Towards Structured Knowledge: Advancing Triple Extraction from Regional Trade Agreements using Large Language Models
作者: Durgesh Nandini, Rebekka Koch, Mirco Schoenfeld
分类: cs.CL, cs.CE, cs.IR, cs.LG
发布日期: 2025-09-29
💡 一句话要点
利用大型语言模型从区域贸易协定中提取结构化知识,构建贸易知识图谱。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 知识图谱 信息抽取 区域贸易协定 经济学应用
📋 核心要点
- 现有方法难以从非结构化的法律文本中有效提取贸易相关信息,阻碍了经济知识图谱的构建。
- 利用大型语言模型,通过零样本、单样本和少样本提示技术,从文本中提取主谓宾三元组。
- 使用Llama 3.1模型处理区域贸易协定文本,提取贸易信息,并评估不同提示策略的性能。
📝 摘要(中文)
本研究探讨了大型语言模型(LLMs)在提取结构化知识方面的有效性,具体形式为“主语-谓语-宾语”三元组。我们将该方法应用于经济学领域。研究结果可应用于广泛的场景,包括从自然语言法律贸易协定文本中创建经济贸易知识图谱。作为一个用例,我们将模型应用于区域贸易协定文本,以提取与贸易相关的信息三元组。我们特别探索了零样本、单样本和少样本提示技术,结合了正面和负面示例,并基于定量和定性指标评估了它们的性能。具体来说,我们使用Llama 3.1模型来处理非结构化的区域贸易协定文本并提取三元组。我们讨论了关键见解、挑战和潜在的未来方向,强调了语言模型在经济应用中的重要性。
🔬 方法详解
问题定义:论文旨在解决从非结构化的区域贸易协定文本中自动提取结构化知识的问题,具体表现为提取“主语-谓语-宾语”三元组。现有方法,如传统的信息抽取技术,在处理复杂的法律文本时,往往需要大量的人工标注和特征工程,效率低下且泛化能力有限。
核心思路:论文的核心思路是利用大型语言模型(LLMs)强大的语言理解和生成能力,通过不同的提示策略(零样本、单样本、少样本),引导LLM直接从文本中抽取三元组。这种方法避免了传统方法的复杂流程,并有望实现更高的自动化程度和更好的泛化能力。
技术框架:整体框架包括以下几个阶段:1) 数据准备:收集区域贸易协定文本;2) 提示工程:设计零样本、单样本和少样本提示,包括正面和负面示例;3) 模型推理:使用Llama 3.1模型,根据不同的提示,从文本中提取三元组;4) 评估:使用定量和定性指标评估提取的三元组的质量。
关键创新:关键创新在于将大型语言模型应用于经济领域的结构化知识提取任务,并探索了不同提示策略的效果。通过实验证明,适当的提示策略可以显著提高LLM在特定领域的知识提取能力。
关键设计:论文的关键设计包括:1) 提示策略的设计,包括零样本、单样本和少样本提示,以及正面和负面示例的选择;2) 使用Llama 3.1模型作为基础模型;3) 使用定量指标(如精确率、召回率、F1值)和定性分析来评估提取的三元组的质量。
🖼️ 关键图片

