SeaPO: Strategic Error Amplification for Robust Preference Optimization of Large Language Models
作者: Jun Rao, Yunjie Liao, Xuebo Liu, Zepeng Lin, Lian Lian, Dong Jin, Shengjun Cheng, Jun Yu, Min Zhang
分类: cs.CL
发布日期: 2025-09-29
备注: EMNLP 2025 Findings
💡 一句话要点
SeaPO:通过策略性误差放大增强大语言模型偏好优化的鲁棒性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 偏好优化 误差放大 鲁棒性 真实性 对比学习 策略性学习
📋 核心要点
- 现有偏好优化方法在正负样本质量趋同的情况下,难以有效提升大语言模型性能。
- SeaPO通过策略性地放大模型中常见的误差类型,确保负样本包含更多误差,从而改善偏好学习。
- 实验表明,SeaPO显著提升了模型在多个能力维度上的性能,尤其是在真实性方面有显著提升。
📝 摘要(中文)
本文提出了一种名为SeaPO的策略性误差放大方法,旨在提升大语言模型(LLMs)偏好优化的效果。现有方法依赖正负样本对来增强模型性能,但由于模型容量限制,正负样本质量可能趋同,导致偏好学习优化困难。SeaPO利用LLMs中常见的三种误差类型,将特定误差模式引入模型偏好优化中,确保负样本比正样本包含更多误差。通过基于偏好的训练来减轻这些误差的发生,从而提高模型性能。在五个能力维度和不同模型规模(1.5B到14B)上的评估表明,生成的数据显著提高了整体模型性能,尤其是在真实性方面,观察到5-10个百分点的提升。进一步分析表明,任务性能随引入的误差类型而变化。注入最常见的误差类型可以提高相关任务的性能,而混合误差类型可以带来更广泛的性能提升:大多数任务表现出稳定的改进,而少数任务表现出显著的提升。
🔬 方法详解
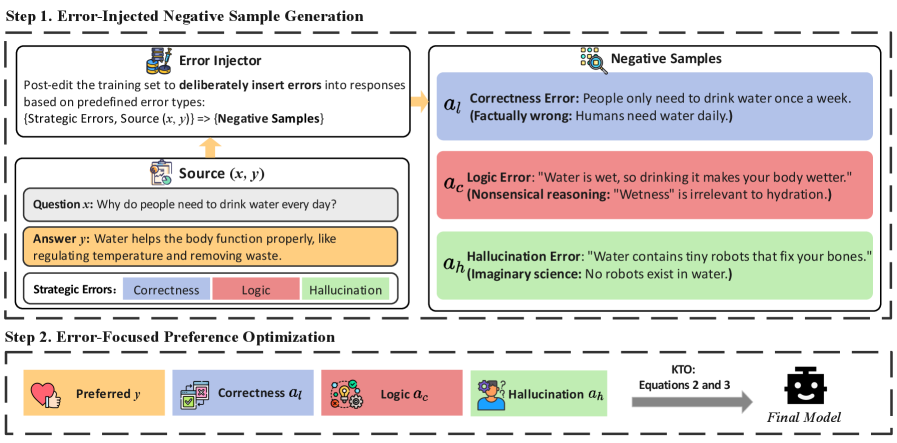
问题定义:现有大语言模型的偏好优化方法依赖于正负样本对,但由于模型容量的限制,经过训练后,正负样本的质量可能变得相似,导致模型难以区分优劣,从而影响偏好学习的效果。因此,如何有效区分正负样本,提升偏好学习的鲁棒性,是本文要解决的核心问题。
核心思路:SeaPO的核心思路是通过策略性地放大负样本中的误差,使得负样本与正样本之间的差异更加明显,从而更容易进行偏好学习。具体来说,SeaPO利用大语言模型中常见的误差类型,并将这些误差注入到负样本中,使得负样本包含更多、更明显的错误。
技术框架:SeaPO方法主要包含以下几个阶段:1) 确定大语言模型中常见的误差类型;2) 设计策略,将这些误差注入到负样本中,生成带有特定误差模式的负样本;3) 使用带有误差放大的正负样本对,进行基于偏好的训练,优化模型参数,使其能够更好地识别和避免这些误差。
关键创新:SeaPO的关键创新在于提出了策略性误差放大的思想,通过人为地增加负样本的误差,使得偏好学习更加有效。与传统的偏好优化方法相比,SeaPO不是简单地依赖于原始的正负样本,而是主动地创造更具区分度的训练数据,从而提升模型的学习效果。
关键设计:SeaPO的关键设计包括:1) 误差类型的选择:选择大语言模型中最常见的、对下游任务影响较大的误差类型,例如事实性错误、逻辑错误等;2) 误差注入策略:设计合理的策略,将误差注入到负样本中,例如通过修改句子中的关键词、改变逻辑关系等;3) 偏好学习目标:使用合适的偏好学习目标函数,例如pairwise ranking loss,来优化模型参数,使其能够更好地区分正负样本。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SeaPO方法在多个能力维度上显著提升了大语言模型的性能,尤其是在真实性方面,提升幅度达到5-10个百分点。此外,实验还发现,不同类型的误差对任务性能的影响不同,注入最常见的误差类型可以提高相关任务的性能,而混合误差类型可以带来更广泛的性能提升。
🎯 应用场景
SeaPO方法可应用于各种需要偏好优化的大语言模型任务,例如对话生成、文本摘要、代码生成等。通过提升模型的鲁棒性和真实性,SeaPO可以帮助构建更可靠、更实用的AI系统。未来,该方法还可以扩展到其他类型的模型和任务中,例如图像生成、语音识别等。
📄 摘要(原文)
Existing alignment methods for preference optimization of large language models (LLMs) aim to enhance model performance by utilizing pairs of positive and negative samples. However, due to the limited capacity of models in scoring or generating responses, the quality of positive and negative samples may become similar during training, which complicates optimization for preference learning. To address this issue, we introduce SeaPO, a Strategic Error Amplification method that leverages three error types commonly occurring in LLMs to introduce specific error patterns into the model Preference Optimization. This strategy ensures that negative samples are more erroneous than positive samples and preference-based training is employed to mitigate the occurrence of these errors, thereby enhancing model performance. Evaluations across five capability dimensions and different model scales (1.5B to 14B) demonstrate that the generated data significantly improved overall model performance, particularly in terms of truthfulness, with improvements of 5-10 percentage points observed. Further analysis reveals that task performance varies depending on the error types introduced. Injecting the most common error types improves performance in related tasks, while a mix of error types leads to a broader performance enhancement: most tasks show stable improvements, while a few tasks exhibit significant gains.