Aligning Multilingual Reasoning with Verifiable Semantics from a High-Resource Expert Model
作者: Fahim Faisal, Kaiqiang Song, Song Wang, Simin Ma, Shujian Liu, Haoyun Deng, Sathish Reddy Indurthi
分类: cs.CL, cs.AI
发布日期: 2025-09-29
💡 一句话要点
提出PB-RLSVR框架,利用高资源专家模型提升多语言LLM的推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言推理 强化学习 枢轴模型 语义相似度 跨语言迁移
📋 核心要点
- 现有强化学习提升LLM推理能力的方法主要集中在英语上,导致跨语言性能存在显著差距。
- PB-RLSVR利用高性能英语LLM作为枢轴,通过语义可验证的奖励,将推理能力迁移到其他语言。
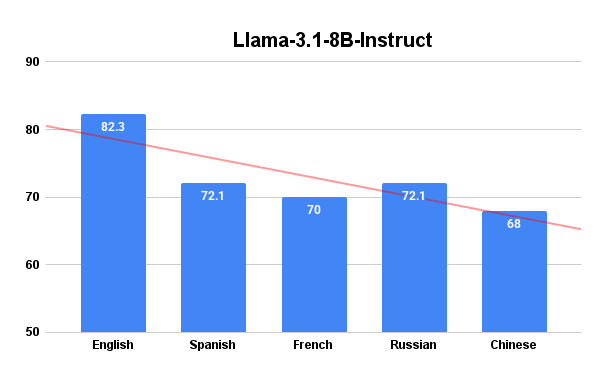
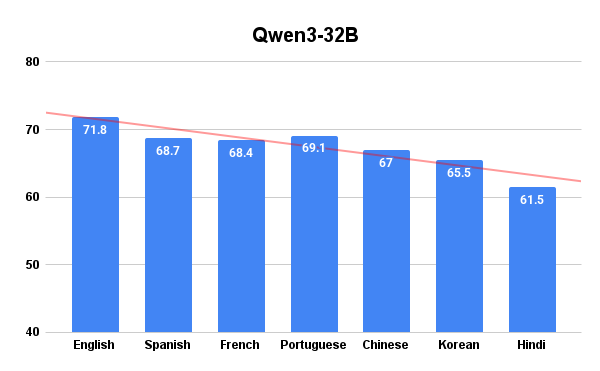
- 实验表明,PB-RLSVR显著提升了Llama-3.1-8B-Instruct和Qwen3-32B的多语言推理性能。
📝 摘要(中文)
本文提出了一种基于枢轴的强化学习框架,称为PB-RLSVR,该框架通过利用高表现的英语LLM作为“枢轴”模型,生成推理任务的参考答案,从而增强多语言LLM的推理能力。该方法避免了在目标语言中进行人工标注的需求。多语言模型根据其答案与英语参考答案的语义等价性获得奖励,从而有效地将枢轴模型的推理能力迁移到其他语言。研究人员探索了几种跨语言语义奖励函数,包括基于嵌入和机器翻译的函数。在多语言推理基准测试套件上的大量实验表明,该方法显著缩小了英语和其他语言之间的性能差距,大幅优于传统的PPO基线。具体而言,PB-RLSVR框架分别将Llama-3.1-8B-Instruct和Qwen3-32B的平均多语言性能提高了16.41%和10.17%,展示了一种强大且数据高效的方法来构建真正的多语言推理代理。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在推理能力方面取得了显著进展,但这些进展主要集中在英语上。对于其他语言,由于缺乏足够的训练数据和人工标注,LLM的推理能力相对较弱,导致跨语言性能存在显著差距。因此,如何提升LLM在多种语言环境下的推理能力是一个重要的研究问题。
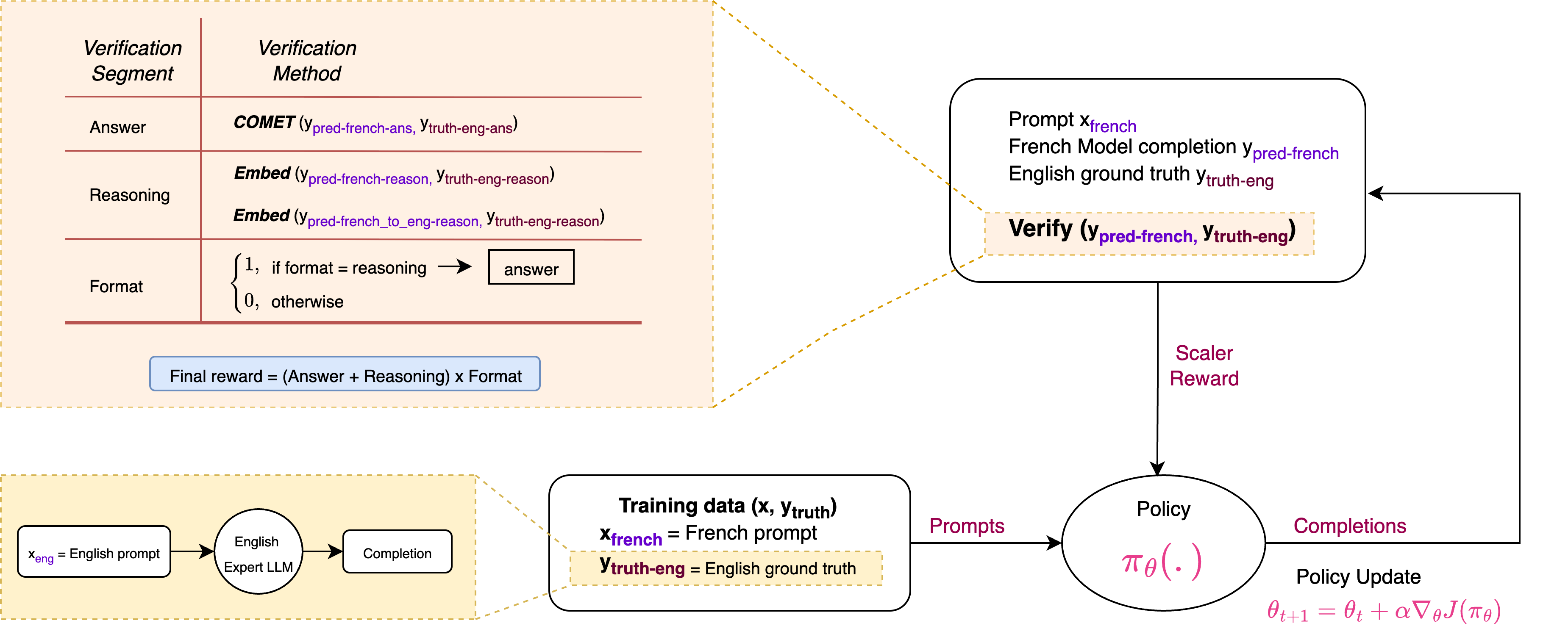
核心思路:本文的核心思路是利用一个高性能的英语LLM作为“枢轴”模型,通过强化学习的方式,将该模型的推理能力迁移到其他语言的LLM上。具体来说,首先使用英语LLM生成推理任务的参考答案,然后将多语言LLM的答案与英语参考答案进行语义比较,并根据语义相似度给予奖励。这样,多语言LLM就可以通过学习英语LLM的推理策略,从而提升自身的推理能力。
技术框架:PB-RLSVR框架主要包含以下几个模块:1) 枢轴模型:一个高性能的英语LLM,用于生成推理任务的参考答案。2) 多语言模型:需要提升推理能力的目标LLM。3) 奖励函数:用于衡量多语言模型答案与英语参考答案之间的语义相似度。4) 强化学习算法:用于训练多语言模型,使其能够生成与英语参考答案语义相似的答案。整个流程如下:首先,使用枢轴模型生成推理任务的参考答案;然后,将该任务输入到多语言模型中,得到其答案;接着,使用奖励函数计算多语言模型答案与英语参考答案之间的语义相似度,得到奖励值;最后,使用强化学习算法根据奖励值更新多语言模型的参数。
关键创新:PB-RLSVR的关键创新在于它提出了一种基于枢轴模型的强化学习方法,用于提升多语言LLM的推理能力。与传统的强化学习方法相比,PB-RLSVR不需要在目标语言中进行人工标注,而是通过利用高性能的英语LLM作为枢轴,自动生成训练数据,从而大大降低了训练成本。此外,PB-RLSVR还探索了几种跨语言语义奖励函数,包括基于嵌入和机器翻译的函数,进一步提升了模型的性能。
