suitable for reinforcement fine-tuning (RFT). We demonstrate our approach in a real-world telecom scenario focused on radio access network (RAN) troubleshooting. The resulting pipeline generates complex, context-rich troubleshooting solution plans without human intervention. This work offers a scalable solution for building instruction and reinforcement datasets in specialized domains, significantly reducing dependence on manual labeling while maintaining high technical fidelity.