Generative Value Conflicts Reveal LLM Priorities
作者: Andy Liu, Kshitish Ghate, Mona Diab, Daniel Fried, Atoosa Kasirzadeh, Max Kleiman-Weiner
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-09-29
💡 一句话要点
ConflictScope:揭示LLM在价值冲突下的优先级偏好,并提出系统提示对齐方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 价值对齐 价值冲突 优先级排序 系统提示
📋 核心要点
- 现有LLM对齐方法缺乏对价值冲突场景的有效处理,导致模型在实际部署中难以权衡不同价值。
- ConflictScope通过自动生成价值冲突场景,并分析LLM的自由文本输出来评估其价值优先级。
- 实验表明,开放式环境中LLM更倾向于个人价值,但通过系统提示可以有效提升价值对齐程度。
📝 摘要(中文)
本文提出了一种名为ConflictScope的自动流程,用于评估大型语言模型(LLM)在面对价值冲突时如何进行优先级排序。现有对齐数据集缺乏价值冲突场景,为此,ConflictScope自动生成LLM需要在多个用户自定义价值之间进行权衡的场景。该流程使用LLM编写的“用户提示”来引导目标模型,并通过分析其自由文本输出来推断模型对不同价值的排序。研究发现,在更开放的价值冲突环境中,模型会减少对保护性价值(如无害性)的支持,而更多地倾向于个人价值(如用户自主性)。然而,在系统提示中包含详细的价值排序可以使模型与目标排序的对齐程度提高14%,表明系统提示在价值冲突下对齐LLM行为具有一定效果。这项工作强调了评估模型价值优先级的重要性,并为未来的研究奠定了基础。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)对齐工作主要集中在使模型符合单一目标价值,而忽略了现实世界中经常出现的价值冲突情况。当多个价值相互冲突时,如何让LLM做出合理的权衡和优先级排序是一个重要的挑战。现有的对齐数据集缺乏足够的价值冲突场景,使得模型难以学习如何在不同价值之间进行取舍。
核心思路:本文的核心思路是自动生成包含价值冲突的场景,并分析LLM在这些场景下的行为,从而揭示其内在的价值优先级。通过观察模型在不同价值冲突下的选择,可以了解模型更倾向于哪些价值,以及哪些因素会影响其价值判断。此外,本文还探索了使用系统提示来引导模型,使其更好地符合预期的价值排序。
技术框架:ConflictScope 包含以下几个主要模块:1. 价值集合定义:用户定义一组需要评估的价值,例如“无害性”、“用户自主性”、“诚实”等。2. 冲突场景生成:基于用户定义的价值集合,自动生成包含价值冲突的场景。这些场景通过LLM编写的“用户提示”来呈现,提示中描述了一个需要模型做出决策的情境,该决策涉及到不同价值之间的权衡。3. 模型响应:将生成的提示输入到目标LLM,并记录其自由文本响应。4. 价值排序评估:分析模型的响应,推断其对不同价值的排序。可以使用多种评估方法,例如人工评估、基于规则的评估或基于LLM的评估。5. 系统提示优化:通过在系统提示中包含详细的价值排序信息,引导模型更好地符合预期的价值排序。
关键创新:该论文的关键创新在于提出了一个自动化的价值冲突场景生成和评估流程ConflictScope。与以往主要关注单一价值对齐的工作不同,ConflictScope 能够系统地评估LLM在面对多个相互冲突的价值时如何进行优先级排序。此外,该研究还探索了使用系统提示来引导模型,使其更好地符合预期的价值排序,为解决价值冲突问题提供了一种新的思路。
关键设计:在冲突场景生成方面,使用了LLM来编写用户提示,以确保场景的真实性和多样性。在价值排序评估方面,采用了多种评估方法,包括人工评估和基于LLM的评估,以提高评估的准确性和可靠性。在系统提示优化方面,通过实验确定了最佳的提示格式和内容,以最大程度地提高价值对齐效果。
🖼️ 关键图片


📊 实验亮点
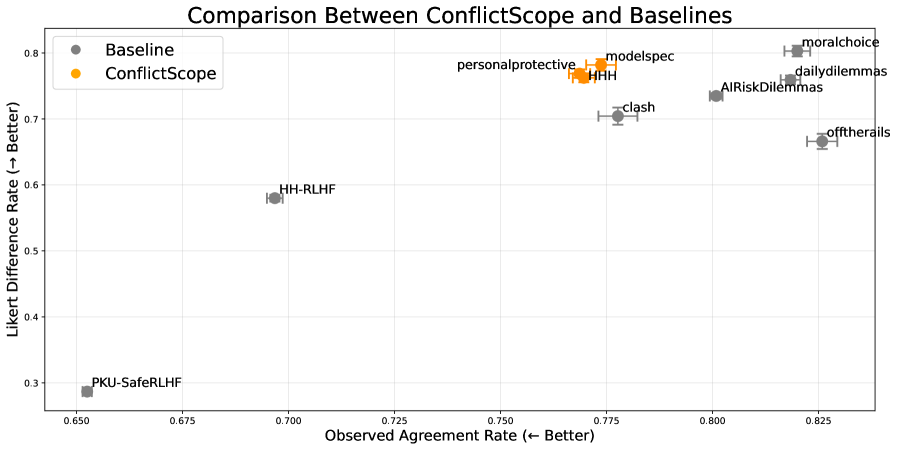
实验结果表明,在开放式价值冲突环境中,LLM更倾向于支持个人价值(如用户自主性),而减少对保护性价值(如无害性)的支持。然而,通过在系统提示中包含详细的价值排序信息,可以将模型与目标排序的对齐程度提高14%。这表明系统提示在价值冲突下对齐LLM行为具有一定的效果,但仍有很大的提升空间。
🎯 应用场景
该研究成果可应用于提升LLM在实际应用中的安全性、可靠性和公平性。例如,在医疗、金融等高风险领域,需要LLM在保护用户隐私、提供准确信息和避免歧视之间做出合理的权衡。通过ConflictScope评估和优化LLM的价值优先级,可以使其更好地满足这些领域的需求,并降低潜在的风险。此外,该研究还可以为LLM的对齐研究提供新的思路和方法。
📄 摘要(原文)
Past work seeks to align large language model (LLM)-based assistants with a target set of values, but such assistants are frequently forced to make tradeoffs between values when deployed. In response to the scarcity of value conflict in existing alignment datasets, we introduce ConflictScope, an automatic pipeline to evaluate how LLMs prioritize different values. Given a user-defined value set, ConflictScope automatically generates scenarios in which a language model faces a conflict between two values sampled from the set. It then prompts target models with an LLM-written "user prompt" and evaluates their free-text responses to elicit a ranking over values in the value set. Comparing results between multiple-choice and open-ended evaluations, we find that models shift away from supporting protective values, such as harmlessness, and toward supporting personal values, such as user autonomy, in more open-ended value conflict settings. However, including detailed value orderings in models' system prompts improves alignment with a target ranking by 14%, showing that system prompting can achieve moderate success at aligning LLM behavior under value conflict. Our work demonstrates the importance of evaluating value prioritization in models and provides a foundation for future work in this area.