The Media Bias Detector: A Framework for Annotating and Analyzing the News at Scale
作者: Samar Haider, Amir Tohidi, Jenny S. Wang, Timothy Dörr, David M. Rothschild, Chris Callison-Burch, Duncan J. Watts
分类: cs.CL
发布日期: 2025-09-30
💡 一句话要点
提出Media Bias Detector框架,用于大规模标注和分析新闻媒体的偏见
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 媒体偏见检测 自然语言处理 大型语言模型 新闻分析 舆情监控
📋 核心要点
- 现有方法难以大规模测量新闻媒体在选题和框架选择上的微妙偏见。
- 利用大型语言模型和实时新闻抓取,自动提取政治倾向、语气等结构化标注。
- 构建了包含大量新闻文章的数据集和交互式平台,揭示新闻报道中的偏见模式。
📝 摘要(中文)
本文介绍了一个大型、持续(从2024年1月1日至今)、近乎实时的数据集和计算框架,旨在系统地研究新闻报道中的选择性偏见和框架性偏见。该流程将大型语言模型(LLM)与可扩展的、近乎实时的新闻抓取相结合,以提取结构化的标注信息,包括政治倾向、语气、主题、文章类型和重大事件,每天处理数百篇文章。我们在多个层面(句子层面、文章层面和出版商层面)量化这些报道维度,从而扩展了研究人员在现代新闻环境中分析媒体偏见的方式。除了精心策划的数据集外,我们还发布了一个交互式Web平台,方便用户探索这些数据。这些贡献共同建立了一种可重用的方法,用于大规模研究媒体偏见,为未来的研究提供实证资源。我们还展示了一些例子(侧重于2024年审查的15万多篇文章),说明这个新颖的数据集如何揭示新闻报道和偏见中的深刻模式,从而支持学术研究和改善媒体责任的实际工作。
🔬 方法详解
问题定义:该论文旨在解决大规模测量和分析新闻媒体偏见的问题。现有方法难以捕捉媒体在选题和框架选择上的微妙偏见,缺乏可扩展性和实时性。
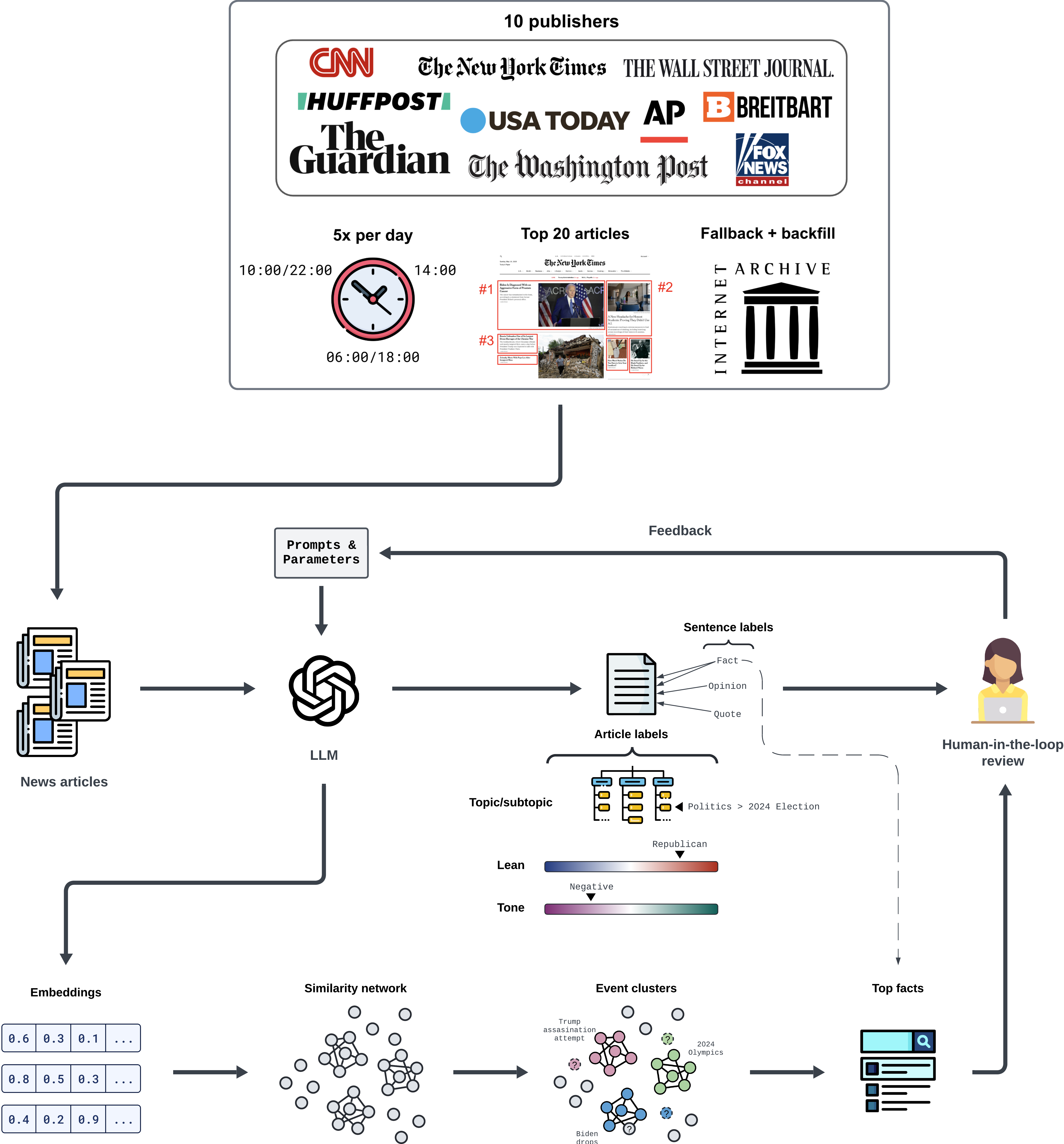
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大自然语言理解能力,结合实时新闻抓取技术,自动化地提取新闻文章中的结构化信息,从而量化媒体偏见的各个维度。这种方法旨在克服传统方法在规模和效率上的限制。
