Task Vectors, Learned Not Extracted: Performance Gains and Mechanistic Insight
作者: Haolin Yang, Hakaze Cho, Kaize Ding, Naoya Inoue
分类: cs.CL
发布日期: 2025-09-29
备注: 48 pages, 95 figures, 17 tables
💡 一句话要点
提出可学习任务向量(LTV),提升ICL性能并提供机制性理解
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 任务向量 可学习任务向量 机制分析 大型语言模型
📋 核心要点
- 现有方法提取任务向量(TVs)繁琐且不透明,难以理解其影响计算的机制。
- 提出直接训练可学习任务向量(LTVs),无需提取,提升了准确性和灵活性。
- 分析表明,LTVs主要通过注意力头OV电路引导预测,且传播过程具有线性特性。
📝 摘要(中文)
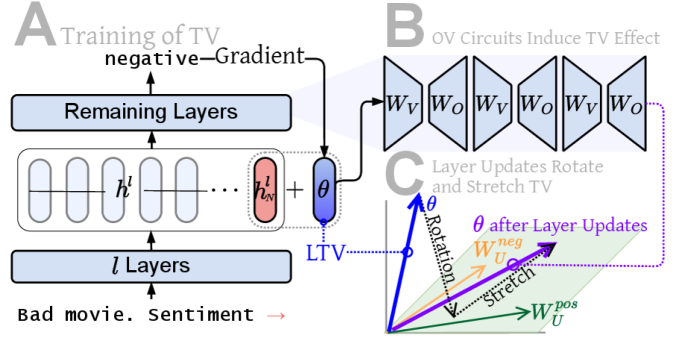
大型语言模型(LLM)可以通过上下文演示执行新任务,这种现象被称为上下文学习(ICL)。最近的研究表明,这些演示被压缩成任务向量(TVs),这是一种紧凑的任务表示,LLM利用它进行预测。然而,先前的研究通常使用繁琐且不透明的方法从模型输出或隐藏状态中提取TVs,并且很少阐明TVs影响计算的机制。在这项工作中,我们解决了这两个限制。首先,我们提出直接训练可学习任务向量(LTVs),它在准确性方面超过了提取的TVs,并表现出卓越的灵活性——在任意层、位置甚至使用ICL提示时都能有效地工作。其次,通过系统分析,我们研究了TVs的机制作用,表明在低层次上,它们主要通过注意力头OV电路来引导预测,其中一小部分“关键头”最具决定性。在更高层次上,我们发现尽管存在Transformer非线性,但TV传播在很大程度上是线性的:早期的TVs被旋转到任务相关的子空间,以改善相关标签的logits,而后期的TVs主要在幅度上进行缩放。总而言之,LTVs不仅提供了一种获得有效TVs的实用方法,而且还为ICL的机制基础提供了一个有原则的视角。
🔬 方法详解
问题定义:现有研究依赖于从预训练语言模型的输出或隐藏层状态中提取任务向量(TVs),以理解上下文学习(ICL)的机制。然而,这些提取方法通常复杂且缺乏透明度,难以洞察TVs如何影响模型的计算过程。此外,提取的TVs在灵活性方面存在局限性,例如难以在模型的任意层或位置生效。
核心思路:本文的核心思路是直接训练可学习的任务向量(LTVs),而不是从预训练模型中提取。通过训练,LTVs能够更好地适应特定任务,并在模型的不同层和位置发挥作用。这种方法不仅提高了任务向量的性能,还为研究任务向量在模型中的作用机制提供了更清晰的视角。
技术框架:该研究主要包含两个阶段:LTV的训练和机制分析。在LTV训练阶段,研究人员设计了一种训练框架,允许LTVs在模型的不同层和位置注入信息。在机制分析阶段,他们通过系统地分析LTVs对模型行为的影响,特别是对注意力头和logits的影响,来理解LTVs的作用机制。
关键创新:最重要的创新点在于提出了可学习的任务向量(LTVs)的概念,并设计了一种直接训练LTVs的方法。与传统的提取方法相比,LTVs具有更高的准确性和灵活性,并且更容易进行机制分析。此外,该研究还揭示了LTVs在模型中的作用机制,例如通过注意力头OV电路引导预测,以及TV传播的线性特性。
关键设计:LTV的训练过程涉及设计合适的损失函数,以鼓励LTVs学习到任务相关的表示。研究人员可能使用了交叉熵损失或类似的损失函数,以优化LTVs的参数,使其能够提高模型在特定任务上的性能。此外,LTVs的注入位置和方式也是关键的设计因素,需要仔细选择以确保LTVs能够有效地影响模型的计算过程。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LTVs在准确性方面优于提取的TVs,并且具有更强的灵活性。LTVs可以在任意层、位置甚至使用ICL提示时都能有效地工作。机制分析表明,LTVs主要通过注意力头OV电路来引导预测,并且TV传播在很大程度上是线性的。
🎯 应用场景
该研究成果可应用于提升大型语言模型在各种任务上的上下文学习能力,例如Few-shot学习、零样本学习等。通过使用LTVs,可以更有效地引导模型完成新任务,减少对大量训练数据的依赖。此外,该研究对理解ICL的机制具有重要意义,有助于开发更高效、更可控的语言模型。
📄 摘要(原文)
Large Language Models (LLMs) can perform new tasks from in-context demonstrations, a phenomenon known as in-context learning (ICL). Recent work suggests that these demonstrations are compressed into task vectors (TVs), compact task representations that LLMs exploit for predictions. However, prior studies typically extract TVs from model outputs or hidden states using cumbersome and opaque methods, and they rarely elucidate the mechanisms by which TVs influence computation. In this work, we address both limitations. First, we propose directly training Learned Task Vectors (LTVs), which surpass extracted TVs in accuracy and exhibit superior flexibility-acting effectively at arbitrary layers, positions, and even with ICL prompts. Second, through systematic analysis, we investigate the mechanistic role of TVs, showing that at the low level they steer predictions primarily through attention-head OV circuits, with a small subset of "key heads" most decisive. At a higher level, we find that despite Transformer nonlinearities, TV propagation is largely linear: early TVs are rotated toward task-relevant subspaces to improve logits of relevant labels, while later TVs are predominantly scaled in magnitude. Taken together, LTVs not only provide a practical approach for obtaining effective TVs but also offer a principled lens into the mechanistic foundations of ICL.