ProxyAttn: Guided Sparse Attention via Representative Heads
作者: Yixuan Wang, Huang He, Siqi Bao, Hua Wu, Haifeng Wang, Qingfu Zhu, Wanxiang Che
分类: cs.CL, cs.LG
发布日期: 2025-09-29
备注: 14pages, 5figures
🔗 代码/项目: GITHUB
💡 一句话要点
ProxyAttn:通过代表性注意力头引导的稀疏注意力机制,加速长文本处理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 稀疏注意力 长文本处理 大型语言模型 注意力机制加速 代表性注意力头 动态预算估计
📋 核心要点
- 现有块稀疏注意力方法在长文本处理中,由于粗粒度的块重要性估计,导致高稀疏率下性能下降。
- ProxyAttn通过压缩注意力头维度,利用代表性注意力头的池化分数近似所有头的分数,实现更精确的块估计。
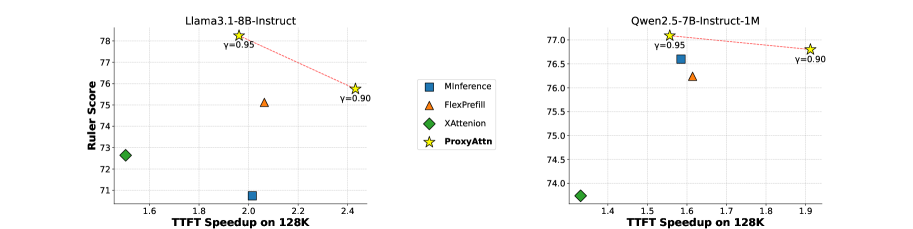
- 实验表明,ProxyAttn在多种模型和基准测试中,显著提升了性能和效率,实现了高达10.3倍的注意力加速。
📝 摘要(中文)
注意力机制的二次复杂度限制了大型语言模型(LLM)在长文本任务上的效率。最近,动态估计块重要性的方法实现了高效的块稀疏注意力,从而显著加速了LLM的长文本预填充。然而,它们粗粒度的估计不可避免地导致在高稀疏率下的性能下降。本文提出ProxyAttn,一种无需训练的稀疏注意力算法,通过压缩注意力头的维度来实现更精确的块估计。基于对多个注意力头之间相似性的观察,我们使用池化的代表性注意力头的分数来近似所有头的分数。为了解决头之间不同的稀疏性,我们还提出了一种块感知的动态预算估计方法。通过将来自代表性代理头的分数与多头动态预算相结合,我们以较低的计算成本实现了更细粒度的块重要性评估。在各种主流模型和广泛基准上的实验证实了注意力头之间潜在的相似性。利用细粒度的估计,所提出的方法与现有方法相比,在性能和效率方面都取得了显著的提升。更准确地说,ProxyAttn可以在不显著损失性能的情况下,实现高达10.3倍的注意力加速和2.4倍的预填充加速。
🔬 方法详解
问题定义:现有的大型语言模型在处理长文本时,注意力机制的计算复杂度呈二次方增长,成为性能瓶颈。现有的块稀疏注意力方法虽然能加速计算,但由于其粗粒度的块重要性评估,在高稀疏率下会造成显著的性能损失。
核心思路:论文的核心思路是利用多个注意力头之间的相似性,通过少量“代表性”的注意力头(Proxy Heads)来近似所有注意力头的计算结果。这样可以在保证精度的前提下,大幅减少计算量,从而加速长文本处理。
技术框架:ProxyAttn算法主要包含以下几个阶段:1. 代表性注意力头选择:选择部分注意力头作为代表,用于后续的计算。2. 注意力分数计算:仅计算代表性注意力头的注意力分数。3. 分数池化:对代表性注意力头的分数进行池化操作,得到一个综合的分数,用于近似所有注意力头的分数。4. 块重要性评估:基于近似的注意力分数,评估每个块的重要性。5. 稀疏注意力计算:仅对重要的块进行注意力计算。6. 块感知的动态预算估计:根据每个块的实际情况,动态调整计算预算。
关键创新:ProxyAttn的关键创新在于利用注意力头之间的相似性,通过少量代表性注意力头来近似所有注意力头的计算结果,从而实现更细粒度的块重要性评估。与现有方法相比,ProxyAttn无需训练,且能更精确地评估块的重要性,从而在高稀疏率下也能保持较高的性能。
关键设计:在代表性注意力头选择方面,论文可能采用了随机选择或基于某种指标(如方差)的选择方法。池化操作可能采用了平均池化或最大池化。块感知的动态预算估计方法可能基于块的注意力分数或梯度信息来动态调整计算预算。具体的参数设置和网络结构细节需要在论文原文中查找。
🖼️ 关键图片


📊 实验亮点
实验结果表明,ProxyAttn在多种主流模型和基准测试中都取得了显著的性能提升。例如,在不显著损失性能的情况下,ProxyAttn可以实现高达10.3倍的注意力加速和2.4倍的预填充加速。这些结果验证了ProxyAttn的有效性和优越性。
🎯 应用场景
ProxyAttn可应用于各种需要处理长文本的场景,例如长文档摘要、机器翻译、问答系统、代码生成等。通过加速注意力计算,ProxyAttn能够提升大型语言模型在这些任务上的效率和性能,降低计算成本,并使得在资源受限的设备上部署大型语言模型成为可能。
📄 摘要(原文)
The quadratic complexity of attention mechanisms limits the efficiency of Large Language Models (LLMs) on long-text tasks. Recently, methods that dynamically estimate block importance have enabled efficient block sparse attention, leading to significant acceleration in long-text pre-filling of LLMs. However, their coarse-grained estimation inevitably leads to performance degradation at high sparsity rates. In this work, we propose ProxyAttn, a training-free sparse attention algorithm that achieves more precise block estimation by compressing the dimension of attention heads. Based on our observation of the similarity among multiple attention heads, we use the scores of pooled representative heads to approximate the scores for all heads. To account for the varying sparsity among heads, we also propose a block-aware dynamic budget estimation method. By combining the scores from representative proxy heads with multi-head dynamic budgets, we achieve a more fine-grained block importance evaluation at low computational cost. Experiments on a variety of mainstream models and extensive benchmarks confirm the underlying similarity among attention heads. Leveraging a fine-grained estimation, the proposed method achieves substantial gains in performance and efficiency compared to existing methods. More precisely, ProxyAttn can achieve up to 10.3x attention acceleration and 2.4x prefilling acceleration without significant performance loss. Our code is available at https://github.com/wyxstriker/ProxyAttn.