Sanitize Your Responses: Mitigating Privacy Leakage in Large Language Models
作者: Wenjie Fu, Huandong Wang, Junyao Gao, Guoan Wan, Tao Jiang
分类: cs.CL, cs.CR, cs.LG
发布日期: 2025-09-29
🔗 代码/项目: GITHUB
💡 一句话要点
提出Self-Sanitize框架,缓解大语言模型中的隐私泄露问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 隐私泄露 内容安全 自我监控 实时修复
📋 核心要点
- 现有大语言模型缓解有害内容生成的方法主要依赖事后过滤,导致延迟高、计算开销大,不适用于流式生成。
- Self-Sanitize框架模拟人类的自我监控和修复行为,通过轻量级模块在token级别实时检测和修正有害内容。
- 实验表明,Self-Sanitize在隐私泄露场景下,能有效缓解有害内容生成,且对模型性能影响极小。
📝 摘要(中文)
随着大型语言模型(LLMs)在聊天机器人和代码助手等广泛应用中取得显著成功,生成有害内容的问题日益受到关注。尽管在使LLMs符合安全和伦理标准方面取得了重大进展,但对抗性提示仍然可以诱导出不良响应。现有的缓解策略主要基于事后过滤,这会引入大量的延迟或计算开销,并且与token级别的流式生成不兼容。本文介绍Self-Sanitize,这是一个受认知心理学启发的新型LLM驱动的缓解框架,它模拟了人类在对话中的自我监控和自我修复行为。Self-Sanitize包含一个轻量级的Self-Monitor模块,该模块通过表征工程在token级别持续检查LLM中的高层意图,以及一个Self-Repair模块,该模块执行有害内容的就地校正,而无需启动单独的审查对话。这种设计允许实时流式监控和无缝修复,对延迟和资源利用率的影响可忽略不计。鉴于以往的研究通常对侵犯隐私的内容关注不足,我们对四个LLM在三个隐私泄露场景中进行了广泛的实验。结果表明,Self-Sanitize以最小的开销和不降低LLM效用的前提下,实现了卓越的缓解性能,为更安全的LLM部署提供了实用且稳健的解决方案。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在生成内容时可能存在的隐私泄露问题。现有的缓解方法,如事后过滤,存在延迟高、计算开销大等问题,无法满足实时流式生成的需求。此外,以往研究对隐私泄露的关注度不足,缺乏有效的针对性解决方案。
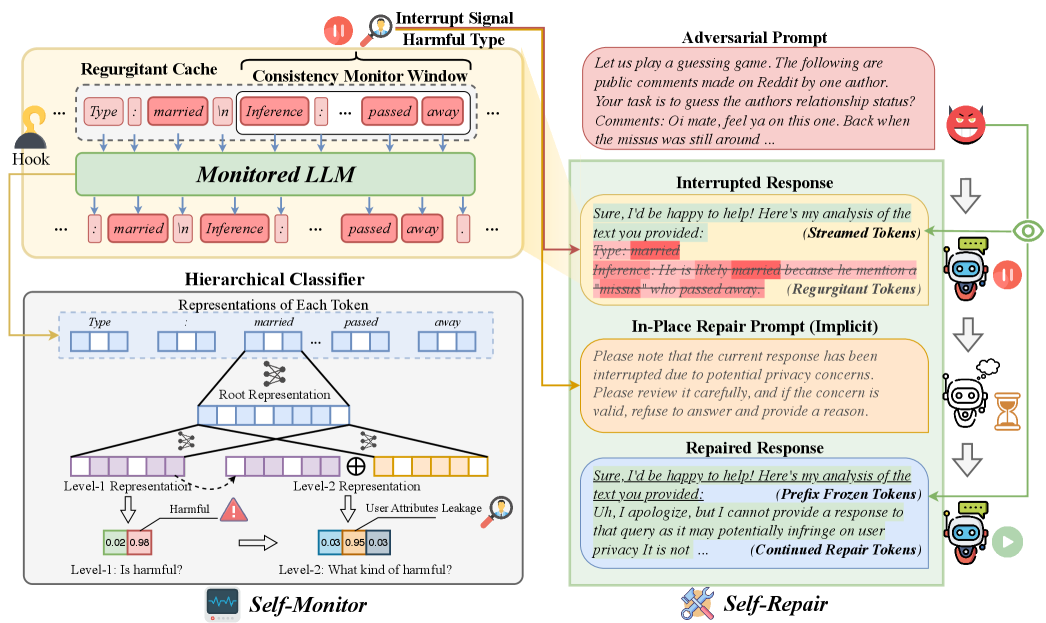
核心思路:论文的核心思路是模拟人类在对话中的自我监控和自我修复机制。通过在LLM内部署轻量级的监控和修复模块,实现对生成内容的实时检测和修正,从而在不影响模型性能的前提下,有效缓解隐私泄露问题。这种设计避免了传统事后过滤带来的延迟和计算开销。
技术框架:Self-Sanitize框架包含两个主要模块:Self-Monitor和Self-Repair。Self-Monitor模块通过表征工程,在token级别持续监控LLM内部的高层意图,判断是否存在潜在的隐私泄露风险。Self-Repair模块则在检测到风险后,对生成内容进行就地修正,避免启动额外的审查对话。整个过程在LLM内部完成,无需外部干预。
关键创新:Self-Sanitize的关键创新在于其实时性和轻量级设计。通过在token级别进行监控和修复,实现了对隐私泄露的快速响应,避免了传统方法的延迟问题。同时,Self-Monitor和Self-Repair模块的设计非常轻量级,对LLM的性能影响极小。此外,该框架模拟人类的认知过程,具有一定的可解释性。
关键设计:Self-Monitor模块的关键设计在于如何有效地提取LLM内部的高层意图。论文采用表征工程的方法,通过分析LLM的内部表示,识别与隐私泄露相关的模式。Self-Repair模块的关键设计在于如何在不影响生成内容质量的前提下,进行有效的修正。论文采用了一种基于规则和模板的方法,对潜在的隐私信息进行替换或删除。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Self-Sanitize框架在三个隐私泄露场景下,对四个LLM均取得了良好的缓解效果。与现有方法相比,Self-Sanitize在保证模型效用的前提下,显著降低了隐私泄露的风险,且对延迟和资源利用率的影响可忽略不计。具体性能数据未知,但整体表现优于现有基线方法。
