Alternatives To Next Token Prediction In Text Generation -- A Survey
作者: Charlie Wyatt, Aditya Joshi, Flora Salim
分类: cs.CL, cs.AI
发布日期: 2025-09-29
💡 一句话要点
综述:探索文本生成中下一词预测的替代方案,应对LLM的固有缺陷。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本生成 大型语言模型 下一词预测 多词预测 潜在推理 连续生成 非Transformer架构
📋 核心要点
- 大型语言模型依赖的下一词预测(NTP)存在长期规划不足、误差累积和计算效率低等问题。
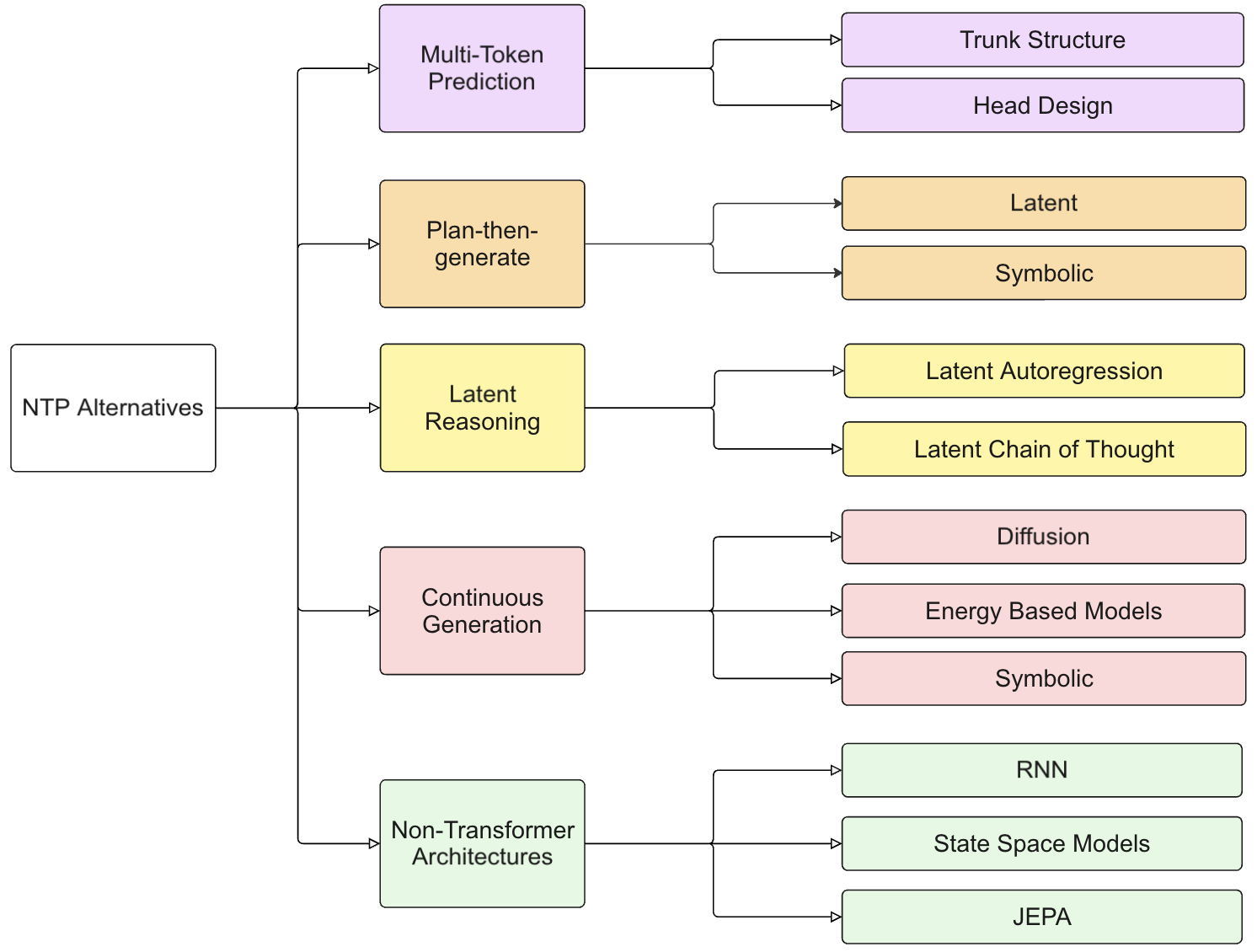
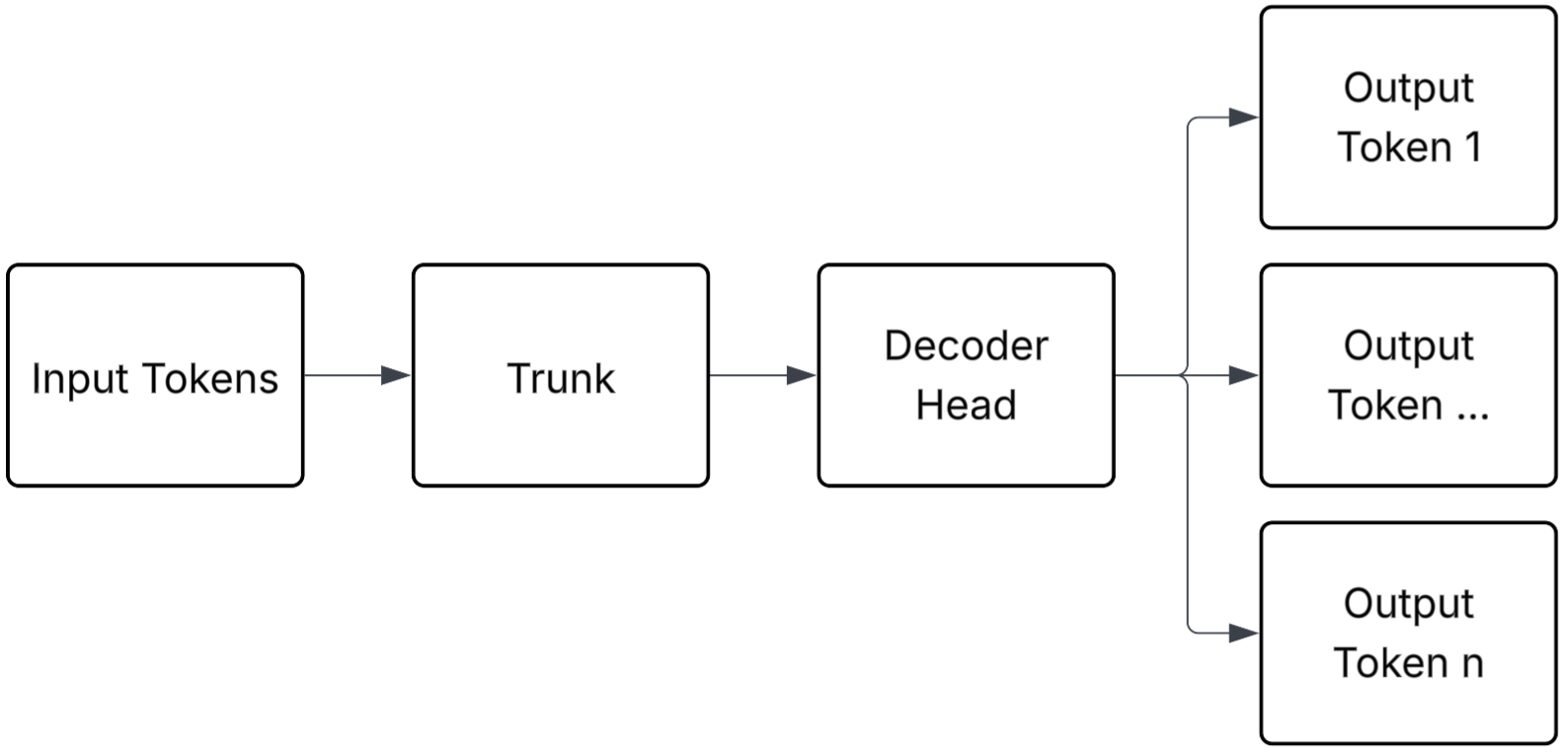
- 该综述探索了五类NTP的替代方案,包括多词预测、先规划后生成、潜在推理、连续生成方法和非Transformer架构。
- 通过对这些替代方案的分类和分析,旨在为研究人员提供指导,以开发克服NTP局限性的新型文本生成模型。
📝 摘要(中文)
下一词预测(NTP)范式推动了大型语言模型(LLM)的空前成功,但同时也导致了其最顽固的弱点,如长期规划能力差、误差累积和计算效率低下。本文旨在探讨NTP的替代方案,并对新兴的替代NTP的生态系统进行综述。我们将这些方法分为五个主要类别:(1)多词预测,它以未来的一组词为目标,而不是单个词;(2)先规划后生成,预先创建一个全局的、高层次的计划来指导词级别的解码;(3)潜在推理,将自回归过程本身转移到连续潜在空间中;(4)连续生成方法,通过扩散、流匹配或基于能量的方法,用迭代的、并行的细化代替顺序生成;(5)非Transformer架构,通过其固有的模型结构来规避NTP。通过综合这些方法的见解,本综述提供了一个分类法,以指导研究解决词级别生成的已知局限性的模型,从而为自然语言处理开发新的变革性模型。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中由于采用下一词预测(NTP)范式而导致的固有缺陷,例如长期规划能力差、误差累积和计算效率低下。现有方法主要依赖于逐个预测下一个词,缺乏全局规划和长期依赖关系建模能力,容易产生语义不连贯和逻辑错误。