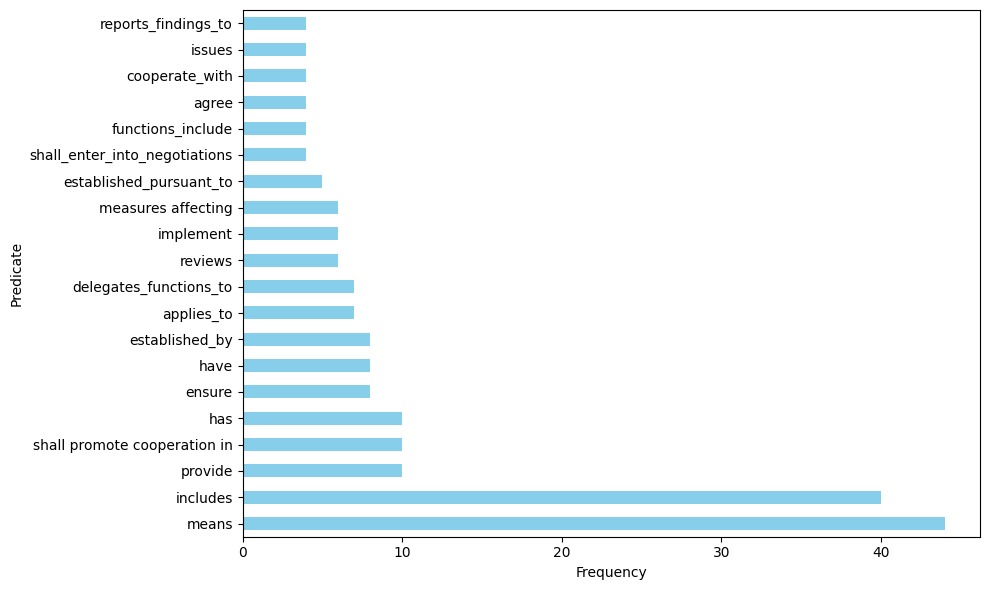
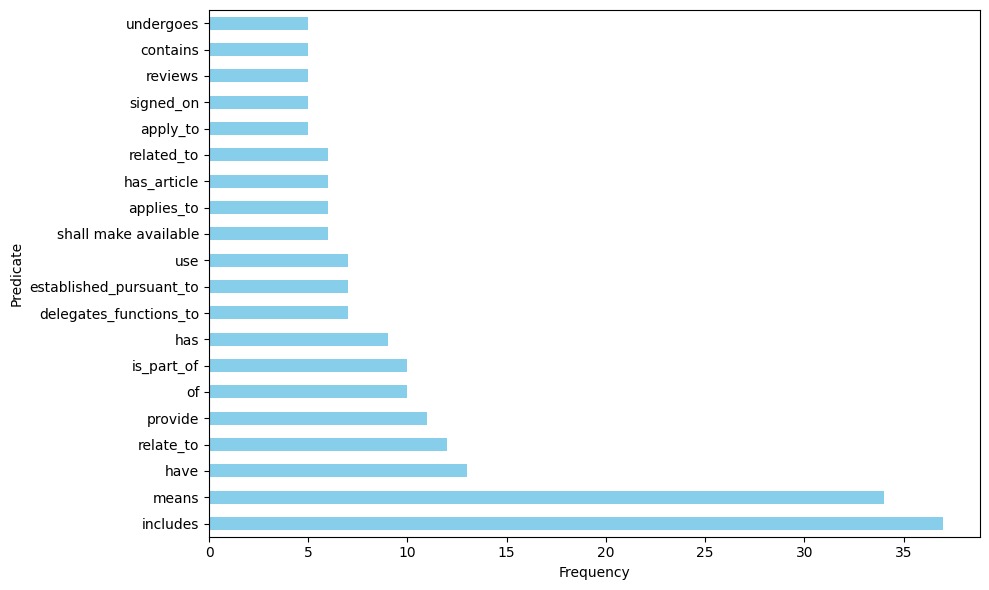
📊 实验亮点
该研究使用Llama 3.1模型,通过不同的prompting策略,从区域贸易协定文本中提取贸易相关三元组。实验结果表明,适当的prompting策略能够有效提升信息抽取的准确率和召回率。虽然具体的性能数据未在摘要中给出,但研究强调了prompting技术在经济领域应用中的重要性。
🎯 应用场景
该研究成果可应用于构建经济贸易知识图谱,为经济分析、政策制定和贸易决策提供支持。通过自动提取贸易协定中的关键信息,可以帮助研究人员和政策制定者更好地理解贸易关系,评估贸易政策的影响,并发现潜在的贸易机会。未来,该方法可以扩展到其他经济领域的文本数据,例如公司报告、新闻文章等。
📄 摘要(原文)
This study investigates the effectiveness of Large Language Models (LLMs) for the extraction of structured knowledge in the form of Subject-Predicate-Object triples. We apply the setup for the domain of Economics application. The findings can be applied to a wide range of scenarios, including the creation of economic trade knowledge graphs from natural language legal trade agreement texts. As a use case, we apply the model to regional trade agreement texts to extract trade-related information triples. In particular, we explore the zero-shot, one-shot and few-shot prompting techniques, incorporating positive and negative examples, and evaluate their performance based on quantitative and qualitative metrics. Specifically, we used Llama 3.1 model to process the unstructured regional trade agreement texts and extract triples. We discuss key insights, challenges, and potential future directions, emphasizing the significance of language models in economic applications.