Beyond Overall Accuracy: A Psychometric Deep Dive into the Topic-Specific Medical Capabilities of 80 Large Language Models
作者: Zhimeng Luo, Lixin Wu, Adam Frisch, Daqing He
分类: cs.CL, cs.AI
发布日期: 2025-09-29
💡 一句话要点
提出MedIRT框架,利用项目反应理论评估LLM的医学能力,揭示模型专长与缺陷。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 医学能力评估 项目反应理论 USMLE 基准测试
📋 核心要点
- 现有LLM医学能力评估方法依赖总体准确率,无法捕捉问题特征和特定主题的性能差异。
- 提出MedIRT框架,利用项目反应理论(IRT)评估LLM在不同医学主题上的潜在能力。
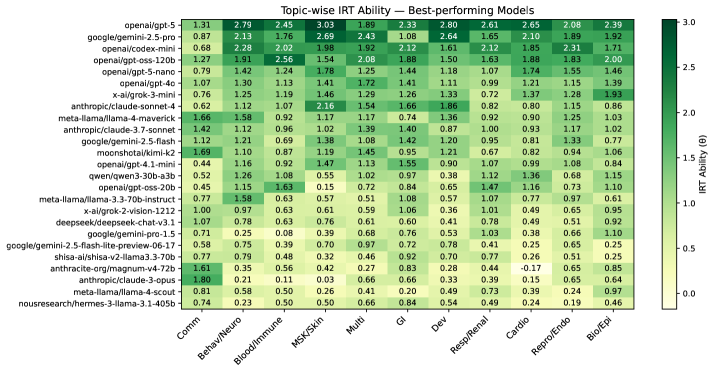
- 实验表明,即使总体排名较低的模型,在特定领域也可能超越领先模型,揭示模型能力的“尖峰”现象。
📝 摘要(中文)
随着大型语言模型(LLMs)越来越多地应用于高风险医疗场景,可靠和准确的评估方法变得至关重要。传统的准确率指标无法充分捕捉问题的特征,也无法提供针对特定主题的深入见解。为了解决这一问题,我们引入了 extsc{MedIRT},这是一个基于项目反应理论(IRT)的严格评估框架,IRT是高风险教育测试中的黄金标准。与以往依赖存档数据的研究不同,我们前瞻性地从80个不同的LLM中收集了对1100个与USMLE对齐的平衡基准问题的新鲜回答。通过对每个主题使用一个单维双参数logistic IRT模型,我们联合估计LLM的潜在模型能力以及问题的难度和区分度,从而产生比单独的准确率更稳定和细致的性能排名。值得注意的是,我们发现了独特的“尖峰”能力曲线,其中总体排名可能因高度专业的模型能力而具有误导性。虽然 exttt{GPT-5}在大多数领域(11个中的8个)中表现最佳,但在社会科学和交流方面,它被 exttt{Claude-3-opus}超越,这表明即使是总体排名第23位的模型也可以在特定能力方面占据首位。此外,我们证明了IRT在审计基准方面通过识别有缺陷的问题的效用。我们将这些发现综合到一个实用的决策支持框架中,该框架将我们的多因素能力概况与运营指标相结合。这项工作建立了一种稳健的、心理测量学基础的方法,对于在医疗保健中安全、有效和可信地部署LLM至关重要。
🔬 方法详解
问题定义:现有的大型语言模型(LLMs)在医疗领域的应用日益广泛,但传统的评估方法,如总体准确率,无法充分反映模型在不同医学主题上的能力差异。这种评估方式忽略了问题的难度和区分度,以及模型在特定领域的专长或缺陷,导致对模型能力的评估不够精细和可靠。
核心思路:论文的核心思路是借鉴教育测量学中的项目反应理论(IRT),将LLM的医学能力评估视为一个测量过程,通过分析模型在不同难度和区分度的问题上的表现,来推断模型的潜在能力。这种方法能够更准确地评估模型在各个医学主题上的能力,并识别模型的优势和不足。
技术框架:MedIRT框架主要包含以下几个阶段:1) 数据收集:收集LLM对USMLE(美国执业医师资格考试)对齐的医学问题的回答。2) IRT建模:对每个医学主题,使用一个单维双参数logistic IRT模型,联合估计LLM的潜在能力、问题的难度和区分度。3) 能力评估:根据IRT模型的估计结果,生成LLM在各个医学主题上的能力概况。4) 基准审计:利用IRT模型识别有缺陷的问题,并对基准进行改进。5) 决策支持:将能力概况与运营指标相结合,为LLM在医疗领域的部署提供决策支持。
关键创新:MedIRT的关键创新在于将项目反应理论(IRT)应用于LLM的医学能力评估。与传统的准确率评估方法相比,IRT能够更准确地评估模型在各个医学主题上的能力,并识别模型的优势和不足。此外,MedIRT还能够用于审计医学基准,识别有缺陷的问题,从而提高基准的质量。
关键设计:论文采用单维双参数logistic IRT模型,该模型包含两个参数:难度参数和区分度参数。难度参数表示问题的难度,区分度参数表示问题区分不同能力水平的考生的能力。论文使用最大似然估计方法来估计IRT模型的参数。此外,论文还设计了一个决策支持框架,将LLM的能力概况与运营指标相结合,为LLM在医疗领域的部署提供决策支持。
🖼️ 关键图片


📊 实验亮点
研究对80个LLM在1100个USMLE对齐问题上进行了评估,发现GPT-5在8个领域表现最佳,但在社会科学和交流方面被Claude-3-opus超越。结果表明,即使总体排名较低的模型,在特定领域也可能表现出色。MedIRT框架还成功识别出基准测试中的缺陷问题,验证了其在基准审计方面的有效性。
🎯 应用场景
MedIRT框架可用于评估和比较不同LLM在医学领域的专业能力,帮助医疗机构选择最适合其需求的模型。该框架还可用于识别LLM的知识盲点,指导模型训练和优化。此外,MedIRT还可用于审计医学知识库和考试题库,提高其质量和可靠性,最终提升医疗服务的质量和效率。
📄 摘要(原文)
As Large Language Models (LLMs) are increasingly proposed for high-stakes medical applications, there has emerged a critical need for reliable and accurate evaluation methodologies. Traditional accuracy metrics fail inadequately as they neither capture question characteristics nor offer topic-specific insights. To address this gap, we introduce \textsc{MedIRT}, a rigorous evaluation framework grounded in Item Response Theory (IRT), the gold standard in high-stakes educational testing. Unlike previous research relying on archival data, we prospectively gathered fresh responses from 80 diverse LLMs on a balanced, 1,100-question USMLE-aligned benchmark. Using one unidimensional two-parameter logistic IRT model per topic, we estimate LLM's latent model ability jointly with question difficulty and discrimination, yielding more stable and nuanced performance rankings than accuracy alone. Notably, we identify distinctive ``spiky'' ability profiles, where overall rankings can be misleading due to highly specialized model abilities. While \texttt{GPT-5} was the top performer in a majority of domains (8 of 11), it was outperformed in Social Science and Communication by \texttt{Claude-3-opus}, demonstrating that even an overall 23rd-ranked model can hold the top spot for specific competencies. Furthermore, we demonstrate IRT's utility in auditing benchmarks by identifying flawed questions. We synthesize these findings into a practical decision-support framework that integrates our multi-factor competency profiles with operational metrics. This work establishes a robust, psychometrically grounded methodology essential for the safe, effective, and trustworthy deployment of LLMs in healthcare.