Learning to Parallel: Accelerating Diffusion Large Language Models via Learnable Parallel Decoding
作者: Wenrui Bao, Zhiben Chen, Dan Xu, Yuzhang Shang
分类: cs.CL
发布日期: 2025-09-29 (更新: 2025-10-03)
💡 一句话要点
提出Learn2PD以解决大语言模型推理速度瓶颈问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 并行解码 自适应过滤 扩散模型 自然语言处理 推理速度 文本生成 机器学习
📋 核心要点
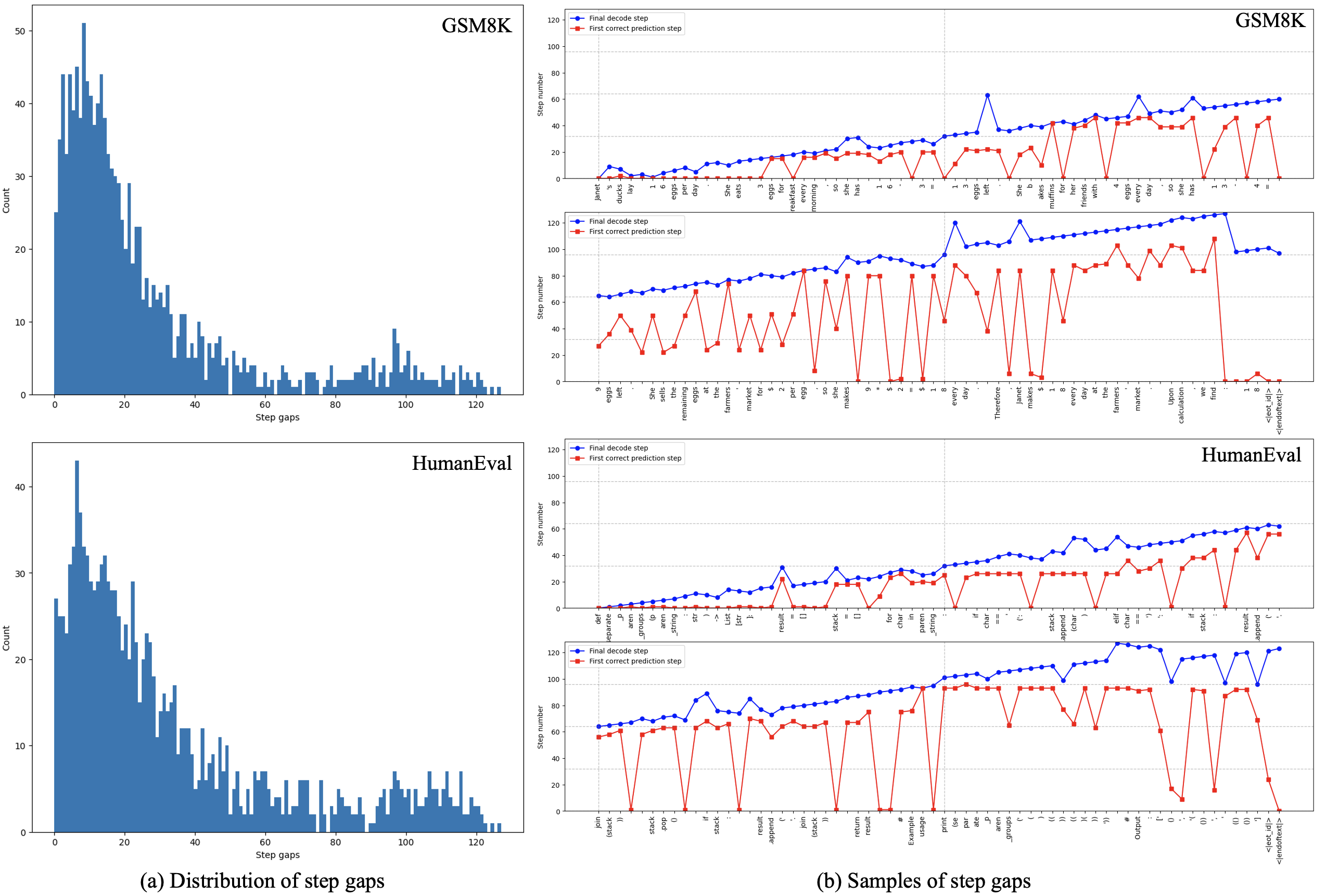
- 现有的大语言模型在自回归解码中需要顺序步骤,导致推理速度受到限制,影响实际应用。
- 本文提出的Learn2PD框架通过训练自适应过滤模型,动态预测令牌的正确性,从而实现更高效的并行解码。
- 实验结果显示,Learn2PD在LLaDA基准上实现了最高22.58倍的速度提升,结合KV-Cache时可达57.51倍,且无性能下降。
📝 摘要(中文)
自回归解码在大型语言模型中需要$ ext{O}(n)$的顺序步骤,这限制了推理吞吐量。近期的扩散基础大型语言模型(dLLMs)通过迭代去噪实现了并行生成。然而,现有的并行解码策略依赖于固定的、与输入无关的启发式方法,未能适应输入特征,导致在不同NLP任务中速度与质量的权衡不理想。本文提出了一种更灵活的并行解码方法,名为学习并行解码(Learn2PD),该框架训练一个轻量级的自适应过滤模型,预测每个令牌位置的当前预测是否与最终输出匹配。该过滤器在后训练阶段学习,优化所需计算量小(分钟级GPU时间)。此外,我们引入了文本结束预测(EoTP)以检测序列结束时的解码完成,避免冗余的填充令牌解码。在LLaDA基准上的实验表明,该方法在不降低性能的情况下实现了最高22.58倍的加速,结合KV-Cache时可达57.51倍。
🔬 方法详解
问题定义:本文旨在解决大型语言模型在自回归解码中存在的速度瓶颈问题。现有方法依赖固定的启发式策略,未能根据输入特征进行动态调整,导致速度与质量的权衡不理想。
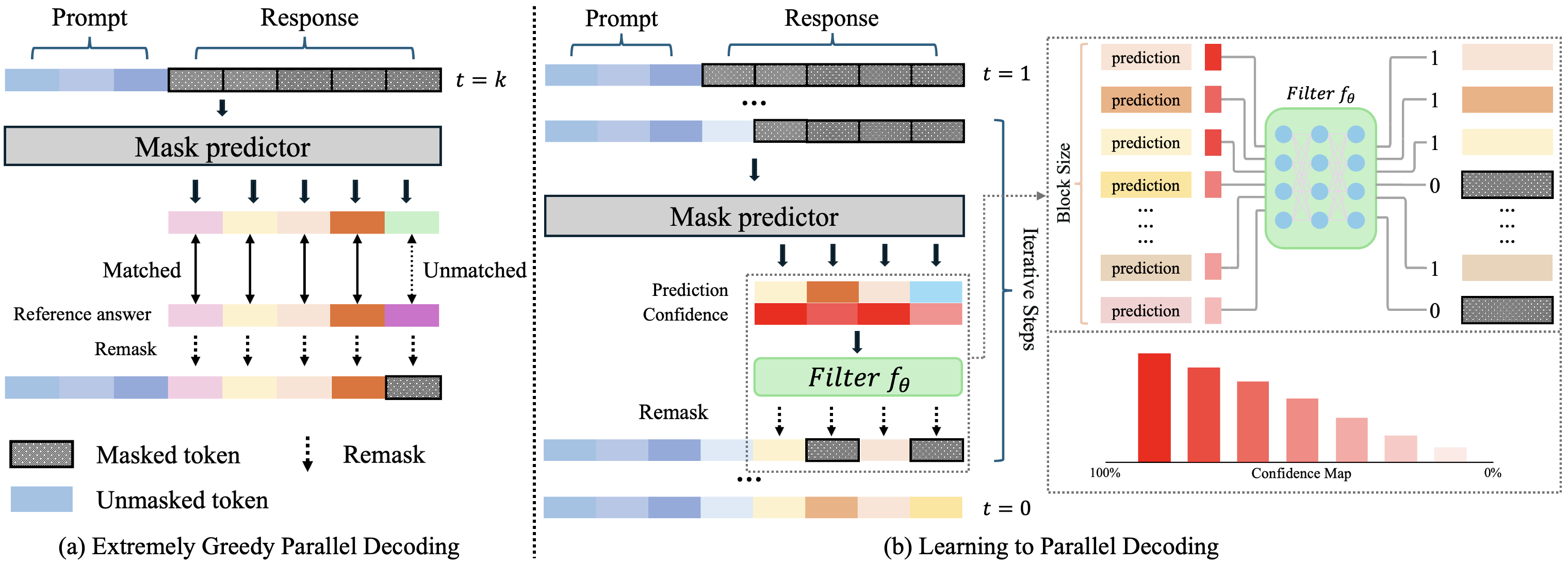
核心思路:论文提出的Learn2PD框架通过训练一个轻量级的自适应过滤模型,来预测每个令牌的当前预测是否与最终输出匹配。这种方法能够动态调整解码过程,提高并行生成的效率。
技术框架:整体架构包括两个主要模块:自适应过滤模型和文本结束预测(EoTP)。自适应过滤模型负责判断令牌的预测准确性,而EoTP用于检测序列的结束,避免冗余解码。
关键创新:最重要的创新点在于引入了后训练学习的自适应过滤模型,能够在解码过程中动态调整,显著提高了并行解码的效率,与传统固定策略相比具有本质区别。
关键设计:在模型设计中,过滤模型的训练只需少量计算资源(分钟级GPU时间),并且通过优化损失函数来提高预测准确性。此外,EoTP的引入有效减少了无效的填充令牌解码。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Learn2PD在LLaDA基准上实现了最高22.58倍的速度提升,且在结合KV-Cache时可达57.51倍,且在此过程中未观察到性能下降,显示出其在实际应用中的巨大潜力。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理中的实时对话系统、文本生成任务以及任何需要高效推理的场景。通过提高解码速度,Learn2PD能够在实际应用中显著提升用户体验,推动大语言模型的广泛应用与发展。
📄 摘要(原文)
Autoregressive decoding in large language models (LLMs) requires $\mathcal{O}(n)$ sequential steps for $n$ tokens, fundamentally limiting inference throughput. Recent diffusion-based LLMs (dLLMs) enable parallel token generation through iterative denoising. However, current parallel decoding strategies rely on fixed, input-agnostic heuristics (e.g., confidence thresholds), which fail to adapt to input-specific characteristics, resulting in suboptimal speed-quality trade-offs across diverse NLP tasks. In this work, we explore a more flexible and dynamic approach to parallel decoding. We propose Learning to Parallel Decode (Learn2PD), a framework that trains a lightweight and adaptive filter model to predict, for each token position, whether the current prediction matches the final output. This learned filter approximates an oracle parallel decoding strategy that unmasks tokens only when correctly predicted. Importantly, the filter model is learned in a post-training manner, requiring only a small amount of computation to optimize it (minute-level GPU time). Additionally, we introduce End-of-Text Prediction (EoTP) to detect decoding completion at the end of sequence, avoiding redundant decoding of padding tokens. Experiments on the LLaDA benchmark demonstrate that our method achieves up to 22.58$\times$ speedup without any performance drop, and up to 57.51$\times$ when combined with KV-Cache.