LD-MoLE: Learnable Dynamic Routing for Mixture of LoRA Experts
作者: Yuan Zhuang, Yi Shen, Yuexin Bian, Qing Su, Shihao Ji, Yuanyuan Shi, Fei Miao
分类: cs.CL, cs.AI
发布日期: 2025-09-30
💡 一句话要点
提出LD-MoLE,用于LoRA专家混合模型的自适应动态路由。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 专家混合模型 动态路由 参数高效微调 大语言模型 自适应学习
📋 核心要点
- 现有MoE方法依赖TopK路由,需精细调参且为每个token分配固定数量的专家。
- LD-MoLE采用可微路由函数和闭式解,实现token和层级自适应的专家分配。
- 实验表明,LD-MoLE在多个基准测试中超越SOTA方法,并学习到有效的专家分配策略。
📝 摘要(中文)
本文提出了一种名为LD-MoLE的、用于LoRA专家混合模型的可学习动态路由机制,旨在实现自适应的、token相关的、以及层级的专家分配。该方法使用可微路由函数和闭式解来替代不可微的TopK选择。此外,该设计允许模型自适应地确定每个token在不同层激活的专家数量。同时,引入了解析稀疏性控制目标来约束激活专家的数量。在Qwen3-1.7B和Llama-3.2-3B模型上的大量实验表明,LD-MoLE在各种基准测试中取得了优于现有最佳方法的平均分数。该方法不仅实现了卓越的性能,还展示了学习token相关和层级专家分配的能力。
🔬 方法详解
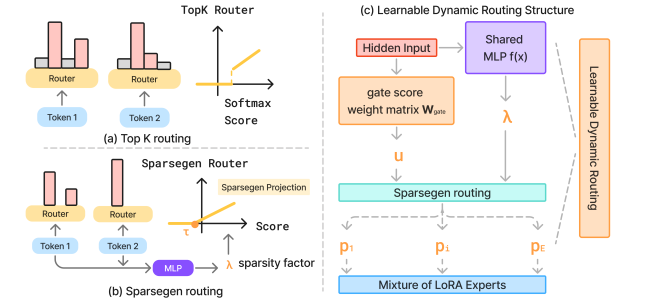
问题定义:现有的大语言模型(LLMs)的专家混合(MoE)方法,通常采用TopK路由机制。这种机制存在两个主要问题:一是需要手动调整超参数K,这增加了训练的复杂性;二是每个token被分配固定数量的专家,无法根据token的语义信息和网络层级的不同进行自适应调整,限制了模型的表达能力。
核心思路:LD-MoLE的核心思路是使用可学习的动态路由机制来替代传统的TopK路由。通过引入可微的路由函数,模型可以根据token的特征自适应地选择激活的专家,并且允许不同层级的网络选择不同数量的专家。这种动态路由机制能够更好地利用模型参数,提高模型的性能。
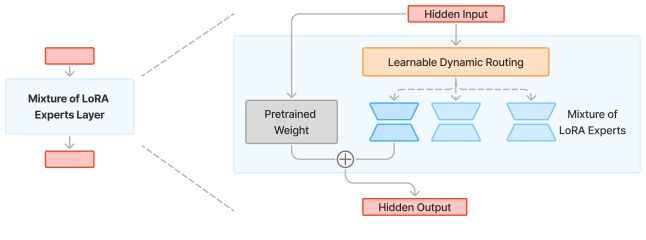
技术框架:LD-MoLE的技术框架主要包含以下几个模块:首先,输入token经过embedding层后,进入LoRA专家混合层。在每一层中,模型首先计算每个token与各个专家之间的路由权重,然后使用可微的路由函数将这些权重转化为激活概率。接下来,根据激活概率选择激活的专家,并将token的表示传递给这些专家进行处理。最后,将各个专家的输出进行加权融合,得到最终的输出表示。
关键创新:LD-MoLE最重要的技术创新点在于其可学习的动态路由机制。与传统的TopK路由相比,LD-MoLE的路由机制是可微的,可以通过反向传播进行训练。此外,LD-MoLE允许模型自适应地确定每个token在不同层激活的专家数量,从而更好地利用模型参数。
关键设计:LD-MoLE的关键设计包括:1) 使用sigmoid函数作为可微的路由函数,将路由权重转化为激活概率;2) 引入闭式解来计算激活概率,避免了复杂的优化过程;3) 设计了解析稀疏性控制目标,通过正则化激活专家的数量,防止模型过度拟合;4) 使用LoRA(Low-Rank Adaptation)技术来减少训练参数,提高训练效率。
🖼️ 关键图片

📊 实验亮点
在Qwen3-1.7B和Llama-3.2-3B模型上的实验结果表明,LD-MoLE在多个基准测试中取得了优于现有最佳方法的平均分数。具体而言,LD-MoLE在某些任务上的性能提升超过了5%,并且展示了学习token相关和层级专家分配的能力。这些结果证明了LD-MoLE的有效性和优越性。
🎯 应用场景
LD-MoLE具有广泛的应用前景,可以应用于各种需要高效微调和模型压缩的大语言模型场景,例如自然语言处理、机器翻译、文本生成等。通过自适应的专家选择,LD-MoLE能够更好地适应不同的任务和数据,提高模型的性能和效率。未来,LD-MoLE有望成为一种通用的模型微调和压缩技术,推动大语言模型在各个领域的应用。
📄 摘要(原文)
Recent studies have shown that combining parameter-efficient fine-tuning (PEFT) with mixture-of-experts (MoE) is an effective strategy for adapting large language models (LLMs) to the downstream tasks. However, most existing approaches rely on conventional TopK routing, which requires careful hyperparameter tuning and assigns a fixed number of experts to each token. In this work, we propose LD-MoLE, a Learnable Dynamic routing mechanism for Mixture of LoRA Experts that enables adaptive, token-dependent, and layer-wise expert allocation. Our method replaces the non-differentiable TopK selection with a differentiable routing function and a closed-form solution. Moreover, our design allows the model to adaptively determine the number of experts to activate for each token at different layers. In addition, we introduce an analytical sparsity control objective to regularize the number of activated experts. Extensive experiments on the Qwen3-1.7B and Llama-3.2-3B models show that LD-MoLE achieves the highest average scores compared to state-of-the-art baselines, across a diverse set of benchmarks. Our method not only achieves superior performance, but also demonstrates the ability to learn token-dependent and layer-wise expert allocation.