AdaDetectGPT: Adaptive Detection of LLM-Generated Text with Statistical Guarantees
作者: Hongyi Zhou, Jin Zhu, Pingfan Su, Kai Ye, Ying Yang, Shakeel A O B Gavioli-Akilagun, Chengchun Shi
分类: cs.CL, cs.AI, cs.LG, stat.ML
发布日期: 2025-09-29 (更新: 2026-02-01)
备注: Accepted by NeurIPS2025
🔗 代码/项目: GITHUB
💡 一句话要点
AdaDetectGPT:利用统计保证自适应检测LLM生成文本
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM文本检测 自适应学习 统计保证 logits分析 witness函数
📋 核心要点
- 现有基于logits的LLM文本检测器仅依赖对数概率,性能存在优化空间。
- AdaDetectGPT自适应地从训练数据学习witness函数,增强logits检测器的性能。
- 实验结果表明,AdaDetectGPT在多种数据集和LLM组合下,性能提升高达37%。
📝 摘要(中文)
本文研究了判断一段文本是由人类还是由大型语言模型(LLM)生成的问题。现有的基于logits的先进检测器利用从给定源LLM评估的观察文本的对数概率导出的统计数据。然而,仅仅依赖对数概率可能不是最优的。为此,我们引入了AdaDetectGPT——一种新颖的分类器,它从训练数据中自适应地学习一个witness函数,以提高基于logits的检测器的性能。我们提供了关于其真正率、假正率、真负率和假负率的统计保证。大量的数值研究表明,在各种数据集和LLM的组合中,AdaDetectGPT几乎一致地改进了最先进的方法,改进幅度可达37%。我们的方法的Python实现在https://github.com/Mamba413/AdaDetectGPT上提供。
🔬 方法详解
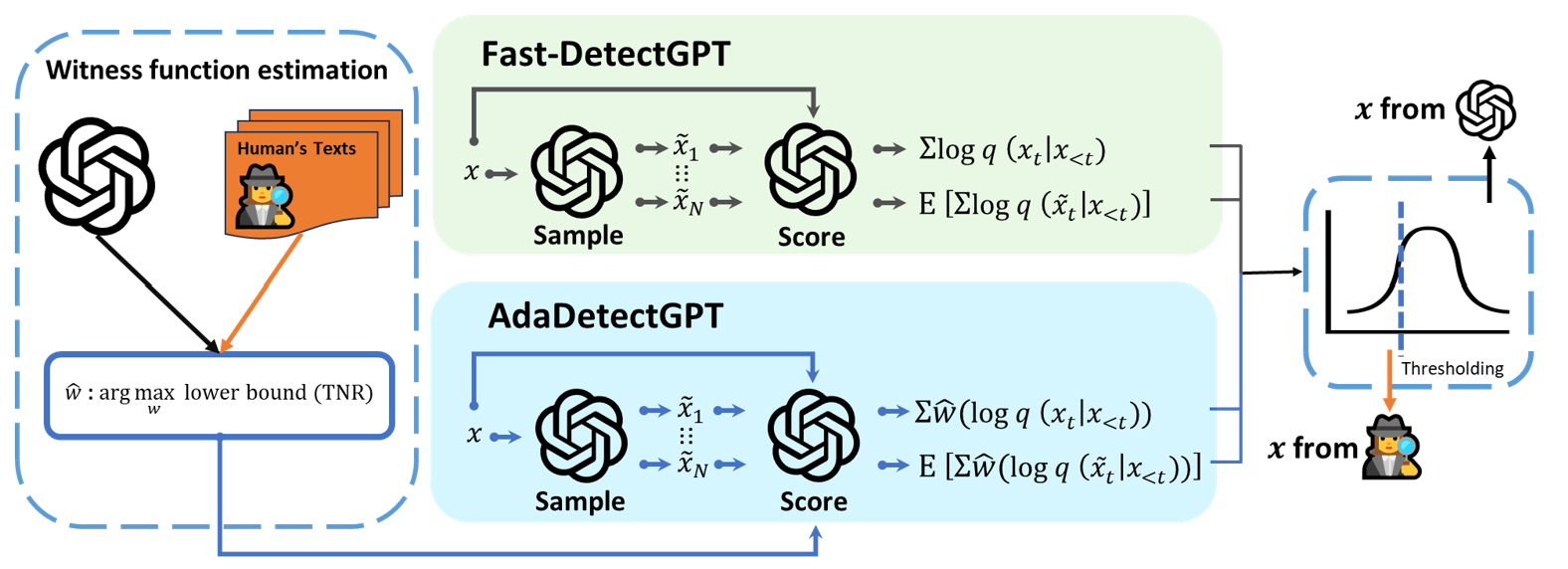
问题定义:论文旨在解决区分文本是由人类撰写还是由大型语言模型(LLM)生成的问题。现有方法主要依赖于文本的对数概率,但这种方法可能并非最优,存在提升空间。现有方法的痛点在于对单一指标的过度依赖,缺乏自适应性,难以应对不同LLM和数据集的差异。
核心思路:论文的核心思路是引入一个自适应学习的witness函数,该函数能够从训练数据中学习,从而更好地利用logits信息,提高检测器的性能。通过学习一个更具区分性的特征表示,弥补单纯依赖对数概率的不足。这种自适应性使得检测器能够更好地适应不同的LLM和数据集。
技术框架:AdaDetectGPT的整体框架包含以下几个主要步骤:1) 使用给定的LLM计算输入文本的logits;2) 利用logits计算统计特征(例如,对数概率);3) 使用训练数据自适应地学习一个witness函数;4) 将统计特征输入到witness函数中,得到最终的分类结果。该框架的核心在于witness函数的学习过程,它通过优化目标函数,使得LLM生成的文本和人类撰写的文本在特征空间中尽可能分离。
关键创新:AdaDetectGPT的关键创新在于自适应学习witness函数。与现有方法不同,AdaDetectGPT不是直接使用预定义的统计量,而是通过训练数据学习一个能够更好区分LLM生成文本和人类撰写文本的函数。这种自适应性使得AdaDetectGPT能够更好地适应不同的LLM和数据集,从而提高检测性能。