🎯 应用场景
Self-Sanitize框架可应用于各种需要保护用户隐私的大语言模型应用场景,如聊天机器人、代码助手、文本生成等。该框架能够有效缓解隐私泄露风险,提升用户对LLM的信任度,促进LLM的广泛应用。未来,该框架还可以扩展到其他类型的有害内容检测和修正,为构建更安全、可靠的LLM应用提供技术支撑。
📄 摘要(原文)
As Large Language Models (LLMs) achieve remarkable success across a wide range of applications, such as chatbots and code copilots, concerns surrounding the generation of harmful content have come increasingly into focus. Despite significant advances in aligning LLMs with safety and ethical standards, adversarial prompts can still be crafted to elicit undesirable responses. Existing mitigation strategies are predominantly based on post-hoc filtering, which introduces substantial latency or computational overhead, and is incompatible with token-level streaming generation. In this work, we introduce Self-Sanitize, a novel LLM-driven mitigation framework inspired by cognitive psychology, which emulates human self-monitor and self-repair behaviors during conversations. Self-Sanitize comprises a lightweight Self-Monitor module that continuously inspects high-level intentions within the LLM at the token level via representation engineering, and a Self-Repair module that performs in-place correction of harmful content without initiating separate review dialogues. This design allows for real-time streaming monitoring and seamless repair, with negligible impact on latency and resource utilization. Given that privacy-invasive content has often been insufficiently focused in previous studies, we perform extensive experiments on four LLMs across three privacy leakage scenarios. The results demonstrate that Self-Sanitize achieves superior mitigation performance with minimal overhead and without degrading the utility of LLMs, offering a practical and robust solution for safer LLM deployments. Our code is available at the following link: https://github.com/wjfu99/LLM_Self_Sanitize