AlignX: Advancing Multilingual Large Language Models with Multilingual Representation Alignment
作者: Mengyu Bu, Shaolei Zhang, Zhongjun He, Hua Wu, Yang Feng
分类: cs.CL
发布日期: 2025-09-29
备注: Accepted to EMNLP 2025 Main Conference. The code will be available at https://github.com/ictnlp/AlignX
💡 一句话要点
AlignX:通过多语言表示对齐提升多语言大语言模型性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言大模型 表示对齐 跨语言学习 指令微调 多语言语义对齐 语言特征集成 对比学习
📋 核心要点
- 多语言大模型在非优势语言上的性能和跨语言对齐效果不佳,直接微调难以有效提升。
- AlignX通过两阶段表示对齐框架,首先对齐多语言表示,然后进行多语言指令微调,提升模型多语言能力。
- 实验表明,AlignX能有效提升多语言大模型的通用和跨语言生成能力,并改善跨语言对齐。
📝 摘要(中文)
多语言大型语言模型(LLMs)具有令人印象深刻的多语言理解和生成能力。然而,对于非优势语言,它们的性能和跨语言对齐通常滞后。一个常见的解决方案是在大规模和更平衡的多语言语料库上微调LLMs,但这种方法通常导致不精确的对齐和次优的知识转移,难以在各种语言上取得有限的改进。在本文中,我们提出了AlignX来弥合多语言性能差距,这是一个两阶段的表示级别框架,用于增强预训练LLMs的多语言性能。在第一阶段,我们通过多语言语义对齐和语言特征集成来对齐多语言表示。在第二阶段,我们通过多语言指令微调来激发LLMs的多语言能力。在几个预训练LLMs上的实验结果表明,我们的方法增强了LLMs的多语言通用和跨语言生成能力。进一步的分析表明,AlignX使多语言表示更接近,并改善了跨语言对齐。
🔬 方法详解
问题定义:多语言大语言模型在处理非优势语言时,性能往往低于优势语言,且跨语言能力较弱。直接在大规模多语言语料库上进行微调,虽然可以增加模型对非优势语言的接触,但容易导致模型对齐不精确,知识迁移效果不佳,最终提升效果有限。现有方法的痛点在于无法有效对齐不同语言的表示空间,导致模型难以充分利用多语言数据中的信息。
核心思路:AlignX的核心思路是通过表示级别的对齐来提升多语言大模型的性能。具体来说,它首先通过多语言语义对齐和语言特征集成来对齐不同语言的表示空间,使得模型能够更好地理解和处理不同语言之间的关系。然后,通过多语言指令微调来进一步激发模型的多语言能力,使其能够更好地完成各种多语言任务。这样设计的目的是为了从根本上解决多语言表示不对齐的问题,从而提升模型的多语言性能。
技术框架:AlignX是一个两阶段的框架。第一阶段是多语言表示对齐,包括两个子模块:多语言语义对齐和语言特征集成。多语言语义对齐旨在将不同语言的语义表示映射到同一个空间中,使得语义相似的句子在表示空间中也更加接近。语言特征集成则旨在将不同语言的语言特征(如词性、句法结构等)融入到表示中,从而增强模型对不同语言的理解能力。第二阶段是多语言指令微调,使用多语言指令数据对模型进行微调,使其能够更好地完成各种多语言任务。
关键创新:AlignX最重要的技术创新点在于其表示级别的对齐方法。与直接微调相比,AlignX更加注重对齐不同语言的表示空间,从而使得模型能够更好地理解和处理不同语言之间的关系。这种表示级别的对齐方法可以有效地解决多语言表示不对齐的问题,从而提升模型的多语言性能。此外,AlignX还采用了多语言语义对齐和语言特征集成两种不同的对齐方法,从而更加全面地对齐不同语言的表示空间。
