Let LLMs Speak Embedding Languages: Generative Text Embeddings via Iterative Contrastive Refinement
作者: Yu-Che Tsai, Kuan-Yu Chen, Yuan-Chi Li, Yuan-Hao Chen, Ching-Yu Tsai, Shou-De Lin
分类: cs.CL, cs.AI
发布日期: 2025-09-29
💡 一句话要点
提出GIRCSE,利用生成式LLM迭代优化文本嵌入,提升语义表征能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本嵌入 大型语言模型 生成式模型 对比学习 迭代优化
📋 核心要点
- 现有基于LLM的文本嵌入方法主要依赖encoder-only模型,忽略了LLM强大的生成能力,限制了语义表征的上限。
- GIRCSE框架利用LLM的自回归生成能力,通过迭代生成和对比学习,逐步提炼文本的语义表示,捕捉更深层次的语义信息。
- 实验结果表明,GIRCSE在多个基准测试中显著优于现有的LLM嵌入方法,并展现出测试时性能随生成token数量增加而提升的特性。
📝 摘要(中文)
本文提出了一种名为GIRCSE(Generative Iterative Refinement for Contrastive Sentence Embeddings)的新框架,该框架利用自回归生成能力迭代地优化语义表示,从而克服了现有基于LLM的嵌入方法通常采用encoder-only范式,将LLM视为静态特征提取器并忽略其生成优势的局限性。GIRCSE通过生成在对比目标下优化的软token序列,捕捉encoder-only方法通常遗漏的潜在概念和隐式语义。为了指导这一过程,本文提出了一种迭代对比细化(ICR)目标,该目标鼓励每个细化步骤产生更好的表示。大量实验表明,GIRCSE在MTEB基准测试和指令跟随任务上优于强大的基于LLM的嵌入基线。此外,GIRCSE表现出一种涌现的测试时缩放特性:在推理时生成更多token可以稳定地提高嵌入质量。研究结果表明,生成式迭代细化是表示学习的一种新范式。
🔬 方法详解
问题定义:现有基于大型语言模型(LLM)的文本嵌入方法通常采用encoder-only架构,将LLM视为静态的特征提取器。这种方法忽略了LLM强大的生成能力,无法充分利用LLM所蕴含的知识和推理能力来提升文本嵌入的质量。现有方法的痛点在于无法有效捕捉文本中潜在的概念和隐式语义,导致嵌入的语义表达能力受限。
核心思路:GIRCSE的核心思路是利用LLM的自回归生成能力,通过迭代地生成和优化“软token”序列来逐步提炼文本的语义表示。这些软token并非直接对应于词汇表中的单词,而是代表着潜在的语义概念。通过对比学习,GIRCSE鼓励生成的软token序列能够更好地表达文本的语义信息,从而提升嵌入的质量。这种迭代细化的过程允许模型逐步挖掘文本中更深层次的语义信息。
技术框架:GIRCSE框架包含以下主要阶段:1)初始化:使用LLM对输入文本进行编码,得到初始的文本嵌入表示。2)迭代生成:基于初始嵌入,LLM自回归地生成一系列软token。每个软token的生成都受到对比学习目标的指导,旨在提升整体嵌入的质量。3)对比学习:使用对比学习损失函数,鼓励生成的软token序列能够更好地区分不同的文本,并捕捉文本之间的语义相似性。4)嵌入更新:将生成的软token序列与初始嵌入进行融合,得到更新后的文本嵌入表示。重复迭代生成和对比学习的过程,直到嵌入的质量达到预定的标准。
关键创新:GIRCSE最重要的技术创新点在于将LLM的生成能力引入到文本嵌入的学习过程中。与传统的encoder-only方法不同,GIRCSE通过迭代地生成和优化软token序列,能够更有效地捕捉文本中潜在的概念和隐式语义。此外,GIRCSE还提出了一种迭代对比细化(ICR)目标,该目标能够有效地指导生成过程,确保每个细化步骤都能提升嵌入的质量。
关键设计:GIRCSE的关键设计包括:1)软token表示:使用连续的向量表示软token,而不是离散的词汇表索引。这允许模型更灵活地表达语义概念。2)对比学习损失函数:采用InfoNCE损失函数,鼓励生成的软token序列能够更好地区分不同的文本。3)迭代次数:通过实验确定最佳的迭代次数,以平衡嵌入的质量和计算成本。4)温度参数:在对比学习损失函数中使用温度参数来控制正负样本之间的区分度。
🖼️ 关键图片


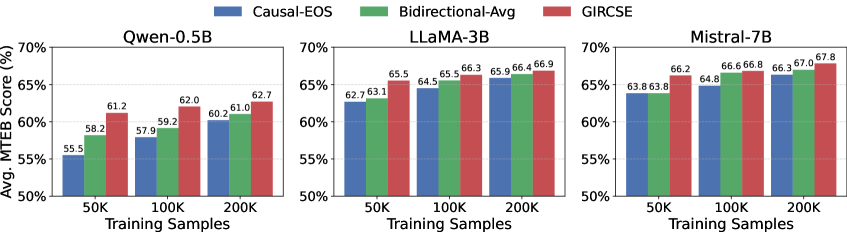
📊 实验亮点
实验结果表明,GIRCSE在MTEB基准测试中取得了显著的性能提升,优于多个强大的基于LLM的嵌入基线。例如,在某些任务上,GIRCSE的性能提升超过5%。此外,GIRCSE还展现出一种涌现的测试时缩放特性:在推理时生成更多token可以稳定地提高嵌入质量。这表明GIRCSE能够有效地利用LLM的生成能力来提升文本嵌入的质量。
🎯 应用场景
GIRCSE框架可广泛应用于各种需要高质量文本嵌入的场景,例如语义搜索、文本分类、文本聚类、信息检索和自然语言推理。该方法能够提升LLM在下游任务中的性能,并为开发更强大的自然语言处理系统提供新的思路。此外,GIRCSE的迭代细化思想也可以应用于其他模态数据的表示学习。
📄 摘要(原文)
Existing large language model (LLM)-based embeddings typically adopt an encoder-only paradigm, treating LLMs as static feature extractors and overlooking their core generative strengths. We introduce GIRCSE (Generative Iterative Refinement for Contrastive Sentence Embeddings), a novel framework that leverages autoregressive generation to iteratively refine semantic representations. By producing sequences of soft tokens optimized under contrastive objective, GIRCSE captures latent concepts and implicit semantics that encoder-only methods often miss. To guide this process, we propose an Iterative Contrastive Refinement (ICR) objective that encourages each refinement step to yield better representations. Extensive experiments show that GIRCSE outperforms strong LLM-based embedding baselines on the MTEB benchmark and instruction-following tasks. Moreover, GIRCSE exhibits an emergent test-time scaling property: generating more tokens at inference steadily improves embedding quality. Our results establish generative iterative refinement as a new paradigm for representation learning.