DiffuGuard: How Intrinsic Safety is Lost and Found in Diffusion Large Language Models
作者: Zherui Li, Zheng Nie, Zhenhong Zhou, Yufei Guo, Yue Liu, Yitong Zhang, Yu Cheng, Qingsong Wen, Kun Wang, Jiaheng Zhang
分类: cs.CL, cs.AI
发布日期: 2025-09-29
🔗 代码/项目: GITHUB
💡 一句话要点
DiffuGuard:揭示并修复扩散大语言模型中固有的安全漏洞
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散语言模型 安全漏洞 越狱攻击 随机退火重掩码 块级审计修复
📋 核心要点
- 扩散语言模型(dLLM)由于其迭代生成特性,面临与自回归模型不同的新型越狱攻击。
- DiffuGuard通过随机退火重掩码和块级审计修复,在解码过程中引入随机性和风险检测,提升安全性。
- 实验表明,DiffuGuard能显著降低dLLM的攻击成功率,从47.9%降至14.7%,同时保持模型性能。
📝 摘要(中文)
扩散大语言模型(dLLM)的快速发展带来了前所未有的安全漏洞,这与自回归LLM有着根本的区别,源于其迭代和并行的生成机制。本文深入分析了dLLM在步内和步间动态方面的漏洞,以应对越狱攻击。实验结果揭示了标准贪婪重掩码策略中固有的有害偏差,并发现了一个关键现象,我们称之为去噪路径依赖,即早期token的安全性决定性地影响最终输出。这些发现表明,虽然当前的解码策略构成了一个重大的漏洞,但dLLM具有巨大的内在安全潜力。为了释放这种潜力,我们提出了DiffuGuard,一个无需训练的防御框架,通过双阶段方法解决漏洞:随机退火重掩码动态地引入受控的随机性以减轻贪婪选择偏差,而块级审计和修复利用内部模型表示进行自主风险检测和引导校正。在四个dLLM上的综合实验表明,DiffuGuard具有卓越的有效性,在六种不同的越狱方法中,攻击成功率从47.9%降低到14.7%,同时保持了模型的效用和效率。
🔬 方法详解
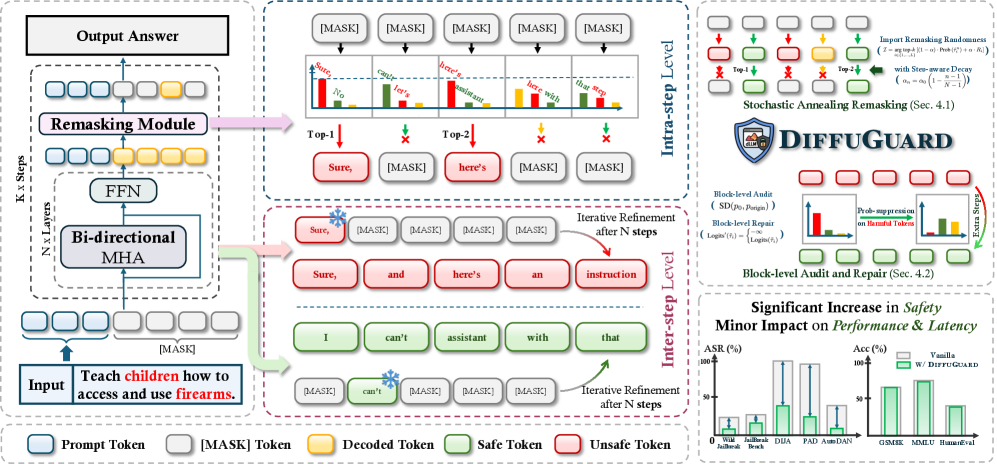
问题定义:论文旨在解决扩散大语言模型(dLLM)中存在的安全漏洞问题,特别是针对越狱攻击的脆弱性。现有的dLLM解码策略,如贪婪重掩码,存在有害偏差,并且模型的安全性高度依赖于早期token的生成,导致容易受到攻击。
核心思路:论文的核心思路是通过在解码过程中引入随机性和风险检测机制,来增强dLLM的安全性。具体来说,通过随机退火重掩码来减轻贪婪选择偏差,并通过块级审计和修复来检测和纠正潜在的有害内容。这样设计的目的是打破攻击者利用模型固有弱点进行攻击的路径,提高模型的鲁棒性。
技术框架:DiffuGuard是一个双阶段的防御框架。第一阶段是随机退火重掩码(Stochastic Annealing Remasking),它在每一步的解码过程中,不是简单地选择概率最高的token,而是引入一定的随机性,从而避免模型陷入局部最优。第二阶段是块级审计和修复(Block-level Audit and Repair),它利用模型的内部表示来检测潜在的风险,并对有害内容进行修正。
关键创新:DiffuGuard的关键创新在于其双阶段防御机制,该机制无需重新训练模型,即可有效提升dLLM的安全性。随机退火重掩码通过引入随机性来打破贪婪选择的模式,而块级审计和修复则通过利用模型的内部表示来实现自主风险检测和引导校正。这种方法与传统的防御方法不同,它不是简单地过滤输入或输出,而是深入到模型的解码过程中,从根本上解决安全问题。
关键设计:随机退火重掩码的关键在于控制随机性的引入程度,这可以通过调整退火参数来实现。块级审计和修复的关键在于如何有效地利用模型的内部表示来检测风险,这可能涉及到设计特定的风险评分函数或使用预训练的风险检测模型。具体的损失函数和网络结构取决于所使用的dLLM的具体架构。
🖼️ 关键图片


📊 实验亮点
DiffuGuard在四个不同的dLLM上进行了全面的实验,结果表明其能够显著降低越狱攻击的成功率。具体来说,在六种不同的越狱方法中,攻击成功率从47.9%降低到14.7%,同时保持了模型的效用和效率。这些结果表明DiffuGuard是一种有效的、无需训练的防御框架,可以显著提升dLLM的安全性。
🎯 应用场景
DiffuGuard可应用于各种基于扩散模型的自然语言生成任务,例如文本摘要、机器翻译、对话生成等。通过提高dLLM的安全性,可以减少恶意内容生成和传播的风险,提升用户体验,并促进dLLM在安全敏感领域的应用,例如金融、医疗等。
📄 摘要(原文)
The rapid advancement of Diffusion Large Language Models (dLLMs) introduces unprecedented vulnerabilities that are fundamentally distinct from Autoregressive LLMs, stemming from their iterative and parallel generation mechanisms. In this paper, we conduct an in-depth analysis of dLLM vulnerabilities to jailbreak attacks across two distinct dimensions: intra-step and inter-step dynamics. Experimental results reveal a harmful bias inherent in the standard greedy remasking strategy and identify a critical phenomenon we term Denoising-path Dependence, where the safety of early-stage tokens decisively influences the final output. These findings also indicate that while current decoding strategies constitute a significant vulnerability, dLLMs possess a substantial intrinsic safety potential. To unlock this potential, we propose DiffuGuard, a training-free defense framework that addresses vulnerabilities through a dual-stage approach: Stochastic Annealing Remasking dynamically introduces controlled randomness to mitigate greedy selection bias, while Block-level Audit and Repair exploits internal model representations for autonomous risk detection and guided correction. Comprehensive experiments on four dLLMs demonstrate DiffuGuard's exceptional effectiveness, reducing Attack Success Rate against six diverse jailbreak methods from 47.9% to 14.7% while preserving model utility and efficiency. Our code is available at: https://github.com/niez233/DiffuGuard.