关键设计:在多语言语义对齐方面,论文可能采用了对比学习的方法,通过最小化语义相似句子之间的距离,最大化语义不相似句子之间的距离,来对齐不同语言的表示空间。在语言特征集成方面,论文可能采用了注意力机制,将不同语言的语言特征融入到表示中。在多语言指令微调方面,论文可能采用了不同的指令模板和数据增强方法,来增加模型对不同多语言任务的适应性。具体的参数设置、损失函数和网络结构等技术细节在论文中应该有更详细的描述。
🖼️ 关键图片

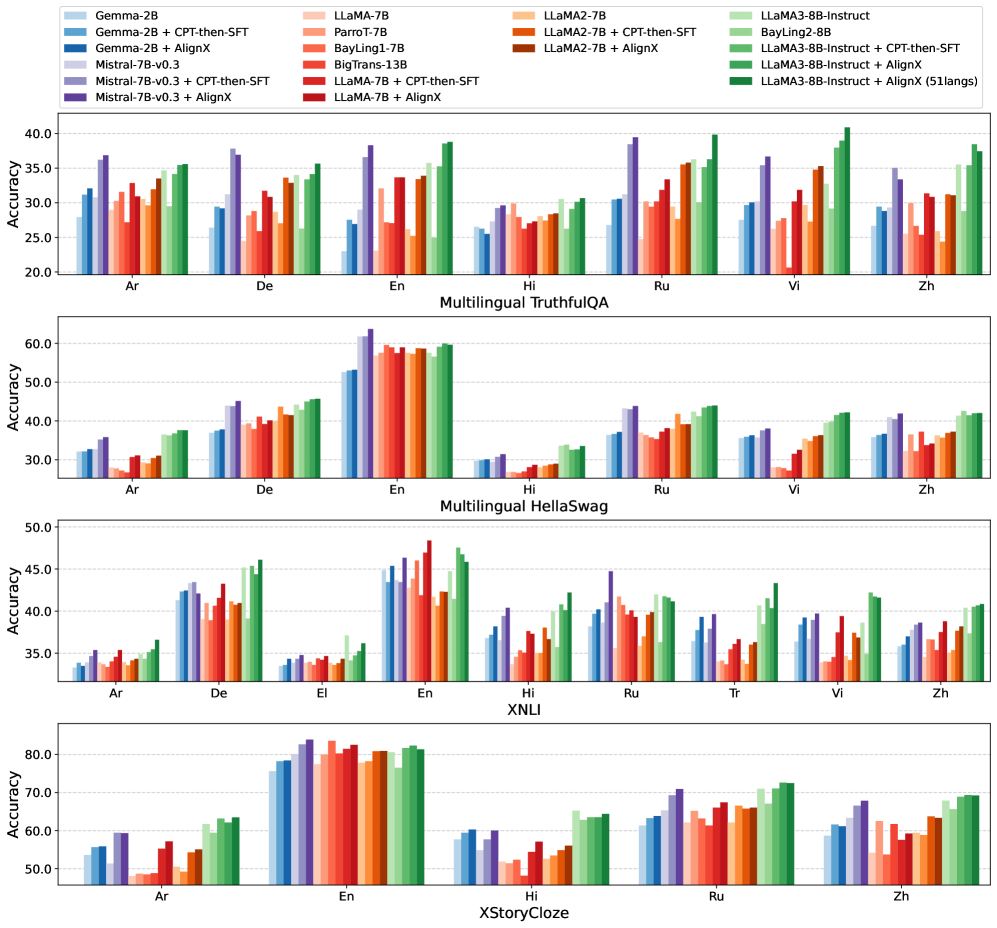

📊 实验亮点
实验结果表明,AlignX在多个预训练LLMs上都取得了显著的性能提升。具体来说,AlignX在多语言通用能力和跨语言生成能力方面都优于基线模型。进一步的分析表明,AlignX能够使多语言表示更接近,并改善跨语言对齐。这些结果表明,AlignX是一种有效的多语言大模型性能提升方法。
🎯 应用场景
AlignX具有广泛的应用前景,可以应用于机器翻译、跨语言信息检索、多语言文本摘要、多语言问答等领域。该研究的实际价值在于提升了多语言大模型的性能,使得这些模型能够更好地处理非优势语言,从而促进了全球范围内的信息交流和知识共享。未来,AlignX可以进一步扩展到更多的语言和任务,并与其他技术相结合,从而构建更加强大的多语言智能系统。
📄 摘要(原文)
Multilingual large language models (LLMs) possess impressive multilingual understanding and generation capabilities. However, their performance and cross-lingual alignment often lag for non-dominant languages. A common solution is to fine-tune LLMs on large-scale and more balanced multilingual corpus, but such approaches often lead to imprecise alignment and suboptimal knowledge transfer, struggling with limited improvements across languages. In this paper, we propose AlignX to bridge the multilingual performance gap, which is a two-stage representation-level framework for enhancing multilingual performance of pre-trained LLMs. In the first stage, we align multilingual representations with multilingual semantic alignment and language feature integration. In the second stage, we stimulate the multilingual capability of LLMs via multilingual instruction fine-tuning. Experimental results on several pre-trained LLMs demonstrate that our approach enhances LLMs' multilingual general and cross-lingual generation capability. Further analysis indicates that AlignX brings the multilingual representations closer and improves the cross-lingual alignment.