技术框架:该框架包含以下主要模块:1) 近实时新闻抓取:从多个新闻来源抓取新闻文章。2) LLM标注:使用LLM提取文章的政治倾向、语气、主题、文章类型和重大事件等信息。3) 多层次分析:在句子、文章和出版商层面量化这些维度。4) 数据集和交互式平台:提供可供研究人员使用的数据集和交互式Web平台。
关键创新:该论文的关键创新在于将LLM应用于大规模新闻偏见分析,并构建了一个近实时、可扩展的框架。与传统的人工标注或基于规则的方法相比,该方法能够更高效、更准确地提取新闻文章中的偏见信息。
关键设计:论文中没有详细说明LLM的具体选择和训练细节,以及用于量化偏见的具体指标和算法。这些细节可能在后续的论文或技术报告中给出。数据集的时间跨度是从2024年1月1日至今,保证了数据的时效性。
🖼️ 关键图片
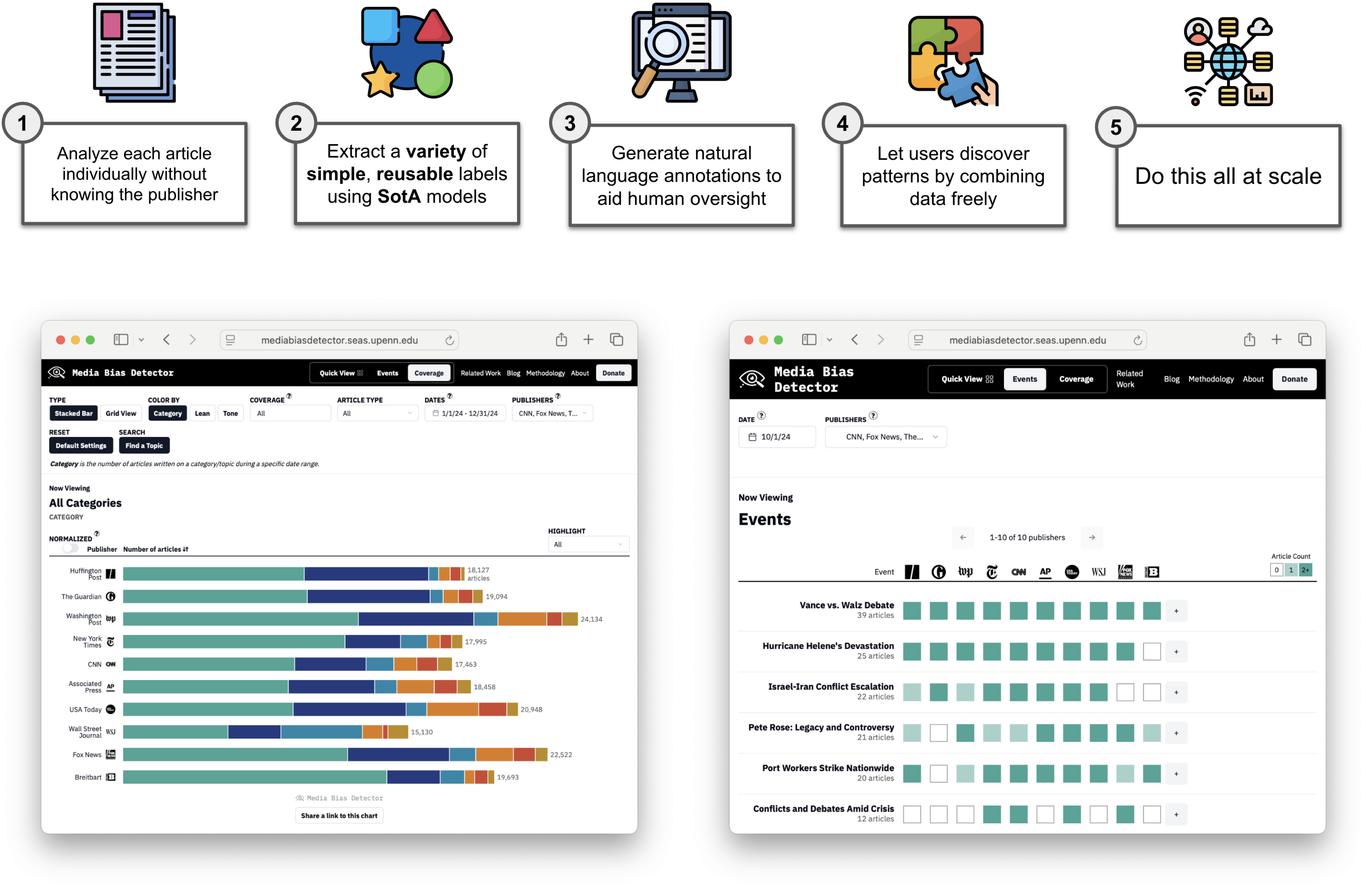

📊 实验亮点
论文构建了一个包含15万+文章的数据集,并展示了如何利用该数据集揭示新闻报道和偏见中的深刻模式。通过对2024年数据的分析,验证了该框架在识别媒体偏见方面的有效性,为未来的研究提供了实证资源。
🎯 应用场景
该研究成果可应用于媒体偏见检测、新闻内容分析、舆情监控、虚假信息识别等领域。通过分析新闻报道中的偏见模式,可以提高公众对媒体的批判性思维能力,促进媒体的责任感和透明度,并为政策制定者提供参考。
📄 摘要(原文)
Mainstream news organizations shape public perception not only directly through the articles they publish but also through the choices they make about which topics to cover (or ignore) and how to frame the issues they do decide to cover. However, measuring these subtle forms of media bias at scale remains a challenge. Here, we introduce a large, ongoing (from January 1, 2024 to present), near real-time dataset and computational framework developed to enable systematic study of selection and framing bias in news coverage. Our pipeline integrates large language models (LLMs) with scalable, near-real-time news scraping to extract structured annotations -- including political lean, tone, topics, article type, and major events -- across hundreds of articles per day. We quantify these dimensions of coverage at multiple levels -- the sentence level, the article level, and the publisher level -- expanding the ways in which researchers can analyze media bias in the modern news landscape. In addition to a curated dataset, we also release an interactive web platform for convenient exploration of these data. Together, these contributions establish a reusable methodology for studying media bias at scale, providing empirical resources for future research. Leveraging the breadth of the corpus over time and across publishers, we also present some examples (focused on the 150,000+ articles examined in 2024) that illustrate how this novel data set can reveal insightful patterns in news coverage and bias, supporting academic research and real-world efforts to improve media accountability.