Learning from Convenience Samples: A Case Study on Fine-Tuning LLMs for Survey Non-response in the German Longitudinal Election Study
作者: Tobias Holtdirk, Dennis Assenmacher, Arnim Bleier, Claudia Wagner
分类: cs.CY, cs.CL
发布日期: 2025-09-29
💡 一句话要点
利用便利样本微调LLM,解决德国选举研究中调查无应答问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 微调 调查无应答 便利样本 选举研究
📋 核心要点
- 传统调查研究面临概率样本成本高昂和数据缺失的挑战,影响推断的准确性。
- 该研究利用部分调查回复,通过微调LLM来填补缺失的投票选择数据,探索更实用的解决方案。
- 实验表明,微调后的LLM在数据随机缺失时与表格分类器性能相当,在存在偏差的便利样本下优于零样本方法和表格方法。
📝 摘要(中文)
调查研究人员面临两大挑战:概率样本成本上升和数据缺失(例如,无应答或衰减),这会损害推断并增加便利样本的使用。最近的研究探索了使用大型语言模型(LLM)通过基于角色的提示来模拟受访者,通常无需标记数据。我们研究了一个更实际的场景,即存在部分调查回复:我们使用德国纵向选举研究,在可用数据上微调LLM,以在随机和系统性无应答情况下推算自我报告的投票选择。我们将零样本提示和监督微调与表格分类器(例如,CatBoost)进行比较,并测试用于微调的不同便利样本(例如,学生)如何影响泛化。
🔬 方法详解
问题定义:该论文旨在解决调查研究中因无应答造成的投票选择数据缺失问题。现有方法,如传统的统计插补方法,可能无法有效处理复杂的非随机缺失模式,并且依赖于完整的概率样本,成本较高。零样本LLM方法虽然无需标注数据,但在实际应用中效果有限。
核心思路:论文的核心思路是利用已有的部分调查回复数据,通过监督微调的方式,使LLM学习到受访者的投票选择模式,从而能够更准确地推断缺失的投票选择数据。这种方法旨在利用LLM的强大语言建模能力,同时克服零样本方法的局限性。
技术框架:整体框架包括数据预处理、模型选择与微调、以及性能评估三个主要阶段。首先,对德国纵向选举研究的数据进行清洗和整理,构建用于微调的数据集。然后,选择合适的LLM(例如,3B到8B的开源模型)进行微调,使用已有的调查回复作为训练数据。最后,通过与零样本方法和表格分类器(如CatBoost)进行比较,评估微调后LLM的性能。
关键创新:该论文的关键创新在于探索了利用便利样本微调LLM来解决调查无应答问题。与以往研究不同,该研究关注的是存在部分调查回复的实际场景,并验证了微调LLM在处理非随机缺失数据方面的有效性。此外,该研究还考察了不同类型的便利样本对模型泛化能力的影响。
关键设计:论文的关键设计包括:1) 选择合适的LLM架构和规模(3B-8B参数);2) 设计合适的微调策略,例如,使用交叉熵损失函数优化模型参数;3) 评估不同便利样本(例如,学生)对模型泛化能力的影响;4) 采用合适的评估指标,例如,个体层面的预测准确率和群体层面的分布还原度。
🖼️ 关键图片
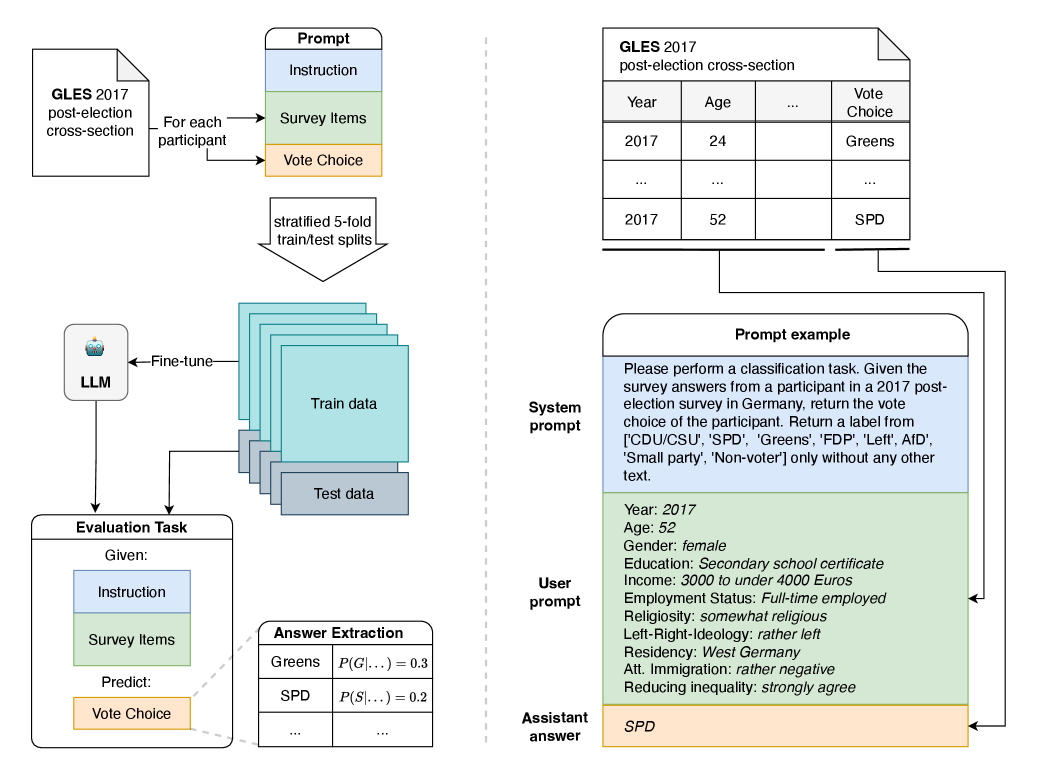


📊 实验亮点
实验结果表明,在数据完全随机缺失的情况下,微调后的LLM与表格分类器性能相当,优于零样本方法。在存在偏差的便利样本下,微调后的LLM在个体层面预测和群体层面分布还原方面均优于零样本方法,并且通常优于表格方法。这表明微调LLM是处理非概率样本或系统性缺失数据的有效策略。
🎯 应用场景
该研究成果可应用于社会科学、政治学、市场调查等领域,帮助研究人员利用非概率样本或存在系统性缺失的数据进行更准确的推断。通过微调LLM,可以降低调查成本,提高数据利用率,并为新型调查设计提供可能性,例如仅需易于访问的子群体。
📄 摘要(原文)
Survey researchers face two key challenges: the rising costs of probability samples and missing data (e.g., non-response or attrition), which can undermine inference and increase the use of convenience samples. Recent work explores using large language models (LLMs) to simulate respondents via persona-based prompts, often without labeled data. We study a more practical setting where partial survey responses exist: we fine-tune LLMs on available data to impute self-reported vote choice under both random and systematic nonresponse, using the German Longitudinal Election Study. We compare zero-shot prompting and supervised fine-tuning against tabular classifiers (e.g., CatBoost) and test how different convenience samples (e.g., students) used for fine-tuning affect generalization. Our results show that when data are missing completely at random, fine-tuned LLMs match tabular classifiers but outperform zero-shot approaches. When only biased convenience samples are available, fine-tuning small (3B to 8B) open-source LLMs can recover both individual-level predictions and population-level distributions more accurately than zero-shot and often better than tabular methods. This suggests fine-tuned LLMs offer a promising strategy for researchers working with non-probability samples or systematic missingness, and may enable new survey designs requiring only easily accessible subpopulations.