DiffuSpec: Unlocking Diffusion Language Models for Speculative Decoding
作者: Guanghao Li, Zhihui Fu, Min Fang, Qibin Zhao, Ming Tang, Chun Yuan, Jun Wang
分类: cs.CL, cs.AI
发布日期: 2025-09-28
💡 一句话要点
DiffuSpec:利用扩散语言模型解锁推测解码,显著提升LLM推理速度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推测解码 扩散语言模型 大型语言模型 推理加速 因果一致性 自适应草案长度 并行计算
📋 核心要点
- 现有推测解码方法依赖自回归起草器,推理速度受限于串行计算,成为性能瓶颈。
- DiffuSpec利用预训练扩散语言模型一次性生成多token草案,无需训练,兼容现有自回归验证器。
- DiffuSpec通过因果一致性路径搜索和自适应草案长度控制,在多个基准测试中实现了高达3倍的加速。
📝 摘要(中文)
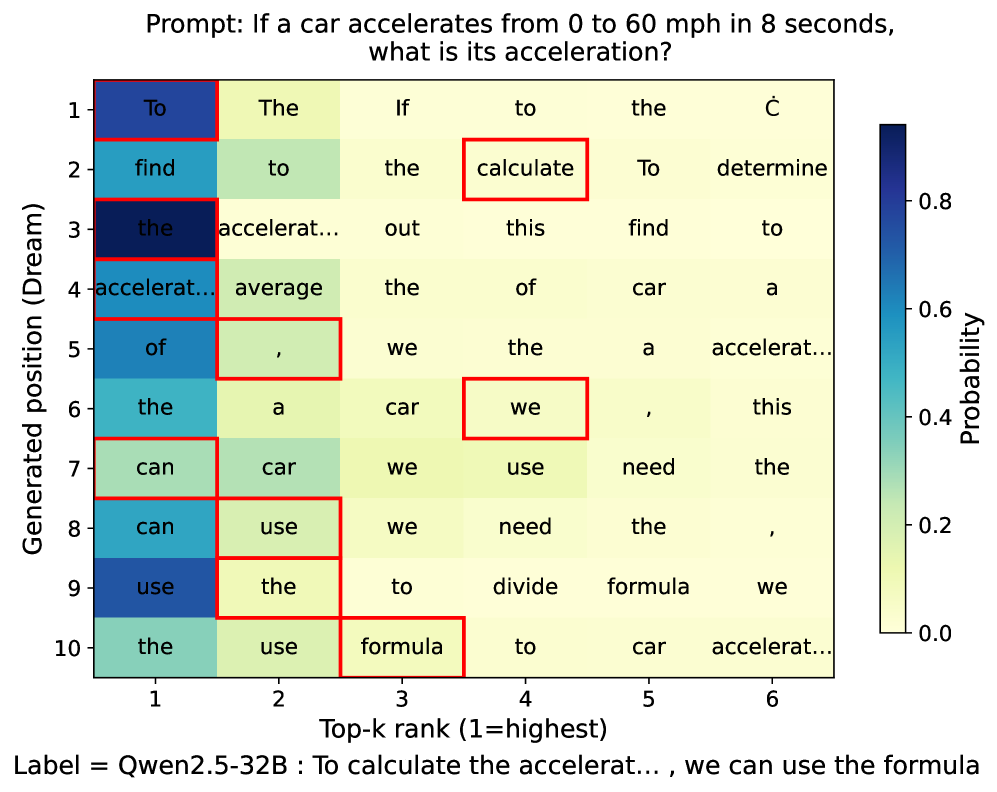
随着大型语言模型(LLMs)规模的扩大,准确性得到了提高,但自回归(AR)解码的性质增加了延迟,因为每个token都需要串行前向传递。推测解码通过使用快速起草器来提出多token草案来解决这个问题,然后由目标模型并行验证。然而,许多部署仍然依赖于AR起草器,其中顺序传递限制了实际收益。我们重新审视了起草阶段,并提出了DiffuSpec,这是一个无需训练的即插即用框架,它使用预训练的扩散语言模型(DLM)在单个前向传递中生成多token草案,同时保持与标准AR验证器的兼容性。由于DLM草案是在双向条件下生成的,因此并行的每位置候选形成一个token格,其中每个位置的局部最高概率token不需要形成因果的从左到右的路径。此外,DLM起草需要预先指定草案长度,从而导致速度-质量的权衡。为了解决这些挑战,我们引入了两个实用的组件:(i)对该格子的因果一致性路径搜索(CPS),它提取与AR验证对齐的从左到右的路径;(ii)自适应草案长度(ADL)控制器,它根据最近的接受反馈和实现的生成长度来调整下一个提议大小。在各个基准测试中,DiffuSpec产生了高达3倍的实际加速,从而确立了基于扩散的起草作为推测解码的自回归起草器的强大替代方案。
🔬 方法详解
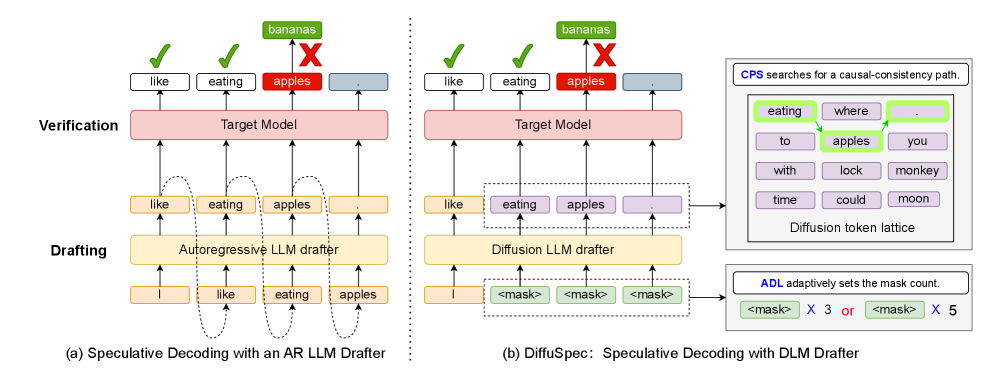
问题定义:现有推测解码方法中的起草器通常基于自回归模型,这意味着生成草案的过程仍然是串行的,限制了并行计算的优势,导致整体加速效果不佳。此外,确定合适的草案长度也是一个挑战,过短则加速不明显,过长则容易被拒绝,影响效率。
