InfLLM-V2: Dense-Sparse Switchable Attention for Seamless Short-to-Long Adaptation
作者: Weilin Zhao, Zihan Zhou, Zhou Su, Chaojun Xiao, Yuxuan Li, Yanghao Li, Yudi Zhang, Weilun Zhao, Zhen Li, Yuxiang Huang, Ao Sun, Xu Han, Zhiyuan Liu
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-09-29
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
提出InfLLM-V2:一种稠密-稀疏可切换注意力机制,实现模型从短序列到长序列的无缝适应。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长序列处理 稀疏注意力 稠密注意力 Transformer 语言模型 长文本理解 思维链推理
📋 核心要点
- 现有稀疏注意力方法参数量大,破坏了“短预训练,长微调”流程,导致收敛慢、难加速。
- InfLLM-V2通过无参数架构修改重用稠密注意力参数,保持短长序列处理一致性,实现平滑过渡。
- 实验表明,InfLLM-V2比稠密注意力快4倍,同时在长上下文理解和思维链推理上保持了高性能。
📝 摘要(中文)
现代大型语言模型对长序列处理能力至关重要。然而,标准Transformer架构中的自注意力机制在处理长序列时面临严重的计算和内存瓶颈。可训练的稀疏注意力方法提供了一种有前景的解决方案,但现有方法(如NSA)引入了过多的额外参数,并破坏了传统的“短序列预训练,长序列微调”工作流程,导致收敛缓慢且难以加速。为了克服这些限制,我们引入了一种稠密-稀疏可切换注意力框架,称为InfLLM-V2。InfLLM-V2是一种可训练的稀疏注意力机制,可将模型从短序列无缝地适应到长序列。具体来说,InfLLM-V2通过无参数的架构修改重用稠密注意力参数,从而保持短序列和长序列处理之间的一致性。此外,InfLLM-V2通过对短输入使用稠密注意力,并平滑过渡到对长序列使用稀疏注意力,确保了所有序列长度上的计算效率。为了实现实际加速,我们进一步引入了InfLLM-V2的高效实现,从而显著降低了计算开销。我们在长上下文理解和思维链推理方面的实验表明,InfLLM-V2比稠密注意力快4倍,同时分别保留了98.1%和99.7%的性能。基于InfLLM-V2框架,我们训练并开源了MiniCPM4.1,这是一个混合推理模型,为研究社区提供了可复现的实现。
🔬 方法详解
问题定义:现有的大型语言模型在处理长序列时,标准Transformer的自注意力机制面临计算和内存瓶颈。可训练的稀疏注意力方法虽然有潜力,但如NSA等方法引入了过多的额外参数,破坏了传统的“短序列预训练,长序列微调”流程,导致收敛速度慢,难以加速,并且增加了部署成本。
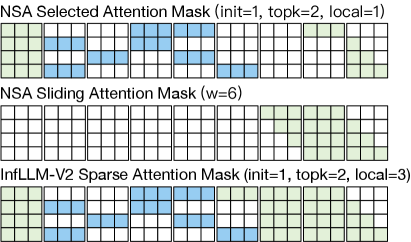
核心思路:InfLLM-V2的核心思路是设计一种稠密-稀疏可切换的注意力机制,使得模型能够无缝地从短序列处理过渡到长序列处理。通过重用稠密注意力机制的参数,并引入稀疏注意力机制来处理长序列,从而在保证性能的同时,降低计算和内存开销。这种设计旨在保持短序列和长序列处理的一致性,避免额外的参数引入,并实现高效的加速。
技术框架:InfLLM-V2框架主要包含以下几个关键部分:首先,它利用现有的稠密注意力机制的参数,避免引入额外的参数。其次,引入稀疏注意力机制,用于处理长序列,降低计算复杂度。第三,设计了一种平滑过渡机制,使得模型能够根据输入序列的长度,自动选择使用稠密注意力或稀疏注意力。整体流程是,对于短序列,使用稠密注意力进行处理;随着序列长度的增加,逐渐过渡到使用稀疏注意力进行处理。
关键创新:InfLLM-V2最重要的技术创新点在于其稠密-稀疏可切换的注意力机制。与现有方法相比,InfLLM-V2避免了引入额外的参数,而是通过重用稠密注意力机制的参数,并引入稀疏注意力机制来实现长序列处理。这种设计不仅降低了计算和内存开销,还保持了短序列和长序列处理的一致性,从而避免了额外的训练和微调。
关键设计:InfLLM-V2的关键设计包括:1) 参数重用机制,即重用稠密注意力机制的参数,避免引入额外的参数。2) 稀疏注意力机制的选择,需要根据具体的任务和数据集进行选择,以达到最佳的性能和效率。3) 平滑过渡机制的设计,需要保证模型能够平滑地从稠密注意力过渡到稀疏注意力,避免性能下降。4) 高效的实现方式,需要考虑如何降低计算开销,提高计算效率。具体的参数设置、损失函数和网络结构等技术细节需要根据具体的任务和数据集进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,InfLLM-V2在长上下文理解和思维链推理任务上表现出色。与稠密注意力相比,InfLLM-V2实现了4倍的加速,同时分别保留了98.1%和99.7%的性能。此外,作者还基于InfLLM-V2框架训练并开源了MiniCPM4.1,为研究社区提供了可复现的实现。
🎯 应用场景
InfLLM-V2适用于需要处理长序列的各种自然语言处理任务,例如长文本摘要、机器翻译、对话生成、代码生成等。该方法能够有效降低计算和内存开销,提高处理长序列的效率,具有广泛的应用前景。此外,该方法还可以应用于其他领域,例如语音识别、视频分析等,只要这些领域需要处理长序列数据。
📄 摘要(原文)
Long-sequence processing is a critical capability for modern large language models. However, the self-attention mechanism in the standard Transformer architecture faces severe computational and memory bottlenecks when processing long sequences. While trainable sparse attention methods offer a promising solution, existing approaches such as NSA introduce excessive extra parameters and disrupt the conventional \textit{pretrain-on-short, finetune-on-long} workflow, resulting in slow convergence and difficulty in acceleration. To overcome these limitations, we introduce dense-sparse switchable attention framework, termed as InfLLM-V2. InfLLM-V2 is a trainable sparse attention that seamlessly adapts models from short to long sequences. Specifically, InfLLM-V2 reuses dense attention parameters through parameter-free architecture modification, maintaining consistency between short and long sequence processing. Additionally, InfLLM-V2 ensures computational efficiency across all sequence lengths, by using dense attention for short inputs and smoothly transitioning to sparse attention for long sequences. To achieve practical acceleration, we further introduce an efficient implementation of InfLLM-V2 that significantly reduces the computational overhead. Our experiments on long-context understanding and chain-of-thought reasoning demonstrate that InfLLM-V2 is 4$\times$ faster than dense attention while retaining 98.1% and 99.7% of the performance, respectively. Based on the InfLLM-V2 framework, we have trained and open-sourced MiniCPM4.1 (https://huggingface.co/openbmb/MiniCPM4.1-8B), a hybrid reasoning model, providing a reproducible implementation for the research community.