How Training Data Shapes the Use of Parametric and In-Context Knowledge in Language Models
作者: Minsung Kim, Dong-Kyum Kim, Jea Kwon, Nakyeong Yang, Kyomin Jung, Meeyoung Cha
分类: cs.CL, cs.AI
发布日期: 2025-09-29 (更新: 2026-01-07)
备注: 16 pages
💡 一句话要点
揭示训练数据特性如何影响语言模型参数知识和上下文知识的利用
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 参数知识 上下文知识 训练数据 知识冲突 预训练 知识表示
📋 核心要点
- 现有研究缺乏对语言模型如何协调利用参数知识和上下文知识的训练条件理解。
- 通过控制训练数据属性,探究文档内重复、不一致性和知识频率分布对知识利用的影响。
- 实验表明,特定训练数据属性组合能提升知识利用和冲突解决能力,并在真实预训练中得到验证。
📝 摘要(中文)
大型语言模型不仅利用训练期间获得的参数知识,还利用推理时提供的上下文知识,尽管没有明确的训练目标来同时使用这两种知识来源。先前的工作表明,当这些知识来源冲突时,模型会根据其内部置信度来解决这种冲突,对于高置信度的事实更倾向于参数知识,而对于不太熟悉的事实则倾向于上下文信息。然而,产生这种知识利用行为的训练条件仍不清楚。为了解决这个差距,我们进行了受控实验,在训练语言模型的同时系统地操纵训练数据的关键属性。我们的结果揭示了一个违反直觉的发现:要使稳健的知识利用和冲突解决出现,必须同时存在三个通常被认为有害的属性:(i)文档内信息的重复,(ii)适度的文档内不一致性,以及(iii)倾斜的知识频率分布。我们进一步验证了在受控环境中观察到的相同训练动态也出现在真实世界的语言模型预训练中,并分析了后训练程序如何重塑模型的知识偏好。总之,我们的发现为训练和谐地整合参数知识和上下文知识的语言模型提供了具体的经验指导。
🔬 方法详解
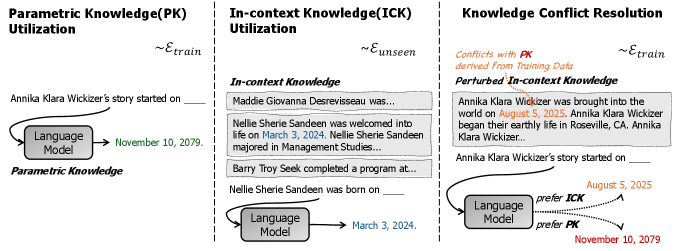
问题定义:论文旨在解决大型语言模型如何有效地利用和协调参数知识(训练中学到的知识)和上下文知识(推理时提供的知识)的问题。现有方法缺乏对训练数据特性如何影响模型知识利用行为的理解,尤其是在两种知识来源冲突时,模型如何选择和融合这些知识。
核心思路:论文的核心思路是通过控制训练数据的关键属性,观察这些属性对模型知识利用行为的影响。具体来说,研究人员关注文档内信息的重复、文档内不一致性和知识频率分布这三个属性,并探究它们如何共同影响模型对参数知识和上下文知识的偏好。
技术框架:论文采用受控实验的方式,首先构建具有特定属性的合成数据集,然后使用这些数据集训练语言模型。在训练完成后,通过设计特定的测试用例来评估模型在参数知识和上下文知识冲突时的表现。此外,论文还分析了真实世界语言模型预训练过程中的数据属性,并将结果与受控实验的结果进行比较。最后,研究了后训练程序(如微调)如何改变模型的知识偏好。
关键创新:论文的关键创新在于揭示了三个通常被认为有害的训练数据属性(文档内重复、适度的文档内不一致性和倾斜的知识频率分布)必须同时存在,才能使语言模型具备稳健的知识利用和冲突解决能力。这一发现挑战了以往的认知,并为训练更有效的语言模型提供了新的视角。
关键设计:论文的关键设计包括:(1) 精心设计的合成数据集,可以精确控制文档内重复、不一致性和知识频率分布等属性;(2) 针对知识冲突场景设计的测试用例,可以有效评估模型对参数知识和上下文知识的偏好;(3) 对真实世界预训练数据的分析,验证了受控实验的发现;(4) 对后训练程序影响的分析,揭示了微调等技术如何改变模型的知识偏好。
🖼️ 关键图片


📊 实验亮点
实验结果表明,文档内信息重复、适度不一致性和倾斜的知识频率分布这三个属性同时存在时,模型在知识利用和冲突解决方面表现更佳。研究还验证了在真实预训练数据中也观察到类似的训练动态。例如,通过控制训练数据属性,可以显著影响模型对参数知识和上下文知识的偏好。
🎯 应用场景
该研究成果可应用于指导语言模型的训练,使其更好地整合参数知识和上下文知识,从而提高模型在各种自然语言处理任务中的性能,例如问答、文本生成和知识推理。此外,该研究还有助于理解语言模型内部知识表示和利用机制,为开发更智能、更可靠的AI系统奠定基础。
📄 摘要(原文)
Large language models leverage not only parametric knowledge acquired during training but also in-context knowledge provided at inference time, despite the absence of explicit training objectives for using both sources. Prior work has further shown that when these knowledge sources conflict, models resolve the tension based on their internal confidence, preferring parametric knowledge for high-confidence facts while deferring to contextual information for less familiar ones. However, the training conditions that give rise to such knowledge utilization behaviors remain unclear. To address this gap, we conduct controlled experiments in which we train language models while systematically manipulating key properties of the training data. Our results reveal a counterintuitive finding: three properties commonly regarded as detrimental must co-occur for robust knowledge utilization and conflict resolution to emerge: (i) intra-document repetition of information, (ii) a moderate degree of within-document inconsistency, and (iii) a skewed knowledge frequency distribution. We further validate that the same training dynamics observed in our controlled setting also arise during real-world language model pretraining, and we analyze how post-training procedures can reshape models' knowledge preferences. Together, our findings provide concrete empirical guidance for training language models that harmoniously integrate parametric and in-context knowledge.