关键设计:在PB-RLSVR框架中,奖励函数的设计至关重要。本文探索了几种跨语言语义奖励函数,包括基于嵌入的奖励函数和基于机器翻译的奖励函数。基于嵌入的奖励函数通过计算多语言模型答案和英语参考答案的嵌入向量之间的相似度来衡量语义相似度。基于机器翻译的奖励函数首先将多语言模型答案翻译成英语,然后计算翻译后的答案与英语参考答案之间的相似度。此外,本文还使用了PPO(Proximal Policy Optimization)算法作为强化学习算法,用于训练多语言模型。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PB-RLSVR框架显著提升了多语言LLM的推理性能。具体而言,PB-RLSVR分别将Llama-3.1-8B-Instruct和Qwen3-32B的平均多语言性能提高了16.41%和10.17%,大幅优于传统的PPO基线。这些结果表明,PB-RLSVR是一种有效且数据高效的方法,可以用于构建真正的多语言推理代理。
🎯 应用场景
该研究成果可广泛应用于多语言智能客服、多语言机器翻译、跨语言信息检索等领域。通过提升LLM在多种语言环境下的推理能力,可以更好地服务于全球用户,促进不同语言文化之间的交流与合作。未来,该方法有望进一步扩展到更多语言和更复杂的推理任务中,为构建真正通用的人工智能系统奠定基础。
📄 摘要(原文)
While reinforcement learning has advanced the reasoning abilities of Large Language Models (LLMs), these gains are largely confined to English, creating a significant performance disparity across languages. To address this, we introduce Pivot-Based Reinforcement Learning with Semantically Verifiable Rewards (PB-RLSVR), a novel framework that enhances multilingual reasoning by circumventing the need for human-annotated data in target languages. Our approach employs a high-performing English LLM as a "pivot" model to generate reference responses for reasoning tasks. A multilingual model is then rewarded based on the semantic equivalence of its responses to the English reference, effectively transferring the pivot model's reasoning capabilities across languages. We investigate several cross-lingual semantic reward functions, including those based on embeddings and machine translation. Extensive experiments on a suite of multilingual reasoning benchmarks show that our method significantly narrows the performance gap between English and other languages, substantially outperforming traditional PPO baselines. Specifically, our PB-RLSVR framework improves the average multilingual performance of Llama-3.1-8B-Instruct and Qwen3-32B by 16.41% and 10.17%, respectively, demonstrating a powerful and data-efficient approach to building truly multilingual reasoning agents.