核心思路:DiffuSpec的核心思路是利用扩散语言模型(DLM)的双向生成能力,一次性生成多个token的草案,从而避免了自回归模型的串行生成过程。通过将DLM生成的token视为一个token格,并在其中搜索因果一致的路径,可以得到一个有效的草案。同时,通过自适应地调整草案长度,可以在速度和质量之间取得平衡。
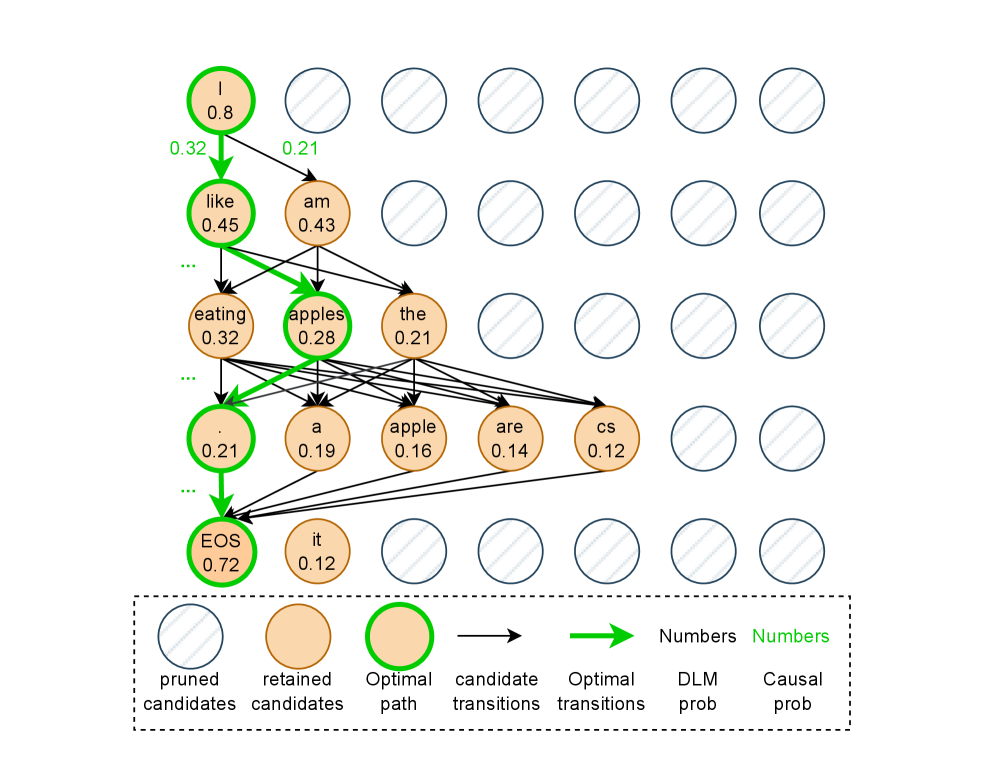
技术框架:DiffuSpec主要包含两个核心模块:1) 基于扩散语言模型的草案生成器:使用预训练的DLM,输入上下文信息,生成一个多token的候选格。2) 因果一致性路径搜索(CPS):在候选格中搜索一条从左到右的因果一致路径,作为最终的草案。3) 自适应草案长度(ADL)控制器:根据验证器的反馈(接受/拒绝)动态调整下一个草案的长度。整体流程是:首先,ADL控制器确定草案长度;然后,DLM生成器生成草案;接着,CPS搜索因果一致路径;最后,自回归验证器验证草案,并根据结果更新ADL控制器。
关键创新:DiffuSpec的关键创新在于将扩散语言模型引入到推测解码的起草阶段。与传统的自回归起草器相比,DLM可以并行生成多个token,从而显著提高生成速度。此外,CPS算法解决了DLM生成的token格中可能存在的因果不一致问题,保证了草案的有效性。ADL控制器则实现了草案长度的自适应调整,进一步优化了速度和质量之间的平衡。
关键设计:CPS算法采用动态规划方法,在token格中搜索最优的因果一致路径。ADL控制器根据最近的接受率和已生成的token数量,动态调整下一个草案的长度。具体来说,如果接受率较高,则增加草案长度;如果接受率较低,则减小草案长度。DLM采用标准的扩散模型架构,并使用预训练的语言模型进行初始化。
🖼️ 关键图片
📊 实验亮点
DiffuSpec在多个基准测试中取得了显著的加速效果,最高可达3倍。实验结果表明,DiffuSpec在保证生成质量的前提下,能够有效提高大型语言模型的推理速度,优于传统的自回归起草器。自适应草案长度控制策略能够根据验证器的反馈动态调整草案长度,进一步优化了速度和质量之间的平衡。
🎯 应用场景
DiffuSpec可应用于各种需要加速大型语言模型推理的场景,例如在线对话系统、机器翻译、文本摘要等。通过显著提高推理速度,DiffuSpec可以降低延迟,提升用户体验,并降低计算成本。该研究为探索扩散模型在加速语言模型推理方面的应用提供了新的思路。
📄 摘要(原文)
As large language models (LLMs) scale up, accuracy improves, but the autoregressive (AR) nature of decoding increases latency since each token requires a serial forward pass. Speculative decoding addresses this by employing a fast drafter to propose multi-token drafts, which are then verified in parallel by the target model. However, many deployments still rely on AR drafters, where sequential passes limit wall-clock gains. We revisit the drafting stage and present DiffuSpec, a training-free drop-in framework that uses a pretrained diffusion language model (DLM) to produce multi-token drafts in a single forward pass, while remaining compatible with standard AR verifiers. Because DLM drafts are generated under bidirectional conditioning, parallel per-position candidates form a token lattice in which the locally highest-probability token at each position need not form a causal left-to-right path. Moreover, DLM drafting requires pre-specifying a draft length, inducing a speed-quality trade-off. To address these challenges, we introduce two practical components: (i) a causal-consistency path search (CPS) over this lattice that extracts a left-to-right path aligned with AR verification; and (ii) an adaptive draft-length (ADL) controller that adjusts next proposal size based on recent acceptance feedback and realized generated length. Across benchmarks, DiffuSpec yields up to 3x wall-clock speedup, establishing diffusion-based drafting as a robust alternative to autoregressive drafters for speculative decoding.