From Internal Representations to Text Quality: A Geometric Approach to LLM Evaluation
作者: Viacheslav Yusupov, Danil Maksimov, Ameliia Alaeva, Anna Vasileva, Anna Antipina, Tatyana Zaitseva, Alina Ermilova, Evgeny Burnaev, Egor Shvetsov
分类: cs.CL, cs.AI
发布日期: 2025-09-29
💡 一句话要点
利用LLM内部表征的几何特性评估文本质量,实现无参考文本质量评估
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 文本质量评估 内部表征 几何特性 无参考评估
📋 核心要点
- 现有文本质量评估方法依赖人工标注或参考文本,成本高昂且难以自动化。
- 该论文提出利用LLM内部表征的几何特性(如内在维度和有效秩)作为文本质量的代理指标。
- 实验证明,这些几何指标能够一致地对不同来源的文本进行排序,反映文本的内在质量。
📝 摘要(中文)
本文通过论证内部模型表征的几何特性可以作为生成文本质量的可靠代理,从而将大型语言模型(LLM)的内部和外部分析方法联系起来。我们验证了一系列指标,包括最大可解释方差、有效秩、内在维度、MAUVE分数和Schatten范数,这些指标是在LLM的不同层上测量的。结果表明,内在维度和有效秩可以作为文本自然性和质量的通用评估指标。我们的关键发现揭示了,不同的模型基于这些几何特性对来自各种来源的文本进行一致的排序,表明这些指标反映了固有的文本特征,而不是特定于模型的伪像。这使得无需人工标注数据集的无参考文本质量评估成为可能,为自动化评估流程提供了实际优势。
🔬 方法详解
问题定义:现有文本质量评估方法主要依赖于人工标注的数据集或需要参考文本进行对比,这两种方式都存在明显的局限性。人工标注成本高昂,且主观性较强;而参考文本的获取也并非总是可行,尤其是在生成式任务中。因此,如何实现一种无需参考文本,且能够自动化评估文本质量的方法,是本文要解决的核心问题。
