Pretraining Large Language Models with NVFP4
作者: NVIDIA, Felix Abecassis, Anjulie Agrusa, Dong Ahn, Jonah Alben, Stefania Alborghetti, Michael Andersch, Sivakumar Arayandi, Alexis Bjorlin, Aaron Blakeman, Evan Briones, Ian Buck, Bryan Catanzaro, Jinhang Choi, Mike Chrzanowski, Eric Chung, Victor Cui, Steve Dai, Bita Darvish Rouhani, Carlo del Mundo, Deena Donia, Burc Eryilmaz, Henry Estela, Abhinav Goel, Oleg Goncharov, Yugi Guvvala, Robert Hesse, Russell Hewett, Herbert Hum, Ujval Kapasi, Brucek Khailany, Mikail Khona, Nick Knight, Alex Kondratenko, Ronny Krashinsky, Ben Lanir, Simon Layton, Michael Lightstone, Daniel Lo, Paulius Micikevicius, Asit Mishra, Tim Moon, Deepak Narayanan, Chao Ni, Abhijit Paithankar, Satish Pasumarthi, Ankit Patel, Mostofa Patwary, Ashwin Poojary, Gargi Prasad, Sweta Priyadarshi, Yigong Qin, Xiaowei Ren, Oleg Rybakov, Charbel Sakr, Sanjeev Satheesh, Stas Sergienko, Pasha Shamis, Kirthi Shankar, Nishant Sharma, Mohammad Shoeybi, Michael Siu, Misha Smelyanskiy, Darko Stosic, Dusan Stosic, Bor-Yiing Su, Frank Sun, Nima Tajbakhsh, Shelby Thomas, Przemek Tredak, Evgeny Tsykunov, Gandhi Vaithilingam, Aditya Vavre, Rangharajan Venkatesan, Roger Waleffe, Qiyu Wan, Hexin Wang, Mengdi Wang, Lizzie Wei, Hao Wu, Evan Wu, Keith Wyss, Ning Xu, Jinze Xue, Charlene Yang, Yujia Zhai, Ruoxi Zhang, Jingyang Zhu, Zhongbo Zhu
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-09-29
💡 一句话要点
提出NVFP4训练方法,实现4比特精度下大语言模型的稳定高效预训练。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 预训练 低精度训练 FP4 量化 随机哈达玛变换 梯度估计
📋 核心要点
- 当前大语言模型训练需要巨大的算力投入,提高预训练效率至关重要,而降低精度到4比特浮点(FP4)具有潜力。
- 论文提出NVFP4训练方法,通过随机哈达玛变换限制异常值,二维量化保证一致性,随机舍入实现无偏估计,并选择性使用高精度层。
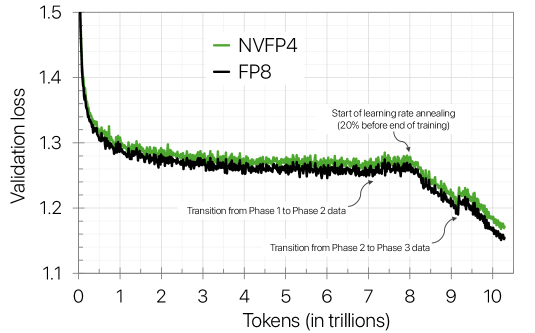
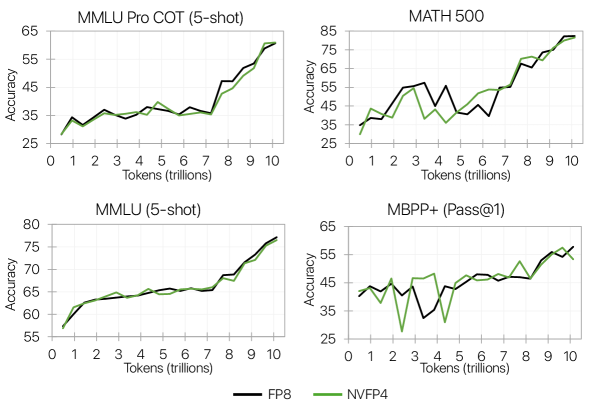
- 实验结果表明,使用NVFP4训练的120亿参数模型在训练损失和下游任务精度上与FP8基线相当,证明了该方法的有效性。
📝 摘要(中文)
本文提出了一种使用NVFP4格式进行大语言模型(LLM)稳定且精确训练的新方法。该方法集成了随机哈达玛变换(RHT)以限制块级异常值,采用二维量化方案以确保前向和后向传播的一致表示,利用随机舍入进行无偏梯度估计,并结合选择性的高精度层。通过在10万亿tokens上训练一个120亿参数的模型验证了该方法,这是迄今为止公开记录的最长的4比特精度训练。结果表明,使用基于NVFP4的预训练技术训练的模型,其训练损失和下游任务精度与FP8基线相当。这些发现表明,NVFP4与本文提出的训练方法相结合,代表了窄精度LLM训练算法的一个重大进步。
🔬 方法详解
问题定义:论文旨在解决在4比特浮点(FP4)精度下训练大型语言模型时遇到的训练不稳定、收敛困难以及实现复杂等问题。现有的FP8训练虽然被广泛采用,但进一步降低精度到FP4可以显著提升计算速度和资源利用率,然而,极低的精度给训练带来了挑战,尤其是在大规模模型和长序列训练中。
核心思路:论文的核心思路是通过一系列技术手段来缓解FP4精度带来的负面影响,从而实现稳定且高效的训练。具体来说,通过限制异常值、保证前后向传播一致性、减少梯度偏差等方式,使得模型能够在极低精度下也能有效学习。这种设计旨在充分利用FP4的计算优势,同时避免其带来的精度损失。
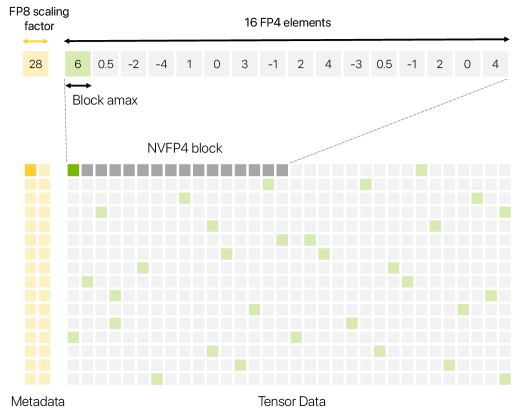
技术框架:整体框架包括以下几个关键模块:1) NVFP4格式:使用一种特定的4比特浮点格式。2) 随机哈达玛变换(RHT):用于限制块级异常值,防止梯度爆炸。3) 二维量化方案:确保前向和后向传播过程中表示的一致性。4) 随机舍入:用于无偏梯度估计,减少量化误差。5) 选择性高精度层:在对精度要求高的层使用更高精度,以保证整体训练的稳定性。
