AceSearcher: Bootstrapping Reasoning and Search for LLMs via Reinforced Self-Play
作者: Ran Xu, Yuchen Zhuang, Zihan Dong, Jonathan Wang, Yue Yu, Joyce C. Ho, Linjun Zhang, Haoyu Wang, Wenqi Shi, Carl Yang
分类: cs.CL, cs.AI, cs.IR, cs.LG
发布日期: 2025-09-29
备注: Accepted to NeurIPS 2025 (Spotlight)
🔗 代码/项目: GITHUB | HUGGINGFACE
💡 一句话要点
AceSearcher:通过强化自博弈引导LLM进行推理和搜索,提升复杂推理任务性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 搜索增强 强化学习 自博弈 推理 知识检索 金融推理
📋 核心要点
- 现有搜索增强LLM在复杂推理任务中表现不佳,主要原因是多跳检索效果不佳和推理能力有限。
- AceSearcher通过协同自博弈框架,训练LLM交替扮演分解者和解决者,从而提升推理和搜索能力。
- 实验结果表明,AceSearcher在多个推理任务上显著优于现有方法,尤其是在参数效率方面表现突出。
📝 摘要(中文)
本文提出AceSearcher,一个协同自博弈框架,用于训练单个大型语言模型(LLM)在两种角色之间交替:分解者,分解复杂查询;解决者,整合检索到的上下文以生成答案。AceSearcher将监督式微调(在搜索、推理和分解任务的混合数据集上)与强化式微调(针对最终答案准确性优化)相结合,无需中间标注。在10个数据集上的三个推理密集型任务的大量实验表明,AceSearcher优于最先进的基线,平均精确匹配率提高了7.6%。值得注意的是,在文档级金融推理任务中,AceSearcher-32B的性能与DeepSeek-V3模型相当,但参数量不到其5%。即使在较小的规模(1.5B和8B)下,AceSearcher通常也超过了参数量高达9倍的现有搜索增强LLM,突显了其在解决复杂推理任务方面的卓越效率和有效性。
🔬 方法详解
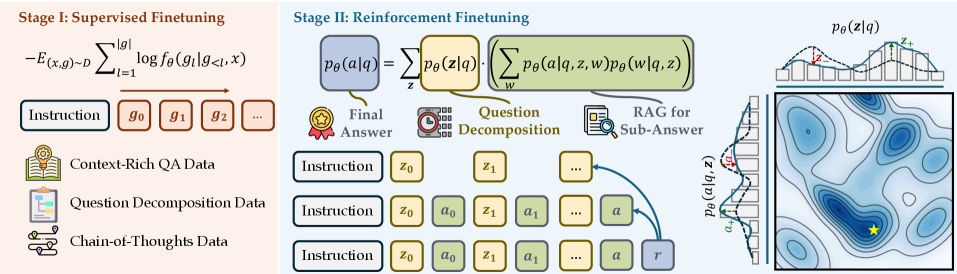
问题定义:现有搜索增强的LLM在处理复杂推理任务时,面临着多跳检索效果差和推理能力不足的问题。这些问题限制了它们在需要深度推理和知识整合的场景中的应用。现有的方法往往依赖于复杂的pipeline或者需要大量的中间标注数据,增加了训练的难度和成本。
核心思路:AceSearcher的核心思路是利用自博弈的方式,让同一个LLM扮演分解者和解决者两种角色。分解者负责将复杂查询分解为更小的、可搜索的子问题,而解决者则负责整合检索到的上下文信息,生成最终答案。通过这种协同的方式,模型可以更好地利用外部知识,并提升推理能力。
技术框架:AceSearcher的整体框架包含两个主要阶段:监督式微调和强化式微调。在监督式微调阶段,模型在包含搜索、推理和分解任务的混合数据集上进行训练,使其具备初步的分解和解决问题的能力。在强化式微调阶段,模型通过强化学习的方式,根据最终答案的准确性进行优化,从而进一步提升其推理和搜索能力。整个过程无需中间标注,降低了训练成本。
关键创新:AceSearcher的关键创新在于其协同自博弈框架。通过让同一个LLM扮演分解者和解决者两种角色,模型可以更好地学习如何利用外部知识进行推理。此外,AceSearcher采用强化学习的方式进行微调,无需中间标注,降低了训练成本。这种方法与传统的pipeline方法相比,更加灵活和高效。
关键设计:AceSearcher的关键设计包括:1) 使用混合数据集进行监督式微调,确保模型具备初步的分解和解决问题的能力;2) 使用强化学习算法(具体算法未知)根据最终答案的准确性进行优化;3) 设计合适的奖励函数,鼓励模型生成准确的答案;4) 通过调整分解者和解决者的角色比例,平衡模型的分解和解决问题的能力。具体参数设置和网络结构细节在论文中可能有所描述,但摘要中未提及。
🖼️ 关键图片


📊 实验亮点
AceSearcher在三个推理密集型任务的10个数据集上取得了显著的性能提升,平均精确匹配率提高了7.6%。在文档级金融推理任务中,AceSearcher-32B的性能与DeepSeek-V3模型相当,但参数量不到其5%。即使在较小的规模(1.5B和8B)下,AceSearcher也超过了参数量高达9倍的现有搜索增强LLM,展示了其卓越的效率和有效性。
🎯 应用场景
AceSearcher具有广泛的应用前景,例如金融分析、法律咨询、医疗诊断等需要深度推理和知识整合的领域。它可以帮助人们更有效地利用海量信息,做出更准确的决策。未来,AceSearcher可以进一步扩展到其他领域,并与其他技术(如知识图谱、多模态学习)相结合,实现更强大的推理能力。
📄 摘要(原文)
Search-augmented LLMs often struggle with complex reasoning tasks due to ineffective multi-hop retrieval and limited reasoning ability. We propose AceSearcher, a cooperative self-play framework that trains a single large language model (LLM) to alternate between two roles: a decomposer that breaks down complex queries and a solver that integrates retrieved contexts for answer generation. AceSearcher couples supervised fine-tuning on a diverse mixture of search, reasoning, and decomposition tasks with reinforcement fine-tuning optimized for final answer accuracy, eliminating the need for intermediate annotations. Extensive experiments on three reasoning-intensive tasks across 10 datasets show that AceSearcher outperforms state-of-the-art baselines, achieving an average exact match improvement of 7.6%. Remarkably, on document-level finance reasoning tasks, AceSearcher-32B matches the performance of the DeepSeek-V3 model using less than 5% of its parameters. Even at smaller scales (1.5B and 8B), AceSearcher often surpasses existing search-augmented LLMs with up to 9x more parameters, highlighting its exceptional efficiency and effectiveness in tackling complex reasoning tasks. Our code will be published at https://github.com/ritaranx/AceSearcher and https://huggingface.co/AceSearcher.