核心思路:本文的核心思路是,文本的质量会在LLM的内部表征中留下痕迹。高质量的文本在LLM内部会产生更具结构化和低维度的表征,而低质量的文本则会产生更加混乱和高维度的表征。因此,可以通过分析LLM内部表征的几何特性,来推断文本的质量。这种方法避免了对人工标注或参考文本的依赖,实现了无参考的文本质量评估。
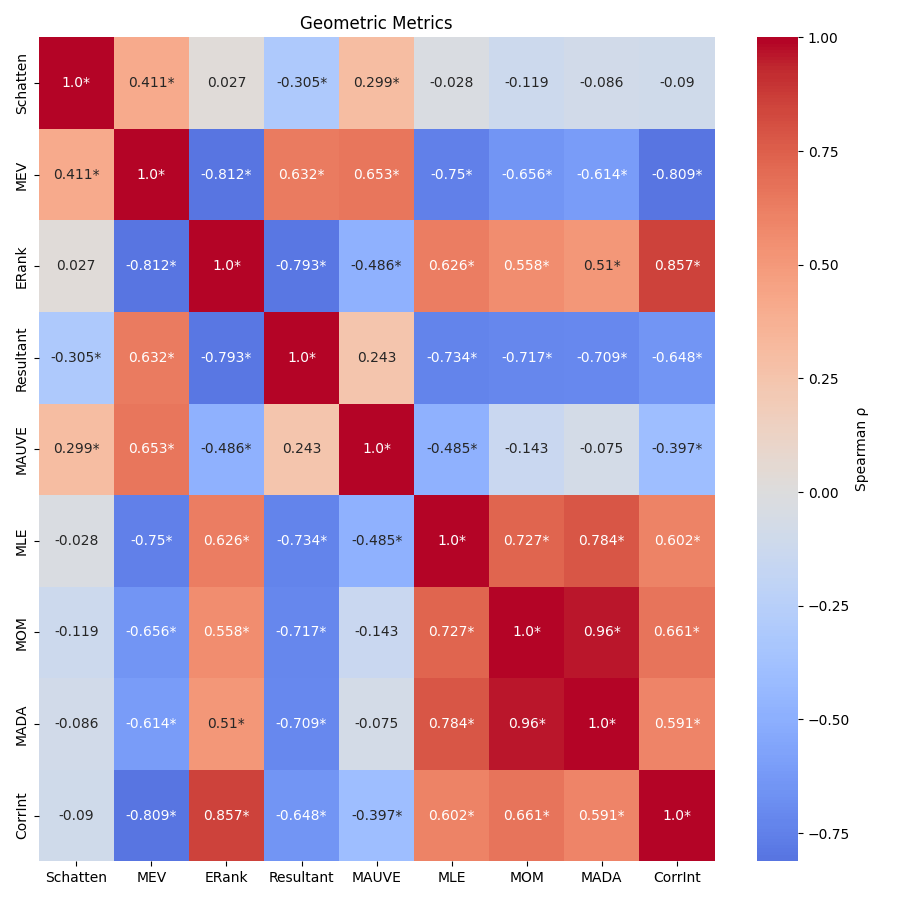
技术框架:该研究的技术框架主要包含以下几个步骤:1) 选择预训练的LLM作为分析对象;2) 将待评估的文本输入LLM,提取不同层的内部表征;3) 计算这些表征的几何特性指标,包括最大可解释方差、有效秩、内在维度、MAUVE分数和Schatten范数;4) 基于这些几何特性指标,对文本的质量进行排序和评估。整体流程无需额外的训练或微调,可以直接应用于各种LLM和文本生成任务。
关键创新:该论文最重要的技术创新在于,它将LLM的内部表征与文本质量联系起来,并证明了内部表征的几何特性可以作为文本质量的有效代理。这种方法摆脱了对人工标注和参考文本的依赖,为文本质量评估提供了一种全新的视角。此外,论文还发现内在维度和有效秩是评估文本自然性和质量的通用指标,这为后续研究提供了重要的指导。
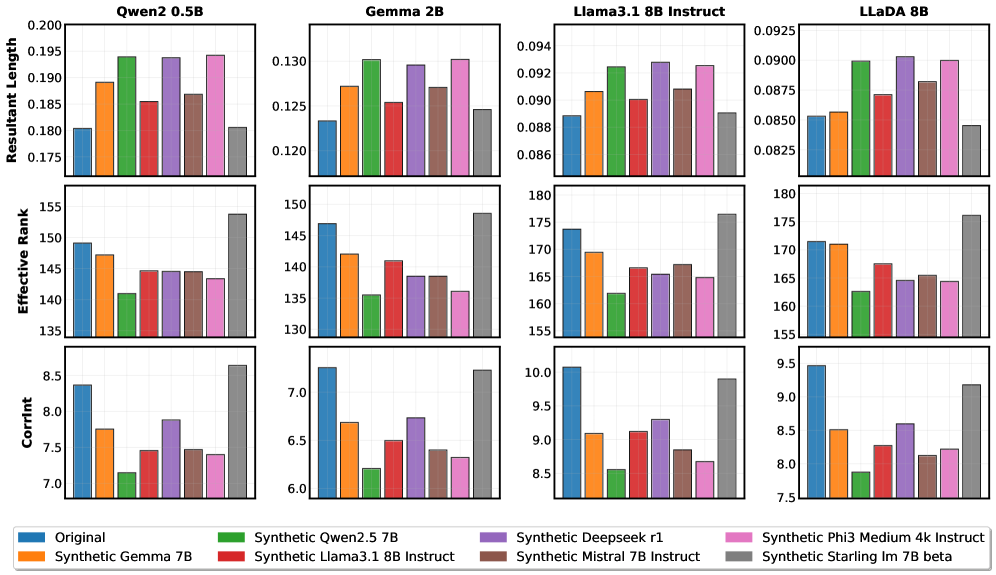
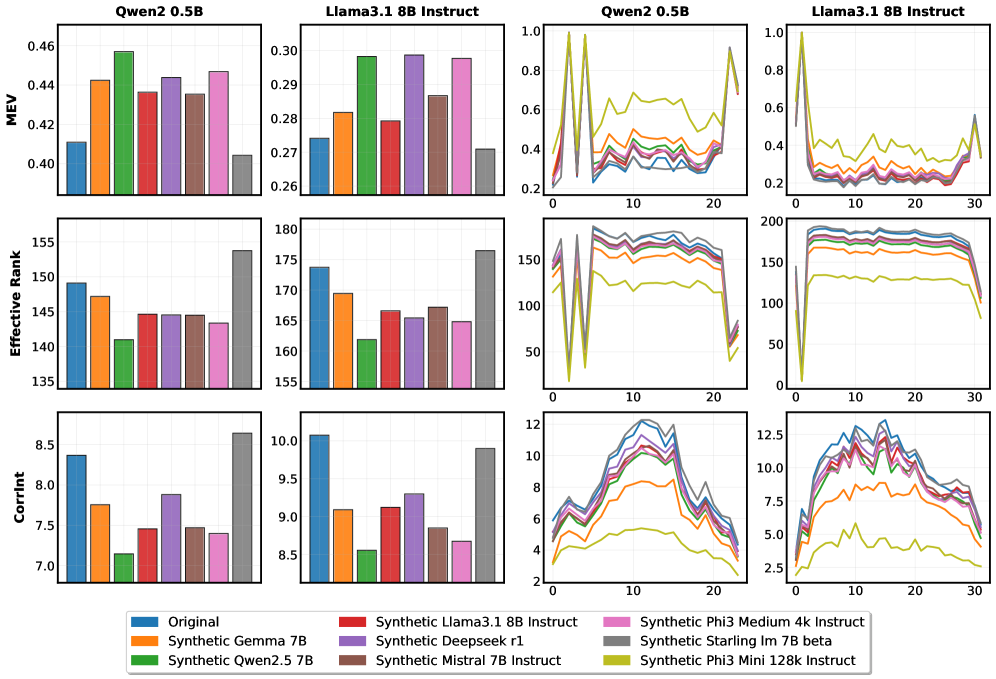
关键设计:在几何特性指标的选择上,论文考虑了多个方面,包括表征的维度、方差、秩等。内在维度用于衡量表征的复杂程度,有效秩用于衡量表征的线性独立性。MAUVE分数用于衡量生成文本与真实文本的分布相似度。Schatten范数用于衡量表征的能量。这些指标的计算都基于标准的线性代数和统计方法,易于实现和应用。论文还对不同层的表征进行了分析,发现某些层的表征对文本质量更敏感。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用内在维度和有效秩等几何指标,可以对不同来源的文本进行一致的排序,且排序结果与人工评估结果高度相关。例如,模型生成的文本的内在维度通常高于人工撰写的文本,这表明模型生成的文本可能存在冗余或不自然之处。此外,该方法在不同LLM上的表现具有一致性,表明这些几何指标反映了文本的内在特性,而非模型特定的伪像。
🎯 应用场景
该研究成果可广泛应用于各种文本生成任务的自动化评估,例如机器翻译、文本摘要、对话生成等。它可以帮助开发者快速评估不同模型的生成质量,优化模型参数,提高生成文本的自然性和流畅性。此外,该方法还可以用于检测恶意文本或低质量内容,维护网络环境的健康。
📄 摘要(原文)
This paper bridges internal and external analysis approaches to large language models (LLMs) by demonstrating that geometric properties of internal model representations serve as reliable proxies for evaluating generated text quality. We validate a set of metrics including Maximum Explainable Variance, Effective Rank, Intrinsic Dimensionality, MAUVE score, and Schatten Norms measured across different layers of LLMs, demonstrating that Intrinsic Dimensionality and Effective Rank can serve as universal assessments of text naturalness and quality. Our key finding reveals that different models consistently rank text from various sources in the same order based on these geometric properties, indicating that these metrics reflect inherent text characteristics rather than model-specific artifacts. This allows a reference-free text quality evaluation that does not require human-annotated datasets, offering practical advantages for automated evaluation pipelines.