关键创新:论文最重要的技术创新在于将随机哈达玛变换、二维量化和随机舍入等多种技术巧妙地结合起来,共同作用于FP4训练,从而克服了低精度带来的挑战。与现有方法相比,该方法不是简单地将FP8训练方法移植到FP4,而是针对FP4的特性进行了专门的设计和优化。
关键设计:1) 随机哈达玛变换的块大小:需要根据模型的规模和数据分布进行调整。2) 二维量化的具体量化策略:包括如何选择量化范围和量化步长。3) 随机舍入的概率分布:需要保证梯度估计的无偏性。4) 选择性高精度层的选择标准:例如,可以根据层的梯度幅度或敏感度来选择。
🖼️ 关键图片
📊 实验亮点
论文通过实验验证了NVFP4训练方法的有效性,在10万亿tokens上训练了一个120亿参数的模型,并在训练损失和下游任务精度上达到了与FP8基线相当的水平。这是目前公开报道的最长4比特精度训练,证明了该方法在大规模模型和长序列训练中的可行性。
🎯 应用场景
该研究成果可广泛应用于大语言模型的预训练领域,尤其是在资源受限的环境下,例如边缘设备或低功耗服务器。通过使用NVFP4训练方法,可以降低训练成本,加速模型迭代,并推动更大规模、更强大语言模型的发展。此外,该技术也有潜力应用于其他深度学习模型的训练,提高整体的计算效率。
📄 摘要(原文)
Large Language Models (LLMs) today are powerful problem solvers across many domains, and they continue to get stronger as they scale in model size, training set size, and training set quality, as shown by extensive research and experimentation across the industry. Training a frontier model today requires on the order of tens to hundreds of yottaflops, which is a massive investment of time, compute, and energy. Improving pretraining efficiency is therefore essential to enable the next generation of even more capable LLMs. While 8-bit floating point (FP8) training is now widely adopted, transitioning to even narrower precision, such as 4-bit floating point (FP4), could unlock additional improvements in computational speed and resource utilization. However, quantization at this level poses challenges to training stability, convergence, and implementation, notably for large-scale models trained on long token horizons. In this study, we introduce a novel approach for stable and accurate training of large language models (LLMs) using the NVFP4 format. Our method integrates Random Hadamard transforms (RHT) to bound block-level outliers, employs a two-dimensional quantization scheme for consistent representations across both the forward and backward passes, utilizes stochastic rounding for unbiased gradient estimation, and incorporates selective high-precision layers. We validate our approach by training a 12-billion-parameter model on 10 trillion tokens -- the longest publicly documented training run in 4-bit precision to date. Our results show that the model trained with our NVFP4-based pretraining technique achieves training loss and downstream task accuracies comparable to an FP8 baseline. These findings highlight that NVFP4, when combined with our training approach, represents a major step forward in narrow-precision LLM training algorithms.