关键设计:关于witness函数的具体形式,论文中可能使用了神经网络或者其他机器学习模型来实现。关键的技术细节可能包括:1) witness函数的网络结构(例如,全连接网络、卷积神经网络等);2) 损失函数的设计(例如,交叉熵损失、hinge loss等);3) 优化算法的选择(例如,Adam、SGD等);4) 正则化方法的使用(例如,L1正则化、L2正则化等)。具体的参数设置和网络结构需要在论文中进一步查找。
🖼️ 关键图片

📊 实验亮点
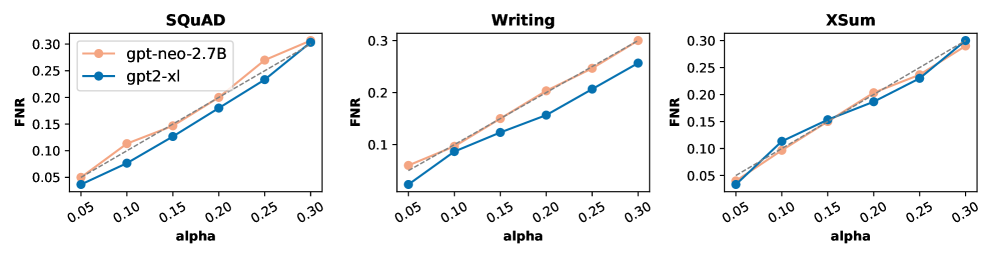
实验结果表明,AdaDetectGPT在各种数据集和LLM的组合中,几乎一致地改进了最先进的方法。具体的性能提升幅度可达37%,表明AdaDetectGPT在LLM生成文本检测方面具有显著的优势。该方法在多种场景下均表现出优越的性能,验证了其鲁棒性和泛化能力。
🎯 应用场景
该研究成果可应用于内容安全、学术诚信、舆情分析等领域。例如,可以用于检测网络上是否存在大量由LLM生成的虚假信息,或者帮助教育机构检测学生提交的论文是否由LLM代写。未来,该技术可以与更复杂的检测方法结合,构建更强大的LLM生成文本检测系统。
📄 摘要(原文)
We study the problem of determining whether a piece of text has been authored by a human or by a large language model (LLM). Existing state of the art logits-based detectors make use of statistics derived from the log-probability of the observed text evaluated using the distribution function of a given source LLM. However, relying solely on log probabilities can be sub-optimal. In response, we introduce AdaDetectGPT -- a novel classifier that adaptively learns a witness function from training data to enhance the performance of logits-based detectors. We provide statistical guarantees on its true positive rate, false positive rate, true negative rate and false negative rate. Extensive numerical studies show AdaDetectGPT nearly uniformly improves the state-of-the-art method in various combination of datasets and LLMs, and the improvement can reach up to 37\%. A python implementation of our method is available at https://github.com/Mamba413/AdaDetectGPT.