核心思路:论文的核心思路是探索和总结各种替代NTP的文本生成方法,并将其归纳为五个主要类别。通过分析这些替代方案的优缺点,为研究人员提供一个全面的视角,从而启发新的文本生成模型的设计。这些替代方案旨在克服NTP的局限性,提高生成文本的质量、连贯性和效率。
技术框架:论文构建了一个关于NTP替代方案的分类框架,包括:(1) 多词预测:一次预测多个token;(2) 先规划后生成:先生成全局计划,再根据计划生成文本;(3) 潜在推理:在连续潜在空间中进行自回归生成;(4) 连续生成方法:使用扩散模型等进行迭代优化;(5) 非Transformer架构:使用非自回归模型避免NTP。论文对每个类别下的代表性方法进行了详细描述和分析。
关键创新:论文的主要创新在于对现有NTP替代方案进行了系统的分类和总结,并提出了一个清晰的分类框架。该框架有助于研究人员理解不同方法的优缺点,并为未来的研究方向提供指导。此外,论文还强调了这些替代方案在解决LLM固有缺陷方面的潜力。
关键设计:论文没有提出新的模型或算法,而是一个综述性的工作,因此没有具体的参数设置或网络结构设计。但是,论文对每个类别下的代表性方法进行了详细描述,包括其核心算法、网络结构和损失函数等。例如,对于多词预测,论文讨论了不同的解码策略和训练目标;对于先规划后生成,论文分析了不同的规划方法和文本生成模型的结合方式。
🖼️ 关键图片

📊 实验亮点
该综述论文系统地整理了下一词预测(NTP)的多种替代方案,为研究人员提供了一个全面的视角,有助于理解不同方法的优缺点。通过对这些替代方案的分析,可以为未来的研究方向提供指导,并推动自然语言处理技术的进一步发展。该论文没有提供具体的性能数据,但强调了这些替代方案在解决LLM固有缺陷方面的潜力。
🎯 应用场景
该研究成果可应用于各种自然语言生成任务,例如机器翻译、文本摘要、对话生成和故事创作。通过采用NTP的替代方案,可以提高生成文本的质量、连贯性和长期规划能力,从而改善用户体验。此外,该研究还有助于开发更高效、更可靠的文本生成系统,并推动自然语言处理技术的进一步发展。
📄 摘要(原文)
The paradigm of Next Token Prediction (NTP) has driven the unprecedented success of Large Language Models (LLMs), but is also the source of their most persistent weaknesses such as poor long-term planning, error accumulation, and computational inefficiency. Acknowledging the growing interest in exploring alternatives to NTP, the survey describes the emerging ecosystem of alternatives to NTP. We categorise these approaches into five main families: (1) Multi-Token Prediction, which targets a block of future tokens instead of a single one; (2) Plan-then-Generate, where a global, high-level plan is created upfront to guide token-level decoding; (3) Latent Reasoning, which shifts the autoregressive process itself into a continuous latent space; (4) Continuous Generation Approaches, which replace sequential generation with iterative, parallel refinement through diffusion, flow matching, or energy-based methods; and (5) Non-Transformer Architectures, which sidestep NTP through their inherent model structure. By synthesizing insights across these methods, this survey offers a taxonomy to guide research into models that address the known limitations of token-level generation to develop new transformative models for natural language processing.